Meet Med-PaLM: A Large Language Model Supporting the Medical Domain in Providing Safe and Helpful Answers
Language facilitates crucial interactions for and between physicians, researchers, and patients in the compassionate field of medicine. But the use of language by current AI models for healthcare and medical applications has mostly fallen short of expectations. Although useful, these models lack expressivity and interactive capabilities and are primarily single-task systems. Because of this, there is a gap between what current models are capable of and what they might expect in actual clinical operations.
Rethinking AI systems using language as a tool for mediating human-AI interaction is now possible because of recent developments in large language models (LLMs). LLMs are sizable pre-trained AI systems that can be easily applied to various applications and domains. The capacity of these expressive and interactive models to acquire generally usable representations from the knowledge embodied in medical corpora, at scale, shows considerable promise.
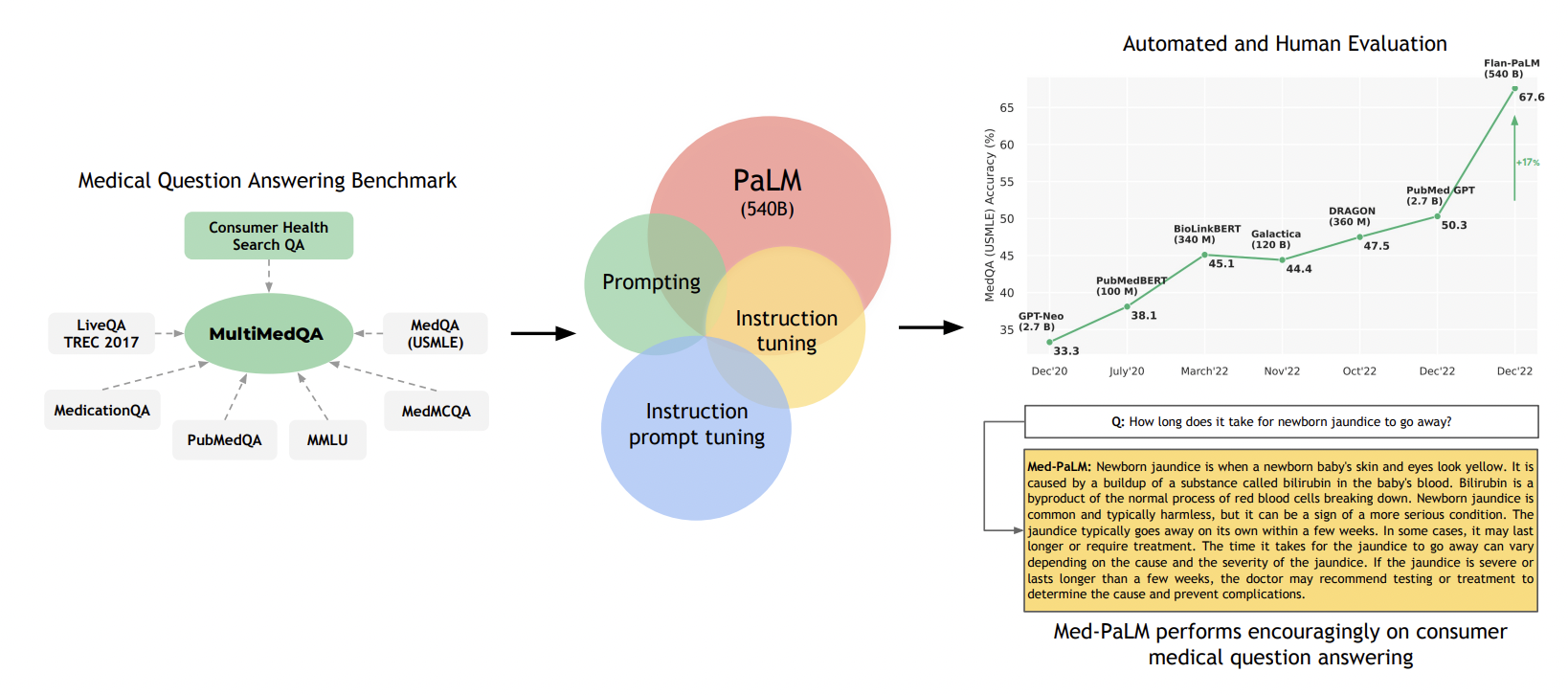
The quality requirements of models for medical purposes are high. So the scientists at Deepminds and Google research came up with a large language model named Med-PaLM. Through the transmission of diverse datasets, Med-PaLM addresses multiple-choice questions and queries from medical professionals and non-professionals. MedicationQA, MedQA, PubMedQA, LiveQA, MedMCQA, and MMLU are the sources of these datasets. To enhance MultiMedQA, a new dataset called HealthSearchQA comprising curated, commonly searched medical queries was also included.

The dataset for HealthsearchQA contains 3375 commonly asked questions from users. It was gathered using seed medical diagnoses and the symptoms that went along with them. To analyze LLMs using MultiMedQA, this model was created using the 540 billion parameters LLM PaLM and its instruction-tuned variant Flan-PaLM.
The scientists concentrated on answering medical questions in order to evaluate the potential of LLMs in medicine. Reading comprehension abilities, the capacity to accurately retain medical information and the manipulation of expert knowledge are necessary for responding to medical queries. There is a wealth of high-quality and quantity medical knowledge. The scope of the field of medical knowledge is only partially covered by the existing benchmarks, which are intrinsically constrained. However, using various datasets for answering medical questions allows for a more thorough assessment of LLM knowledge than multiple-choice accuracy or metrics for natural language generation like BLEU.

According to current claims, Med-PaLM performs very well, especially compared to Flan-PaLM. It must still outperform the judgment of a human medical professional. Currently, a team of medical experts found that 92.6 percent of the Med-PaLM responses matched the answers provided by clinicians.
This is remarkable, considering that only 61.9 percent of the long-form Flan-PaLM responses were found to be consistent with physician evaluations. Compared to 6.5 percent of answers created by clinicians and 29.7 percent of Flan-PaLM answers, just 5.8 percent of Med-PaLM answers were thought to be possibly harmful. Thus, Med-PaLM responses are significantly safer.
Med-PaLM has improved the accuracy of the model compared to the other model, which is a great plus point. The interesting discussion will be how these models can become a full trustable and reliable support for physicians and other medical experts.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
I am an undergraduate student at IIIT HYDERABAD pursuing Btech in computer science and MS in Computational Humanities. I am interested in Machine and Data learning. I am also actively involved in research on AI solutions for road safety.
Credit: Source link
Comments are closed.