Meet mPLUG-Owl2: A Multi-Modal Foundation Model that Transforms Multi-modal Large Language Models (MLLMs) with Modality Collaboration
Large Language Models, with their human-imitating capabilities, have taken the Artificial Intelligence community by storm. With exceptional text understanding and generation skills, models like GPT-3, LLaMA, GPT-4, and PaLM have gained a lot of attention and popularity. GPT-4, the recently launched model by OpenAI due to its multi-modal capabilities, has gathered everyone’s interest in the convergence of vision and language applications, as a result of which MLLMs (Multi-modal Large Language Models) have been developed. MLLMs have been introduced with the intention of improving them by adding visual problem-solving capabilities.
Researchers have been focussing on multi-modal learning, and previous studies have found that several modalities can work well together to improve performance on text and multi-modal tasks at the same time. The currently existing solutions, such as cross-modal alignment modules, limit the potential for modality collaboration. Large Language Models are fine-tuned during multi-modal instruction, which leads to a compromise of text task performance that comes off as a big challenge.
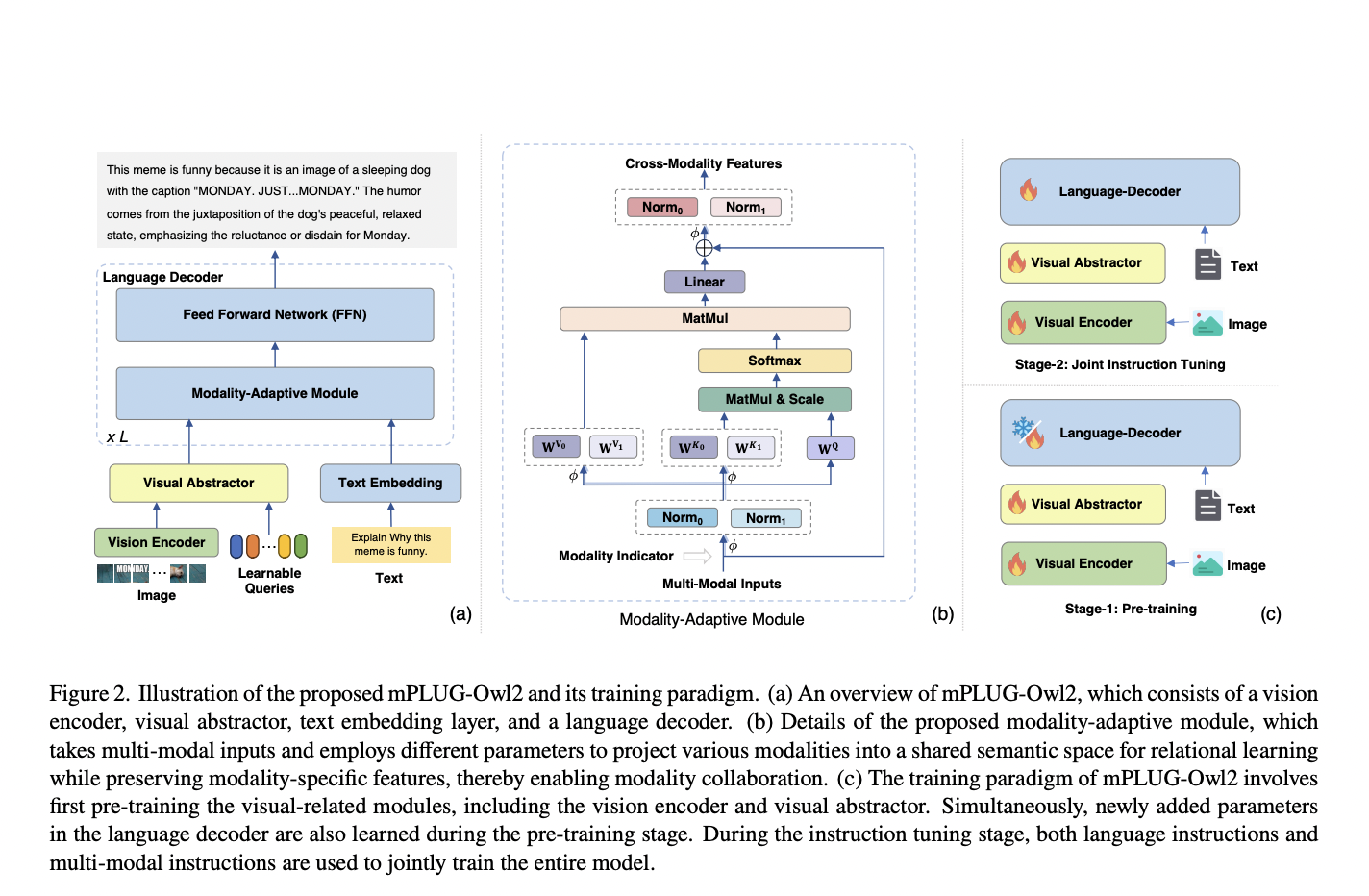
To address all these challenges, a team of researchers from Alibaba Group has proposed a new multi-modal foundation model called mPLUG-Owl2. The modularized network architecture of mPLUG-Owl2 takes interference and modality cooperation into account. This model combines the common functional modules to encourage cross-modal cooperation and a modality-adaptive module to transition between various modalities seamlessly. By doing this, it utilizes a language decoder as a universal interface.
This modality-adaptive module guarantees cooperation between the two modalities by projecting the verbal and visual modalities into a common semantic space while maintaining modality-specific characteristics. The team has presented a two-stage training paradigm for mPLUG-Owl2 that consists of joint vision-language instruction tuning and vision-language pre-training. With the help of this paradigm, the vision encoder has been made to collect both high-level and low-level semantic visual information more efficiently.
The team has conducted various evaluations and has demonstrated mPLUG-Owl2’s ability to generalize to text problems and multi-modal activities. The model demonstrates its versatility as a single generic model by achieving state-of-the-art performances in a variety of tasks. The studies have shown that mPLUG-Owl2 is unique as it is the first MLLM model to show modality collaboration in scenarios including both pure-text and multiple modalities.
In conclusion, mPLUG-Owl2 is definitely a major advancement and a big step forward in the area of Multi-modal Large Language Models. In contrast to earlier approaches that primarily concentrated on enhancing multi-modal skills, mPLUG-Owl2 emphasizes the synergy between modalities to improve performance across a wider range of tasks. The model makes use of a modularized network architecture, in which the language decoder acts as a general-purpose interface for controlling various modalities.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.