Meet NIRVANA: An AI Model That Uses Neural Implicit Representations to Compress Videos Efficiently
Video has become the dominant information propagation tool in the online world nowadays. The majority of the Internet traffic consists of video content, and the share looks to continue to rise in the near future. With the emergence of social media platforms like TikTok, Instagram, and YouTube, it is now almost impossible to pass through a day without seeing a video.
Video is the most effective way to convey a message, as you can quickly fit a lot of information. Different shots, scenes, objects, and people can be shown concisely, which could be more effective than giving the message hundreds of pages. This is all sunshine and rainbows until we realize how much data we need to store video. Typically, a minute-long video with acceptable quality, we are talking about 1080P resolution with 30 frames per second here, takes around 100 MB of disk space. And this is the size after compression, which was done via video encoders that are the fruit of decades of hard work and research.
Moreover, when we also need to think this video will be transmitted over the Internet to millions of people, the data consumption of videos becomes a larger issue. This is why video compression plays the utmost importance.
Video compression is done by video codecs like HEVC, AV1, and VVC. These are manually engineered complex tools developed by experts from both academia and industry. Video codecs exploit the similarity among the video frames and represent the same information by using a fraction of data compared to the raw video.
As with all other traditional methods, video codecs have also been the target of deep learning-based advancements in recent years. There have been numerous attempts at improving the performance of video codecs using deep learning methods. These deep learning-based methods have achieved impressive results recently, from guiding the encoder to deciding which microstructure to pick to replacing the entire video codec with an end-to-end neural network.
Deep learning-based codecs have some drawbacks that limit their applicability in the real world. These networks are often needed for these techniques because they try to understand and simplify all the videos in a group. However, their understanding can be limited by the specific videos they were trained on, which can cause them to perform poorly when encountering new or different data. This can happen when the data is from a different video category or when the details of the video we are trying to encode change.
Recently, a new approach called Implicit Neural Representations (INR) has been developed to address the limitations of previous methods for video compression. Unlike learning-based methods, INR does not try to understand and simplify all the data in a group. Instead, it focuses on training a network that is specifically tailored to a particular kind of data, such as images, videos, or 3D scenes. This makes the neural network an efficient storage of data.
The INR has been used to encode videos previously, but they had several problems, which again prevented them to be used in practical scenarios. They are computationally inefficient, do not factor in the spatiotemporal redundancies in the video, and the ones that can learn the temporal relation in the video fail to generalize it for different resolutions.
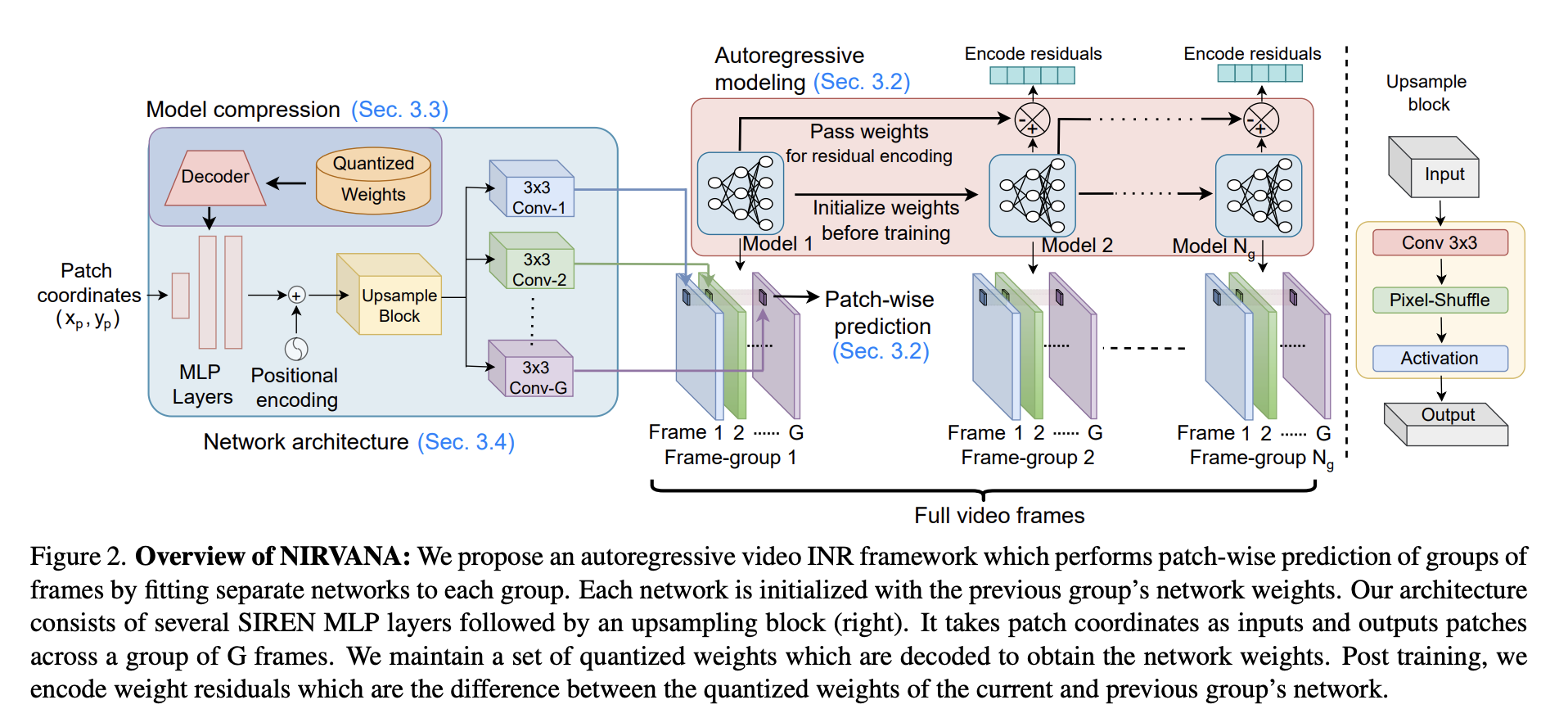
To address these issues and come up with an efficient video encoding tool, NIRVANA is proposed. NIRVANA predicts patches instead of predicting the entire frame or video to adapt the model to videos in different spatial resolutions. Therefore, NIRVANA can be used for videos with different resolutions without requiring to change in the network structure.
Additionally, to make the most of the fact that videos change over time, we suggest training separate, small models, for each group of video frames (clips). These models would work in a sequence, with the model for each group of frames using the information from the model for the previous group of frames to make predictions. This enables NIRVANA to process temporal information in the video while making the overall network computationally efficient.
To achieve even more compression, NIRVANA uses methods to add more specific rules for how encoded video data is simplified and to store information about how the model was trained during the compression process. This fine-tunes the amount of compression to the complexity of each video and eliminates the need for additional steps like pruning and adjusting the model afterward, which can be time-consuming.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.