Meet ‘OcrPy,’ A Python Library To Let Users OCR, Archive, Index, And Search Any Documents With Ease
OCR, or optical character recognition, is one of the major computer vision applications. We frequently find ourselves taking images of documents to send to others. Now everyone would want those materials to be turned into adequately typed documents rather than given as photos. OcrPy is used in this situation. The main goal of OcrPy is to make it simple and obvious for users to OCR, Archive, Index, and Search any documents using a robust Pipeline API.
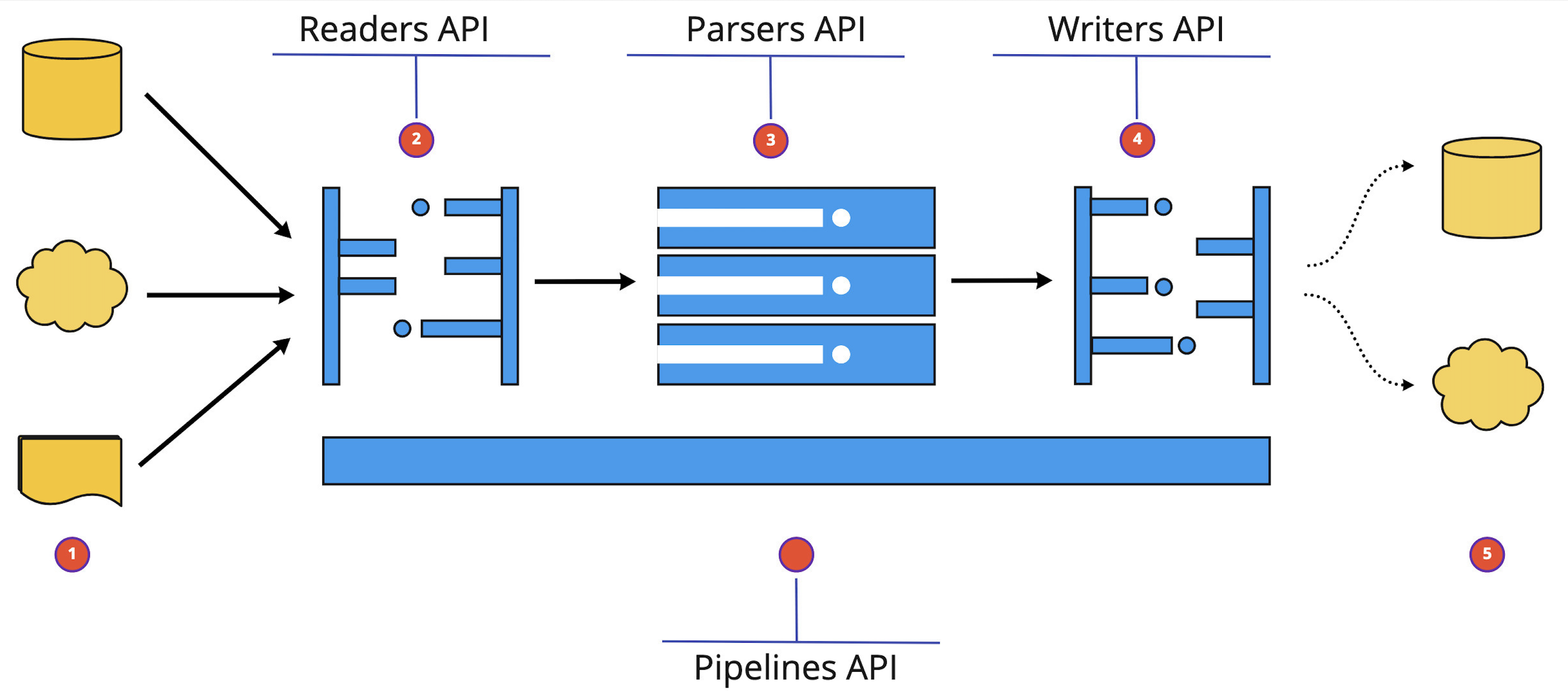
OCRpy is a PyPI-hosted Python-only library. By wrapping over different OCR engines like Tesseract OCR, Aws Textract, Google Cloud Vision, and Azure Computer Vision, ocrpy accomplishes this. It integrates the various user interfaces offered by various cloud technologies and other open-source libraries and gives the user a straightforward, primary interface. Pip is the suggested installation approach. Ocrpy gives the user a choice of abstraction levels to do OCR on different kinds of documents. The best and most preferred method of using Ocrpy is through the pipelines API, which is illustrated here. There are two ways to use the Pipeline API. The first way entails defining the pipeline’s configuration in a yaml file, loading it, and then running the pipeline as follows:
from ocrpy import TextOcrPipeline
ocr_pipeline = TextOcrPipeline.from_config("ocrpy_config.yaml")
ocr_pipeline.process()Alternatively, one can also run a pipeline by directly instantiating the pipeline class as follows:
from ocrpy import TextOcrPipeline
pipeline = TextOcrPipeline(source_dir="s3://document_bucket/",
destination_dir="gs://processed_document_bucket/outputs/",
parser_backend='aws-textract',
credentials_config={"AWS": "path/to/aws-credentials.env/file",
"GCP": "path/to/gcp-credentials.json/file"})
pipeline.process()Ocrpy’s Quick starting Notebook contains a detailed tutorial on how to use it. This notebook explains how to use Ocrpy to carry out the following tasks:
- classification of documents
- Layout parsing
- Table extraction
- Running the entire Text OCR pipeline
- Sending the captured result to their preferred storage

The source code is publicly accessible. In addition, they have excellent documentation with simple code examples to guide one through the learning process.
Documentation | Github link
Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.