Meet OpenAssistant: An open-source chat model That consists of a ~161K human-generated, human-annotated assistant-style conversation corpus, including 35 different languages
Recent years have seen remarkable artificial intelligence (AI) development, especially in natural language processing. A simple formula is at the heart of most significant advances:
- Take a basic transformer-based architecture.
- Scale up the depth and width of the parameters.
- Use a much larger training set.
Despite their demonstrable, human-level capacity to fit training data and generalize depending on their programmed purpose, the general public needs to be more active in accepting models. The major cause is when the model’s predictions don’t match the actual application.
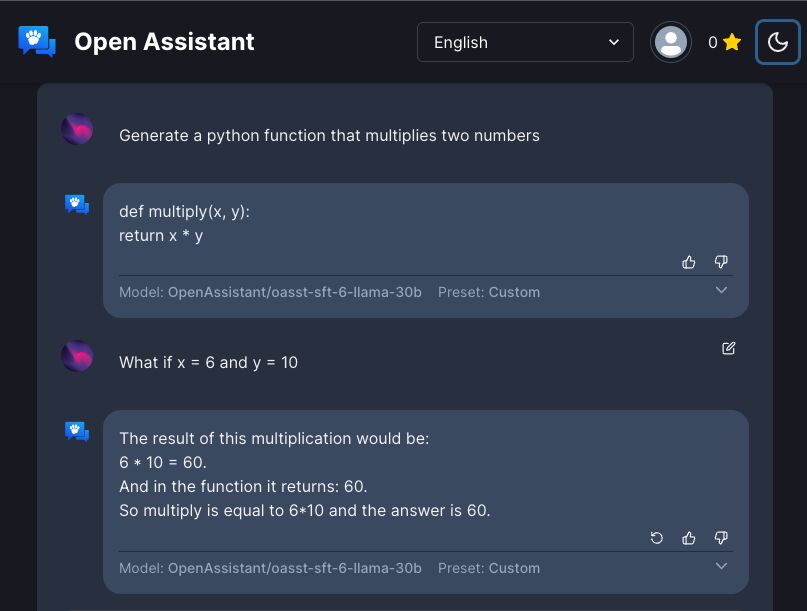
ChatGPT is an excellent example of this type of assistant-style approach, and its meteoric rise in popularity may be attributed not just to the impressive skills it has shown in various contexts but also to its user-friendliness. To bring the model’s predictions into line with reality, we give it reinforcement learning from human feedback (RLHF) and human-generated examples of the desired application. As the instructor in RLHF, the human doles out praise or criticism as feedback.
Synthetic data comprising instructions automatically created by querying language models makes up the most publicly available datasets. Unfortunately, these datasets’ complexity, originality, and quality are constrained by their reliance on a fixed set of allowed instruction types. Even with extensive size and pre-training, models will fail to produce effective, helpful, and safe AI assistants if they lack sufficient breadth and quality of data. The OpenAssistant Conversations dataset was introduced and made publicly available to democratize the study of the problem of aligning big language models. The distribution of this information to the academic community results from a large-scale open- and crowd-sourcing campaign that aims to encourage more diverse study in this important field.
Researchers evaluate the dataset thoroughly, taking into account ethical and safety concerns. Researchers also fine-tune and distribute many assistance and preference models to promote and provide access and study in this domain. As a result of this openness, the released artifacts may be improved through iterative cycles, leading to a more cooperative and welcoming research atmosphere.
Collection of Data and Its Structure
A Conversation Tree (CT) is the primary data structure, with its nodes standing in for individual conversational exchanges. The CT’s root node represents the prompter’s initial prompt. Researchers have given names to the discussion prompter and helper roles to provide clarity. A human user or a computer can play the roles of prompter and assistant. Because of this, we can save “users” for our human helpers.
More than 13,000 people contributed to a crowd-sourcing project to compile the data used to create the OpenAssistant Conversations dataset. A web app interface5 was used to gather the data. It simplified the procedure into five phases: prompting, labeling prompts, adding reply messages as prompter or assistant, labeling replies, and scoring assistant answers. Content moderation and spam filtering were integral parts of the annotation workflow used to curate the dataset, guaranteeing its high quality and security.
Message trees are included in this data collection. Each message tree begins with a prompt message at its root and can expand to include any number of child messages representing responses.
“Assistant” and “Prompter” are possible values for the role attribute of a message. From prompt to a leaf node, the responsibilities of “prompter” and “assistant” switch off regularly.
Limitations
Issues with the dataset include unequal distribution of contributions among users, potentially dangerous information, and the annotators’ inherent subjectivity and cultural prejudices.
- Due to the transparency of the research, there will be new difficulties in removing any biases from the data. Annotators from various socioeconomic and cultural backgrounds populate the collection.
- Annotations from more active users tend to skew the dataset toward reflecting those users’ preferences. As a result, the dataset may lack the diversity of opinion that resulted from a more even distribution of contributions.
- While measures have been taken to detect offensive comments and remove them from the data set, the system must be completely secure. There is still a chance that the dataset contains sensitive data that might cause harm.
- Recognizing that existing alignment procedures are not flawless and can potentially increase certain biases is significant because the alignment of LLMs is a fundamental element of AI research.
Researchers understand that very sophisticated language models may have far-reaching effects on society. As a result, they feel it crucial to advocate for openness and ethical concerns while creating and deploying such models. These models can generate inaccurate information about persons, locations, or facts (sometimes known as “hallucinations”). In addition to creating harmful or vile information, LLMs can also violate the boundaries set by their users. Although techniques like RLHF can help with some drawbacks, they may worsen others. To stimulate the study of alignment in LLMs, researchers provided the OpenAssistant Conversations dataset.
One may find a variety of models and their associated data here.
Please see here for further information and examples.
ChatGPT shows that aligning large language models (LLMs) with human preferences significantly improves usability and drives quick adoption. To make LLMs more accessible and useful in a wide range of domains, alignment approaches like supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) have been developed. State-of-the-art alignment techniques like RLHF require high-quality human feedback data, yet this data is costly and typically kept secret. Researchers have released OpenAssistant Conversations, a human-generated and human-annotated assistant-style chat corpus, to democratize research on large-scale alignment.
Check out the Paper, Web, Dataset, and Model. Don’t forget to join our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.