Meet OmniControl: An Artificial Intelligence Approach for Incorporating Flexible Spatial Control Signals into a Text-Conditioned Human Motion Generation Model Based on the Diffusion Process
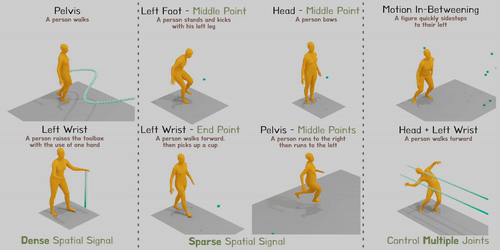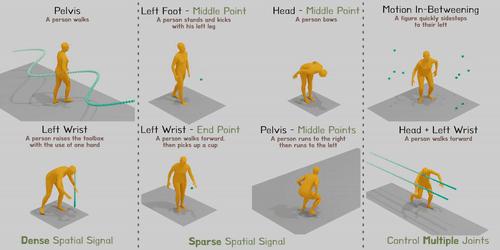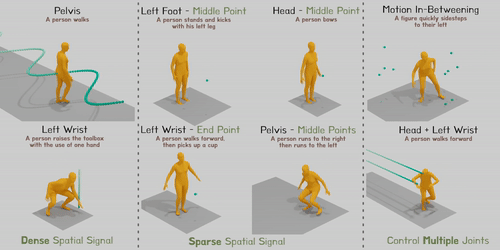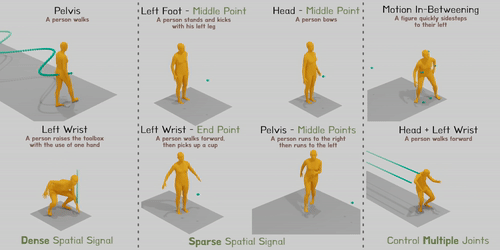
Researchers address the issue of combining spatial control signals over every joint at any given time into text-conditioned human motion production. Modern diffusion-based techniques may produce varied and lifelike human motion, but they find it difficult to incorporate variable spatial control signals, which are essential for many applications. For instance, a model must regulate the hand position to contact the cup at a particular place and time and understand “pick up” semantics to synthesize the action for picking up a cup. Similarly, when moving through a room with low ceilings, a model must carefully regulate the height of the head for a certain amount of time to avoid accidents.
Since they are difficult to explain in the textual prompt, these control signals are often delivered as global positions of joints of interest in keyframes. However, previous inpainting-based approaches cannot incorporate flexible control signals due to their chosen relative human posture representations. The limits are mostly caused by the relative locations of the joints and the pelvis with respect to one another and the prior frame. The global pelvic position supplied in the control signal must thus be translated to a relative location concerning the previous frame to be input to the keyframe. Similar to how other joints’ positions must be input, the global position of the pelvis must also be converted.
However, the pelvis’ relative locations between the diffusion generation process must be more present or corrected in both instances. To integrate any spatial control signal on joints other than the pelvis, one must first need help managing sparse limitations on the pelvis. Others present a two-stage model, but it still has trouble regulating other joints due to the limited control signals over the pelvis. In this study, researchers from Northeastern University and Google Research suggest OmniControl, a brand-new diffusion-based human generation model that may include flexible spatial control signals over any joint at any given moment. Building on OmniControl, realism guiding is added to regulate the creation of human movements.
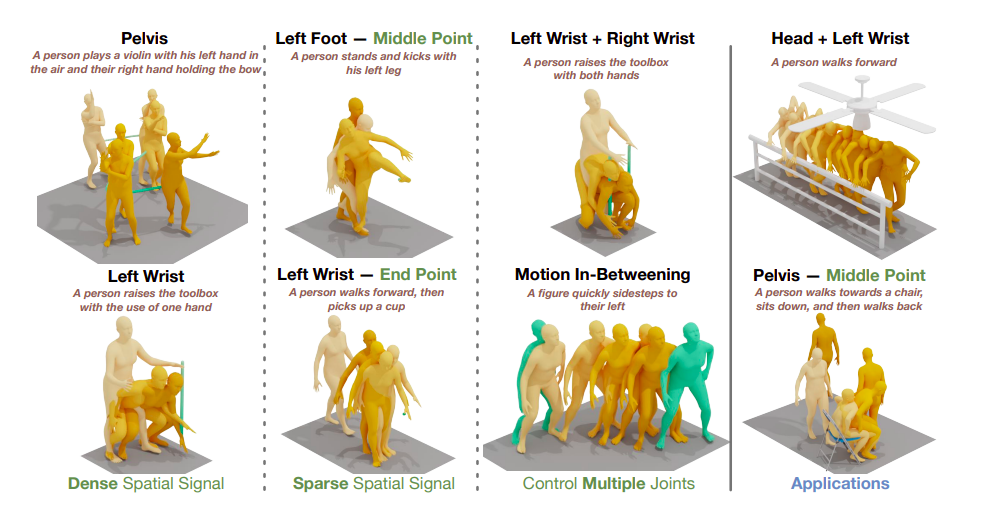
Figure 1: Given a written prompt and adaptable spatial control signals, OmniControl can produce convincing human gestures. Later frames in the series are indicated by darker colours. The input control signals are shown by the green line or points.
For the model to work well, they use the same relative human posture representations for input and output. However, they suggest, in contrast to current approaches, converting the produced motion to global coordinates for direct comparison with the input control signals in the spatial guidance module, where the gradients of the error are employed to improve the motion. It resolves the shortcomings of the earlier inpainting-based methods by removing the uncertainty regarding the relative locations of the pelvis. Additionally, compared to previous approaches, it enables dynamic iterative refining of the produced motion, improving control precision.
Although successfully enforcing space limits, spatial guidance alone frequently results in drifting issues and abnormal human movements. They present the realism guidance, which outputs the residuals w.r.t. the features in each attention layer of the motion diffusion model, to solve these problems by drawing inspiration from the controlled picture production. These residuals can explicitly and densely alter whole-body motion. To produce realistic, coherent, and consistent movements with spatial restrictions, both the spatial and the realism guidance are crucial, and they are complementary in balancing control precision and motion realism.
Studies using HumanML3D and KIT-ML demonstrate that OmniControl performs significantly better than the most advanced text-based motion generation techniques for pelvic control in terms of both motion realism and control accuracy. However, incorporating the spatial limitations over any joint at any moment is where OmniControl excels. Additionally, as illustrated in Fig. 1, they may train a single model to control numerous joints collectively rather than separately (for example, both the left and right wrists).
These features of OmniControl make it possible for several downstream applications, such as tying produced a human motion to the surrounding scenery and objects, as seen in Fig. 1’s last column. Their brief contributions are: (1) As far as they are aware, OmniControl is the first strategy capable of combining spatial control signals over any joint at any moment. (2) To successfully balance the control precision and motion realism in the produced motion, they suggest a unique control module that uses spatial and realism guidance. (3) Tests demonstrate that OmniControl can control additional joints using a single model in text-based motion creation, setting a new standard for controlling the pelvis and opening up various applications in human motion production.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.