Meet NExT-GPT: An End-to-End General-Purpose Any-to-Any Multimodal Large Language Models (MM-LLMs)
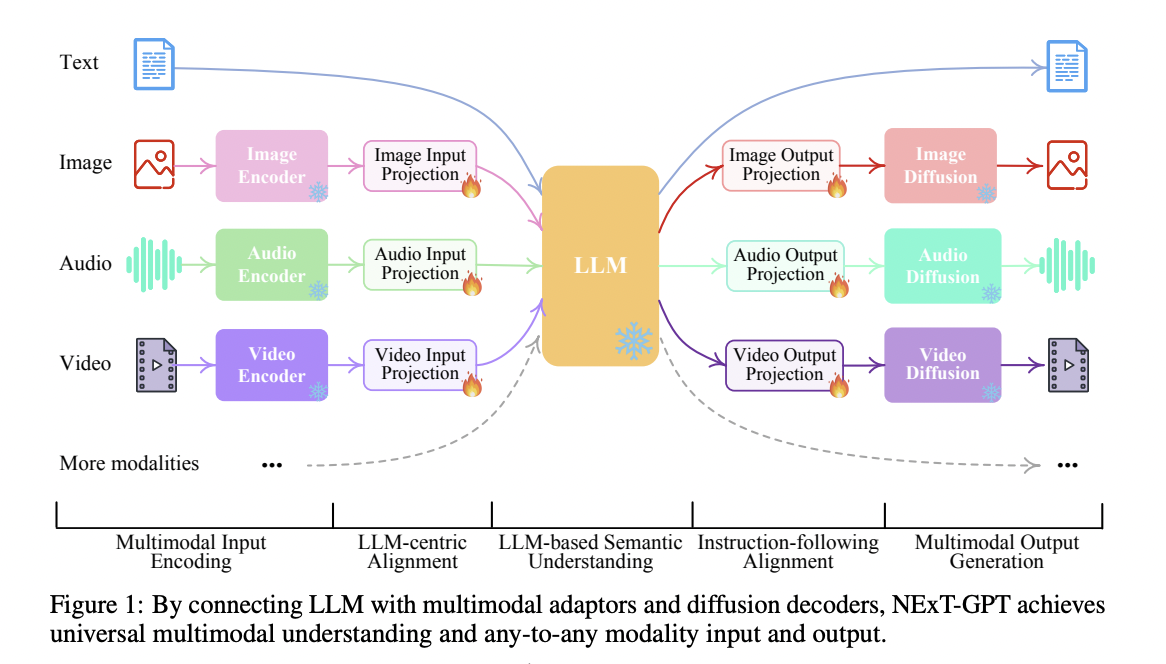
Multimodal LLMs can enhance human-computer interaction by enabling more natural and intuitive communication between users and AI systems through voice, text, and visual inputs. This can lead to more contextually relevant and comprehensive responses in applications like chatbots, virtual assistants, and content recommendation systems. They are built upon the foundations of traditional unimodal language models, like GPT-3, while incorporating additional capabilities to handle different data types.
However, multimodal LLMs may require a large amount of data to perform well, making them less sample-efficient than other AI models. Aligning data from different modalities during training can be challenging. Due to the lack of overall end-to-end training in error propagation, content understanding and multimodal generation capabilities can be very limited. As the information transfer between different modules is entirely based on discrete texts produced by the LLM, noise and errors are inevitable. Ensuring that the information from each modality is properly synchronized is essential for practical training.
To tackle these issues, the researchers at NeXT++, the School of Computing ( NUS ), built NexT-GPT. It is an any-to-any Multimodal LLM designed to handle input and output in any combination of text, image, video, and audio modalities. It enables the encoders to encode the inputs in various modalities, which are further projected onto the representations of the LLM.
Their method involves modifying the existing open-source LLM as the core to process input information. After projection, the produced multimodal signals with specific instructions are directed to different encoders, and finally, content is generated in corresponding modalities. Training their model from scratch is cost-effective, so they use the existing pre-trained high-performance encoders and decoders such as Q-Former, ImageBind, and the state-of-the-art latent diffusion models.
They introduced a lightweight alignment learning technique by which the LLM-centric alignment at the encoding side and the instruction-following alignment at the decoding side efficiently require minimal parameter adjustments for effective semantic alignment. They even introduce a modality-switching instruction tuning to empower their any-to-any MM-LLM with human-level capabilities. This will bridge the gap between the feature space of different modalities and ensure fluent semantics understanding of other inputs to perform alignment learning for NExT-GPT.
Modality-switching instruction tuning (MosIT) supports complex cross-modal understanding and reasoning and enables sophisticated multimodal content generation. They even constructed a high-quality dataset comprising a wide range of multimodal inputs and outputs, offering the necessary complexity and variability to facilitate the training of MM-LLMs to handle diverse user interactions and accurately deliver desired responses.
At last, their research showcases the potential of any-to-any MMLLMs in bridging the gap between various modalities and paving the way for more human-like AI systems in the future.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Arshad is an intern at MarktechPost. He is currently pursuing his Int. MSc Physics from the Indian Institute of Technology Kharagpur. Understanding things to the fundamental level leads to new discoveries which lead to advancement in technology. He is passionate about understanding the nature fundamentally with the help of tools like mathematical models, ML models and AI.
Credit: Source link
Comments are closed.