Meet OpenMoE: A Series of Fully Open-Sourced and Reproducible Decoder-Only MoE LLMs

In the evolving landscape of Natural Language Processing (NLP), developing large language models (LLMs) has been at the forefront, driving a broad spectrum of applications from automated chatbots to sophisticated programming assistants. However, the computational expense of training and deploying these models has posed significant challenges. As the demands for higher performance and complexity grow, the need for innovative solutions to enhance computational efficiency without compromising on capabilities becomes paramount.
Enter the Mixture-of-Experts (MoE) concept, a promising approach designed to scale model parameters efficiently by incorporating multiple specialized networks or experts within a larger model framework. The MoE architecture allows dynamic input routing to the most relevant experts, offering a pathway to achieve superior task performance through a more judicious use of computational resources.
A research initiative by researchers from the National University of Singapore, the University of Edinburgh, and ETH Zurich led to the creation of OpenMoE, a comprehensive suite of decoder-only MoE-based LLMs ranging from 650 million to an impressive 34 billion parameters. These models were meticulously trained on an expansive dataset spanning over one trillion tokens, embodying various languages and coding data. The research team’s commitment to openness and reproducibility has made OpenMoE’s full source code and training datasets available to the public, a move aimed at demystifying MoE-based LLMs and catalyzing further innovation in the field.
A cornerstone of OpenMoE’s development was its in-depth analysis of MoE routing mechanisms. The research unearthed three pivotal findings: the prevalence of context-independent specialization, the establishment of token-to-expert assignments early in the training phase, and a tendency for later sequence tokens to be dropped. Such insights into the inner workings of MoE models are critical, revealing strengths and areas ripe for improvement. For instance, the observed routing decisions, largely based on token IDs rather than contextual relevance, pinpoint a potential avenue for optimizing performance, particularly in tasks requiring sequential understanding, like multi-turn conversations.
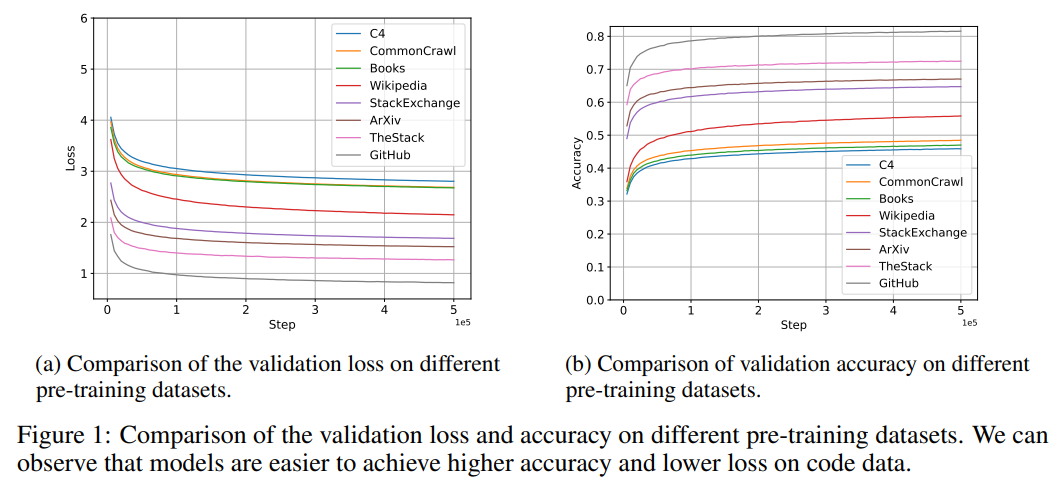
OpenMoE’s performance evaluation across various benchmarks demonstrated commendable cost-effectiveness, challenging the conventional wisdom that increased model size and complexity necessarily entail proportional rises in computational demand. In direct comparisons, OpenMoE variants showcased competitive, if not superior, performance against densely parameterized models, highlighting the efficacy of the MoE approach in leveraging parameter scalability for enhanced task performance.
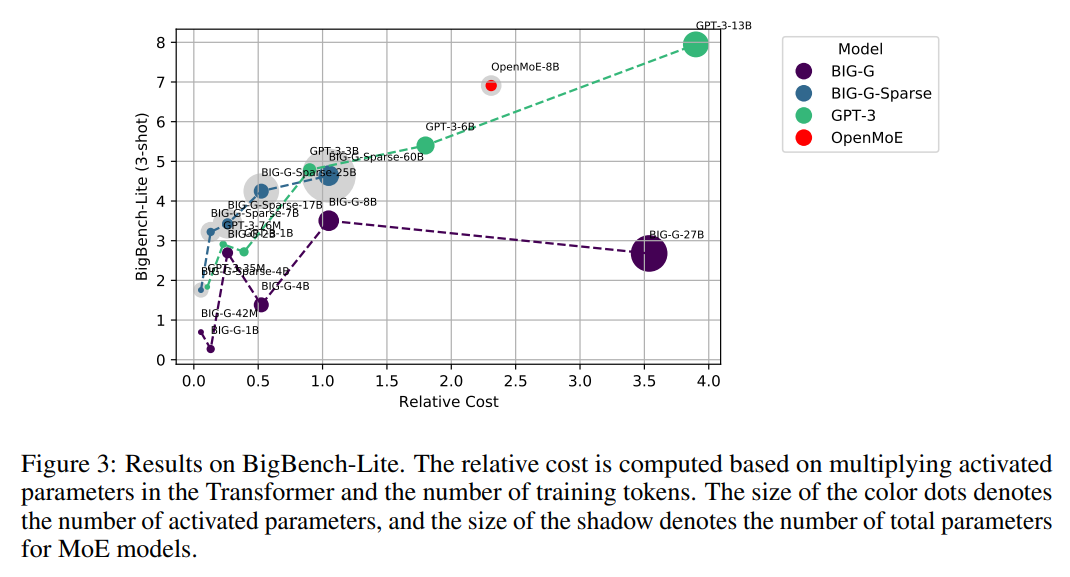
Beyond mere performance metrics, the OpenMoE project represents a significant leap toward a more accessible and democratic NLP research landscape. By sharing in-depth analyses, training methodologies, and the very models themselves, the research team provides a robust foundation for future explorations into MoE-based LLMs. This open-source ethos not only accelerates the pace of innovation but also ensures that advancements in NLP technology remain within reach of a broader community, fostering a more inclusive field.

In conclusion, OpenMoE is a beacon of progress in the quest for more efficient and powerful language models. Through its innovative use of MoE architecture, comprehensive analysis of routing mechanisms, and exemplary commitment to openness, the project advances our understanding of MoE models. It sets a new standard for future LLM development. As the NLP community continues to grapple with the dual challenges of computational efficiency and model scalability, OpenMoE offers both a solution and a source of inspiration, paving the way for the next generation of language models that are both powerful and pragmatically viable.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.