Meet MouSi: A Novel PolyVisual System that Closely Mirrors the Complex and Multi-Dimensional Nature of Biological Visual Processing
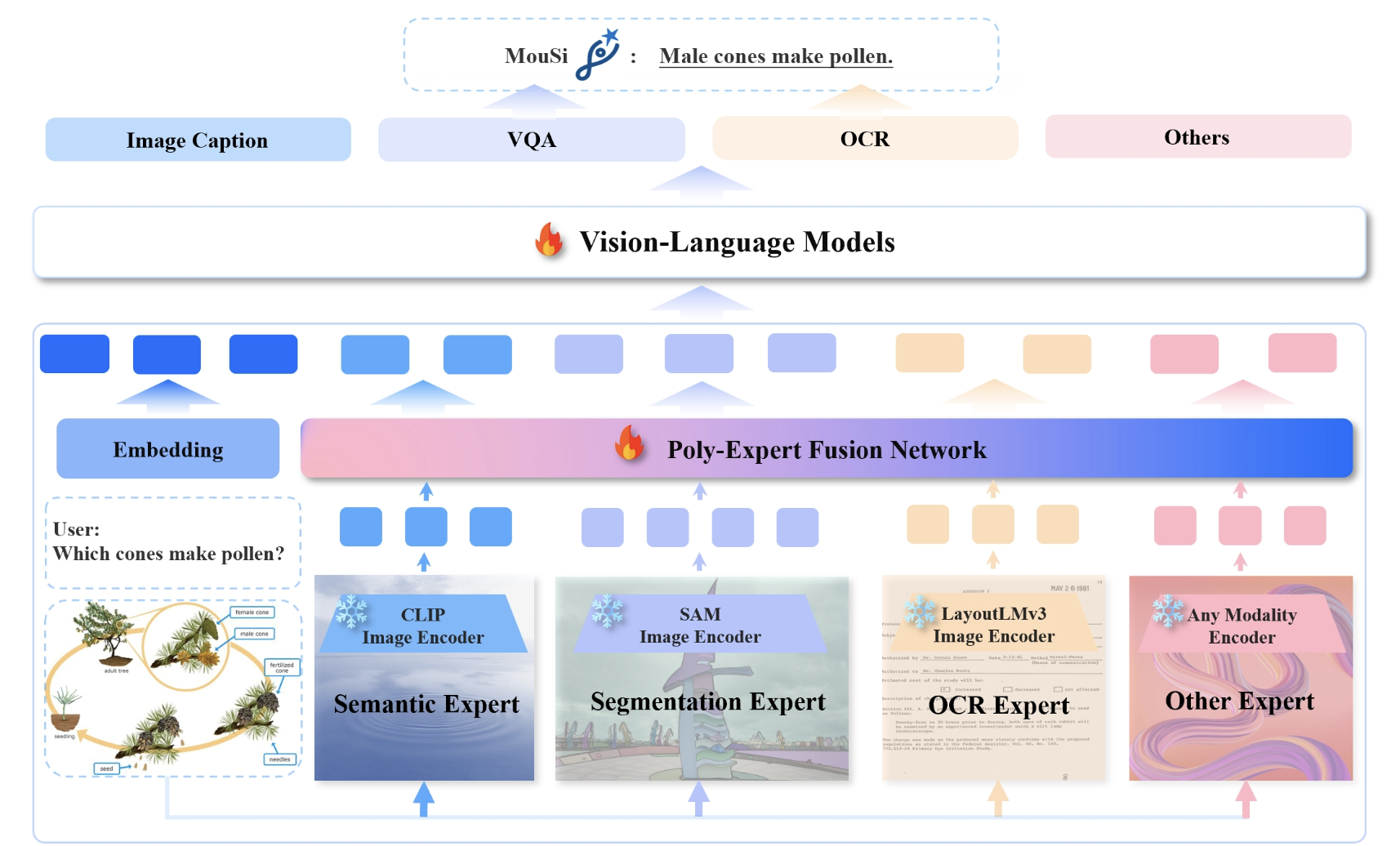
Current challenges faced by large vision-language models (VLMs) include limitations in the capabilities of individual visual components and issues arising from excessively long visual tokens. These challenges pose constraints on the model’s ability to accurately interpret complex visual information and lengthy contextual details. Recognizing the importance of overcoming these hurdles for improved performance and versatility, this paper introduces a novel approach!
The proposed solution involves leveraging ensemble expert techniques to synergize the strengths of individual visual encoders, encompassing skills in image-text matching, OCR, and image segmentation, among others. This methodology incorporates a fusion network to harmonize the processing of outputs from diverse visual experts, effectively bridging the gap between image encoders and pre-trained language models (LLMs).
Numerous researchers have highlighted deficiencies in the CLIP encoder, citing challenges such as its inability to reliably capture basic spatial factors in images and its susceptibility to object hallucination. Given the diverse capabilities and limitations of various vision models, a pivotal question arises: How can one harness the strengths of multiple visual experts to synergistically enhance overall performance?
Inspired by biological systems, the approach taken here adopts a poly-visual-expert perspective, akin to the operation of the vertebrate visual system. In the pursuit of developing Vision-Language Models (VLMs) with poly-visual experts, three primary concerns come to the forefront:
- The effectiveness of poly-visual experts,
- Optimal integration of multiple experts and
- Prevention of exceeding the maximum length of Language Models (LLMs) with multiple visual experts.
A candidate pool comprising six renowned experts, including CLIP, DINOv2, LayoutLMv3, Convnext, SAM, and MAE, was constructed to assess the effectiveness of multiple visual experts in VLMs. Employing LLaVA-1.5 as the base setup, single-expert, double-expert, and triple-expert combinations were explored across eleven benchmarks. The results, as depicted in Figure 1, demonstrate that with an increasing number of visual experts, VLMs gain richer visual information (attributed to more visual channels), leading to an overall improvement in the upper limit of multimodal capability across various benchmarks.
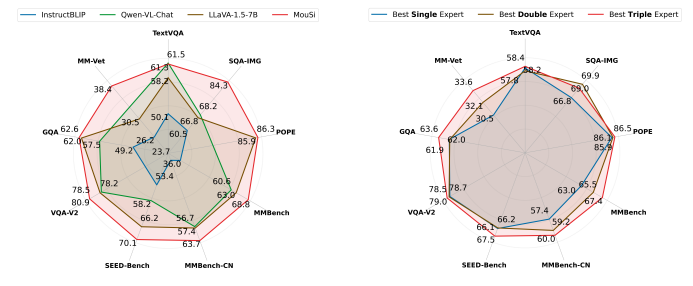
Left: Comparing InstructBLIP, Qwen-VL-Chat, and LLaVA-1.5-7B, poly-visual-expert MouSi achieves SoTA on a broad range of nine benchmarks. Right: Performances of the best models with different numbers of experts on nine benchmark datasets. Overall, triple experts are better than double experts, who in turn are better than a single expert.
Furthermore, the paper explores various positional encoding schemes aimed at mitigating issues associated with lengthy image feature sequences. This addresses concerns related to position overflow and length limitations. For instance, in the implemented technique, there is a substantial reduction in positional occupancy in models like SAM, from 4096 to a more efficient and manageable 64 or even down to 1.
Experimental results showcased the consistently superior performance of VLMs employing multiple experts compared to isolated visual encoders. The integration of additional experts marked a significant performance boost, highlighting the effectiveness of this approach in enhancing the capabilities of vision-language models. They have illustrated that the polyvisual approach significantly elevates the performance of Vision-Language Models (VLMs), surpassing the accuracy and depth of understanding achieved by existing models.
The demonstrated results align with the hypothesis that a cohesive assembly of expert encoders can indeed bring about a substantial enhancement in the capability of VLMs to handle intricate multimodal inputs. To wrap it up, the research shows that using different visual experts makes Vision-Language Models (VLMs) work better. It helps the models understand complex information more effectively. This not only fixes current issues but also makes VLMs stronger. In the future, this approach could change how we bring together vision and language!
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
Credit: Source link
Comments are closed.