Meet Multimodal C4: An Open, Billion-Scale Corpus of Images Interleaved with Text
Sequence models may adapt to new tasks without parameter updates because of in-context learning. Few-shot learning can be presented as a next-token prediction task by interspersing a few supervised instances in a prompt, where x1, y1, x2, y2,…, xn is input to predict yn. By combining pictures and text, certain image+text models also offer in-context learning. Prior research indicates that effective multimodal in-context learning requires pretraining on sequences of pictures and text that are similarly interleaved (rather than just a single image/caption combination). However, a corpus of this size has yet to be available to the general public.
Researchers from the University of California, Santa Barbara, Allen Institute for Artificial Intelligence, Paul G. Allen School of Computer Science, University of Washington, Columbia University, Yonsei University and LAION provide Multimodal C4 (mmc4), a public, billion-scale image-text collection made up of interlaced image/text sequences, to address the problem. Public webpages for the cleaned English c4 corpus are utilized to generate mmc4. They treat each document as a bipartite linear assignment problem, with sentences being assigned to images (under the constraint that each sentence is assigned at most one image) and the usual preprocessing procedures like deduplication, NSFW removal, etc. They also insert images into sequences of penalties by treating each document as an instance of a bipartite linear assignment problem.
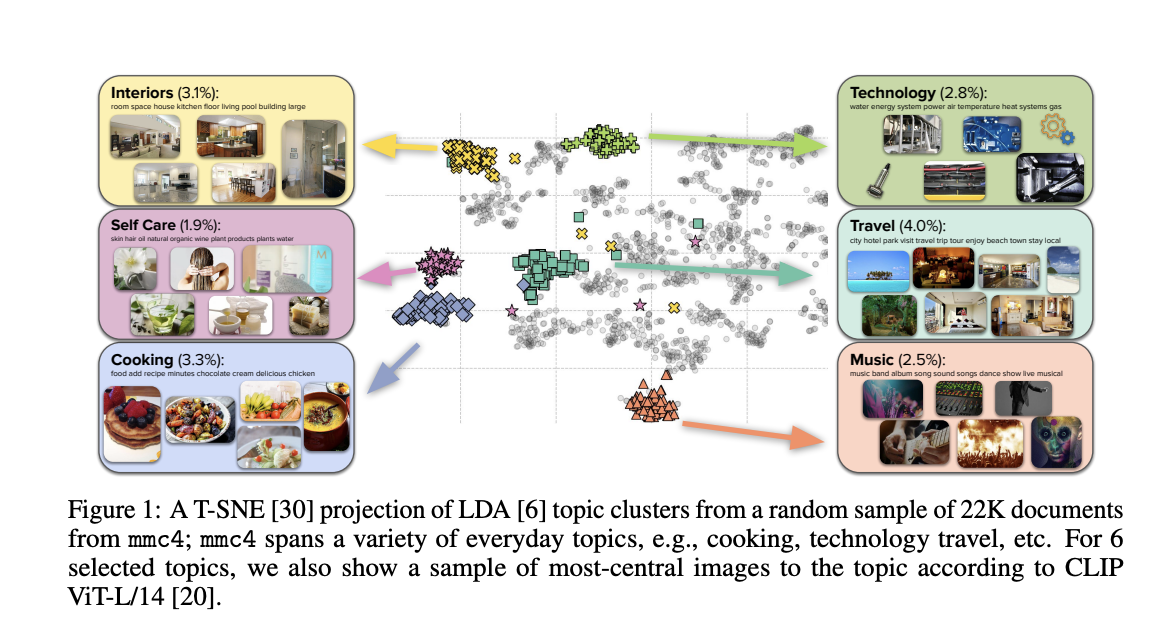
They first show that utilizing CLIP ViT-L/14 to estimate bipartite weights in a zero-shot technique results in state-of-the-art performance on intra-document alignment benchmarks, which is used to construct mmc4. They discuss mmc4, noting that: 1) the text and images cover expected common topics like cooking and travel; 2) filters like NSFW/ad removal work with high accuracy; and 3) the resulting images are pertinent to the associated documents and frequently, they are correctly aligned to the most pertinent individual sentence.
Before wrapping up, they explore the first use cases of mmc4, including OpenFlamingo3, an open-source Flamingo variant. They introduce mmc4, a corpus of 585M pictures from the well-known c4 dataset interspersed with 43B English tokens. According to preliminary results, training on the mmc4 sequences enables few-shot, in-context adaption to image captioning datasets. Comparatively speaking, models trained on single images/captions are less capable of performing multimodal in-context learning than models trained on image/text sequences from mmc4. They anticipate that interleaving will be crucial for few-shot understanding and for more varied multimodal language technologies where users may desire to interact with agents in novel ways while interacting with and discussing visual information.
Future research should focus on the following:
1. A more accurate empirical evaluation of in-context reasoning skills; are models capable of reasoning across pictures and texts in a prompt, or are they restricted to interleaved and separate supervised examples?
2. Data scaling: Is the availability of huge, interleaved corpora limiting in-context vision+language learning performance? Or is a better single-modal pretraining approach enough to free up multimodal models from bottlenecks?
3. Instruction tuning: Although interleaving separate supervised image+text examples permits in-context learning, training an instruction-following multimodal model specifically for this use is a viable alternative.
They have restricted access to their project. Thos who ant complete access to the project need to fill out a form on their GitHub page.
Check out the Paper and Github. Don’t forget to join our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.