Meet Meta AI’s ‘ESMFold,’ An Artificial Intelligence-Based Model That Predicts Protein Structure 6x Faster Than AlphaFold2
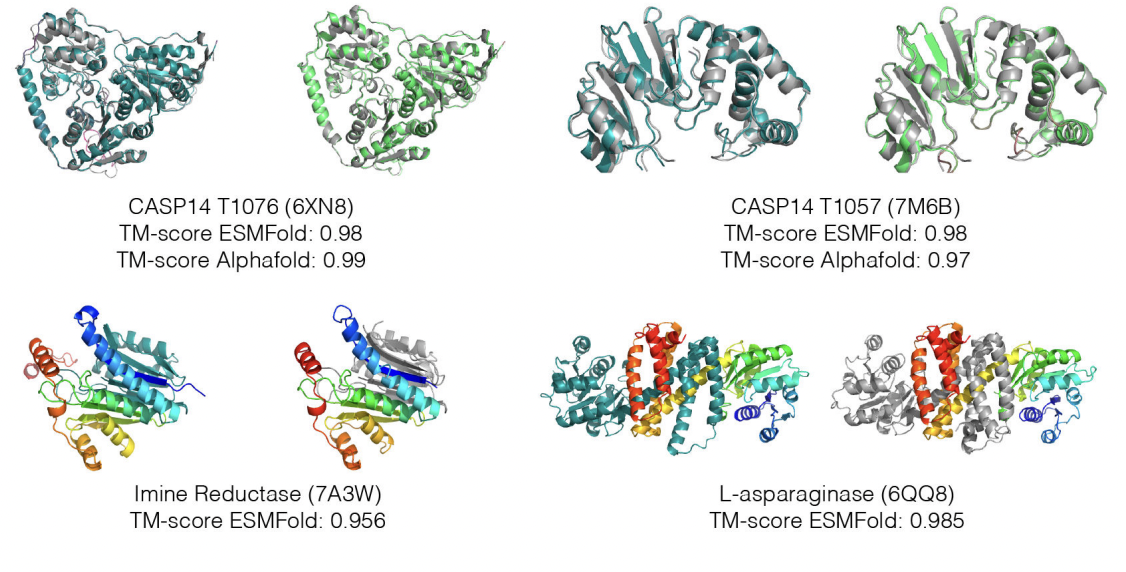
Recent research has demonstrated that large language models can evolve with scale, moving beyond simple pattern matching to do higher-level reasoning and produce realistic visuals and text. There has been some research on language models trained on protein sequences, but when they are scaled up, little is known about what they learn about biology. Researchers at Meta AI have developed one of the most significant language models of protein to date, ESMFold, that can predict protein structure from a gene sequence. With an order-of-magnitude faster inference time, ESMFold, based on a 15B parameter Transformer model, delivers accuracy comparable to other state-of-the-art models. The paper describing the model and several tests carried out as part of this study have also been published on bioRxiv. ESMFold uses a Transformer-based language model called ESM-2 in contrast to other models like AlphaFold2, which rely on external databases of sequence alignments. The Evolutionary Scale Modeling (ESM) model, which learns the relationships between pairs of amino acids in a protein sequence, is being updated by this model. This makes ESMFold 6 times faster than AlphaFold2 at predicting protein structure. The Meta team used ESMFold to estimate the structure of one million protein sequences quickly.
DNA’s genetic coding serves as a “recipe” for assembling amino acid sequences into protein molecules. The proteins produced from these linear sequences are folded into intricate 3D structures essential to their biological function. Traditional experimental techniques might take years to complete and require expensive, specialized equipment to determine protein structure. The 50-year-old problem of quickly and reliably predicting protein structure from the amino acid sequence was finally resolved by DeepMind’s AlphaFold2 in late 2020. AlphaFold2 receives multiple sequence alignment (MSA) data in addition to the raw amino acid sequence; this external database slows down performance. MSA links various sequences based on the notion that they share an evolutionary ancestor.
Meta and other groups have studied how language models may be used in genomics for many years. InfoQ featured Google’s BigBird language model in 2020 as it achieved better performance on two genomics classification tasks than baseline algorithms. They also highlighted Meta’s initial open-source ESM language model for calculating a protein sequence embedding representation in the same year. InfoQ had also reported DeepMind’s AlphaFold2, and they have now also announced the release of AlphaFold2’s predictions of structures “for nearly all cataloged proteins known to science.”. The researchers also held a Twitter Q&A where the public received answers to inquiries like the model’s maximum input sequence length. Although Meta has not yet made ESMFold open-source, it hopes to do so soon to aid in the advancement of research that the community can do.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Language models of protein sequences at the scale of evolution enable accurate structure prediction'. All Credit For This Research Goes To Researchers on This Project. Check out the Preprint/Under review paper and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.