Meet Medusa: An Efficient Machine Learning Framework for Accelerating Large Language Models (LLMs) Inference with Multiple Decoding Heads
The most recent advancement in the field of Artificial Intelligence (AI), i.e., Large Language Models (LLMs), has demonstrated some great improvement in language production. With model sizes reaching billions of parameters, these models are stepping into every domain, ranging from healthcare and finance to education.
Though these models have shown amazing capabilities, the development of the model’s size has led to an increased inference latency, which poses a problem for real-world applications. Memory-bound operations represent the main bottleneck in LLM inference, as it is inefficient to transport all model parameters from High Bandwidth Memory (HBM) to the accelerator’s cache during auto-regressive decoding.
Researchers have been putting in efforts to find a solution to these limitations, one of which is to decrease the number of decoding steps and increase the arithmetic intensity of the decoding process. Using a smaller draft model for speculative decoding, which produces a series of tokens that are then improved upon by the bigger original model, has been suggested. However, there are difficulties with incorporating a draft model into a distributed system.
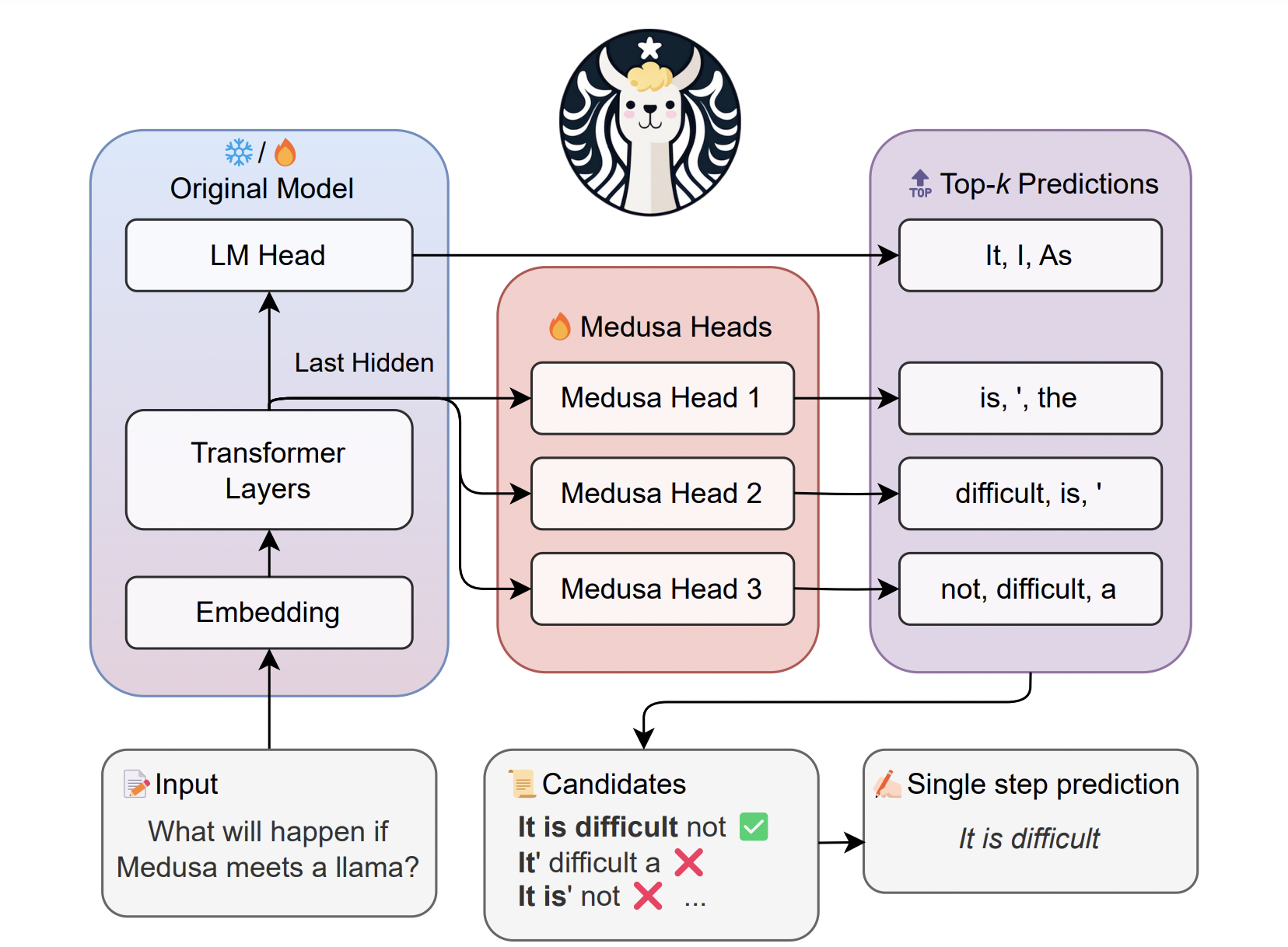
To overcome these challenges, a team of researchers in a recent study has presented MEDUSA, an efficient approach that enhances LLM inference by incorporating additional decoding heads to predict multiple subsequent tokens in parallel. It uses the backbone model’s numerous decoding heads to speed up inference. These heads overcome the difficulties of speculative decoding by simultaneously predicting numerous tokens.
MEDUSA doesn’t require a separate draft model like speculative decoding requires, which makes it capable of getting easily integrated into current LLM systems, even in dispersed situations. The team has shared that MEDUSA builds several candidate continuations in each decoding phase and verifies them concurrently using a tree-based attention mechanism. By utilizing parallel processing, MEDUSA lowers the number of necessary decoding steps while introducing very little overhead in terms of single-step latency.
Two new insights have been added to MEDUSA. First, numerous candidate continuations have been generated using MEDUSA heads, and they have been verified simultaneously. Secondly, an acceptance procedure has been used to choose suitable candidates. The team has shared the rejection sampling strategy used in speculative decoding, which a temperature-based threshold can effectively substitute to handle deviations.
The study has suggested two methods for fine-tuning LLMs’ predictive MEDUSA heads, which are as follows.
- MEDUSA-1: This allows lossless inference acceleration by directly fine-tuning MEDUSA on top of a frozen backbone LLM. MEDUSA-1 has been suggested to be used when incorporating MEDUSA into an existing model or in settings with limited computational resources. It uses less memory and can be made even more efficient by applying quantization techniques.
- MEDUSA-2: This method adjusts MEDUSA and the main LLM simultaneously. While it offers a greater speedup and improved prediction accuracy for MEDUSA heads, it necessitates a unique training recipe to maintain the backbone model’s functionality. MEDUSA-2 is appropriate when resources are plentiful and permits simultaneous training of MEDUSA heads and the backbone model without sacrificing output quality or next-token prediction ability.
The research has also suggested several additions to enhance or broaden the use of MEDUSA. These include a usual acceptance scheme to increase the acceptance rate without sacrificing generation quality and a self-distillation method in the absence of training data. The team has shared that the evaluation process of MEDUSA included testing on models of different sizes and training protocols. The results have demonstrated that MEDUSA-1 can accelerate data by more than 2.2 times without sacrificing generation quality. Moreover, the acceleration is improved to 2.3-3.6× using MEDUSA-2.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.