Meet MOAT: An Artificial Intelligence (AI) Model that Combines Convolution and Attention Operations to Achieve Powerful Vision Models
The computer vision domain has seen significant advancement in recent years thanks to the prevalence of self-attention. Self-attention modules have proved to be extremely useful in natural language processing, and that was the spark to start working on transferring them to the computer vision domain. It was the vision transformers (ViT) that first introduced them successfully to computer vision while outperforming state-of-the-art solutions.
Vision transformers have extremely high representation capacity thanks to the global receptive fields. However, this advantage comes with a huge cost of dependency to be trained on large-scale datasets. If you train them with a small dataset, they struggle to achieve successful performance, contrary to their convolutional counterparts.
Speaking of convolutional networks, they have been the backbone of the computer vision domain in the last decade. The successful introduction of AlexNet, which outperformed all traditional methods by a margin in the object classification task, started the era of convolutional neural networks.
Years of dominance by convolutional networks have brought multiple studies to improve their performances. Researchers have come up with design experiences, training principles, and many more simple tricks to boost the performance and efficiency of convolutional networks. This collective experience is so valuable that recent studies focused on transferring them to vision transformers.
Combining the best of both worlds, transformers and convolutional networks have led to recent successful architectures such as MobileViT and CoAtNet. These two approaches demonstrated stacking transformer, and mobile convolution blocks lead to significant performance. These studies focused on macro-level network design and studied the effect of stacking existing blocks.
Despite the successful results, none of the previous works focused on micro-level building block design. One might ask, what if we study the blocks of mobile convolution and transformers and utilize them better? Well, that one was Google, and they came up with MOAT.
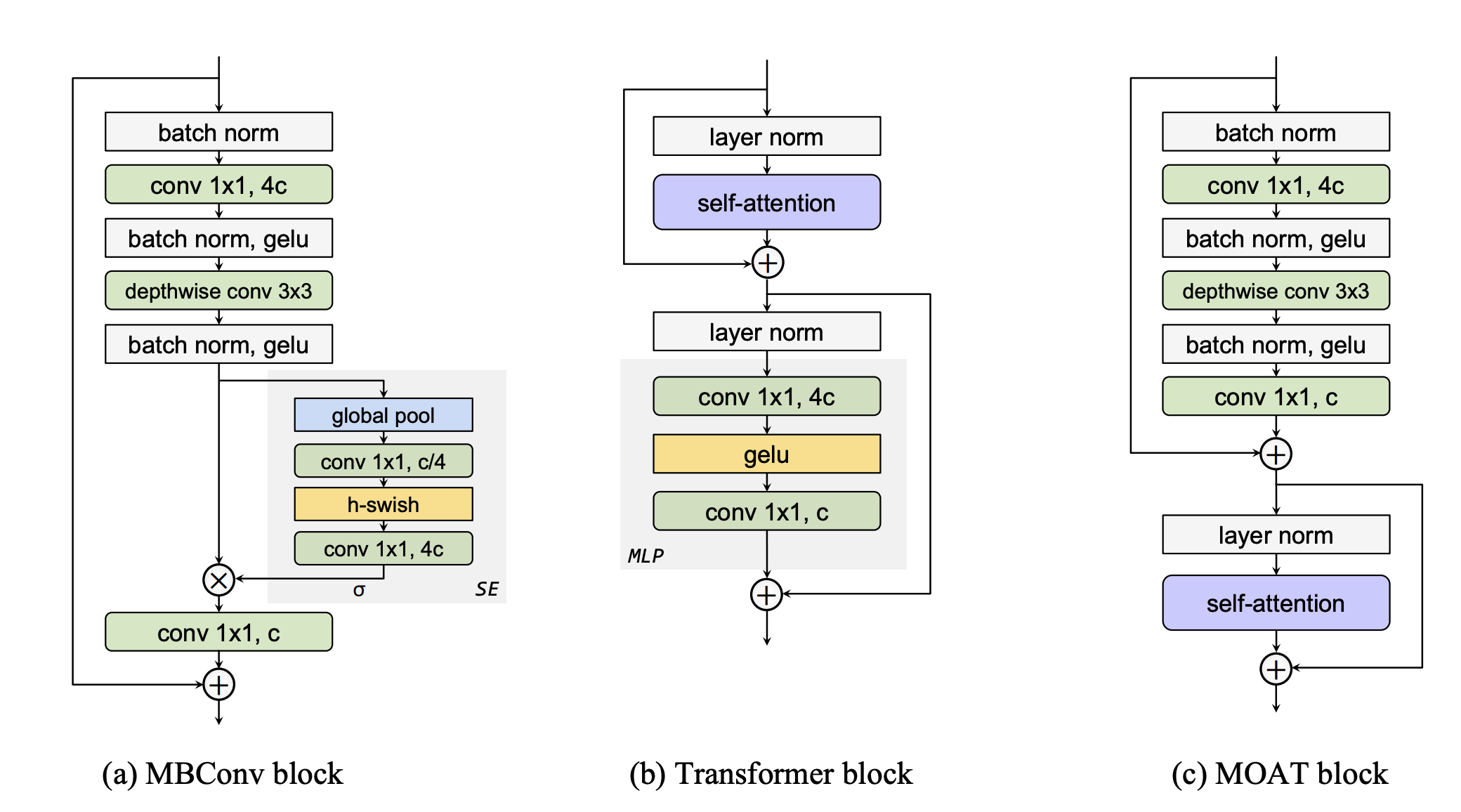
The Multi-layer perceptron (MLP) module in the transformer block is similar to the mobile convolution one. Both of them carry an inverted bottleneck design. The difference is, in mobile convolution, 3 x 3 depthwise convolution is applied as extra, which makes it a more powerful operation when we consider the additional activation and normalization operations between the layers.
On the other hand, extracting multi-scale features using transformer blocks is a bit tricky. Usually, this is done by applying average pooling to the input features before they are passed to the self-attention layer. This approach works, but the pooling operation reduces the representation capacity.
So, there are both good and bad sides of transformer and mobile convolution blocks. What happens if we eliminate the cons and combine the pros of these two blocks? The answer is MOAT.
MOAT (Mobile convolution with attention) block combines mobile convolution and transformer blocks efficiently. It first modifies the transformer block by replacing the MLP with a mobile convolution block. This replacement enables higher representation capacity in the network. Moreover, the order of attention is reversed in the mobile convolution block so that the downsampling operation can be done via a strided depthwise convolution operation within the mobile convolution block, thus, leading to a better downsampling kernel.
By simply changing the global attention to non-overlapping local window attention, MOAT can be easily deployed to downstream activities that demand large resolution inputs. MOAT shows superior results on object detection tasks.
In conclusion, MOAT supports the simple design principle. The suggested MOAT block skillfully redesigns the strengths of both mobile convolution and self-attention into one block without inventing any additional complex procedures.
Check out the Paper and Github. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.