Meet PANOGEN: A Generation Method that can Potentially Create an Infinite Number of Diverse Panoramic Environments Conditioned on Text

Whenever someone talks about artificial intelligence, the first thing that comes to mind is a robot, an android, or a humanoid that can do things humans do with the same effect, if not better. We have all seen such specific miniature robots deployed in various fields, for example, in airports guiding people to certain outlets, in armed forces to navigate and deal with difficult situations, and even as trackers.
All of these are some amazing examples of AI in a truer sense. As with every other AI model, this has some basic requirements that need to be satisfied, for example, which choice of algorithm, the big corpus of data to train on, finetuning, and then deployment.
Now, this type of problem is often referred to as the Visual-and-Language-Navigation problem. Vision and language navigation in artificial intelligence (AI) refers to the ability of an AI system to understand and navigate the world using visual and linguistic information. It combines computer vision, natural language processing, and machine learning techniques to build intelligent systems that can perceive graphic scenes, understands textual instructions, and navigate physical environments.
Many models, such as CLIP, RecBERT, and PREVALENT, work on these problems, but all of these models greatly suffer from two major issues.
Limited Data and Data Bias: Training visual and learning systems require large amounts of labeled data. However, obtaining such data can be expensive, time-consuming, or even impractical in certain domains. Moreover, the availability of diverse and representative data is crucial to avoid bias in the system’s understanding and decision-making. If the training data is biased, it can lead to unfair or inaccurate predictions and behaviors.
Generalization: AI systems need to generalize well to unseen or novel data. They should memorize the training data and learn underlying concepts and patterns that can be applied to new examples. Overfitting occurs when a model performs well on the training data but fails to generalize to new data. Achieving robust generalization is a significant challenge, particularly in complex visual tasks that involve variations in lighting conditions, viewpoints, and object appearances.
Though many efforts have been proposed to help the agent learn diverse instruction inputs, all these datasets are built on the same 3D room environments from Matterport3D, which only contains 60 different room environments for agents’ training.
PanoGen, the breakthrough in the AI domain, has provided a strong solution to this problem. Now with PanoGen, the scarcity of data is solved, and corpus creation and data diversification have also been streamlined.
PanoGen is a generative method that can create infinite diverse panoramic images (environments) based on the text. They have collected room descriptions by captioning the room images available with the Matterport3D dataset and have used SoTA text-to-image model to generate panoramic visions (environments). They then use recursive outpainting over the generated image to create a consistent 360-degree panorama view. The panoramic pictures developed share similar semantic information conditioning on text descriptions, which ensures the co-occurrence of objects in the panorama follows human intuition, and creates enough diversity in room appearance and layout with image outpainting.
They have mentioned that there have been attempts to increase the variety of training data and improve the corpus. All of those attempts were based on mixing scenes from HM3D (Habitat Matterport 3D), which again brings back the same issue that all the settings, more or less, are made with Matterport3D.
PanoGen solves this problem as it can create an infinite number of training data with as many variations as needed.
The paper also mentions that using the PanoGen approach, they beat the current SoTA and achieved the new SoTA on Room-to-Room, Room-for-Room, and CVDN datasets.
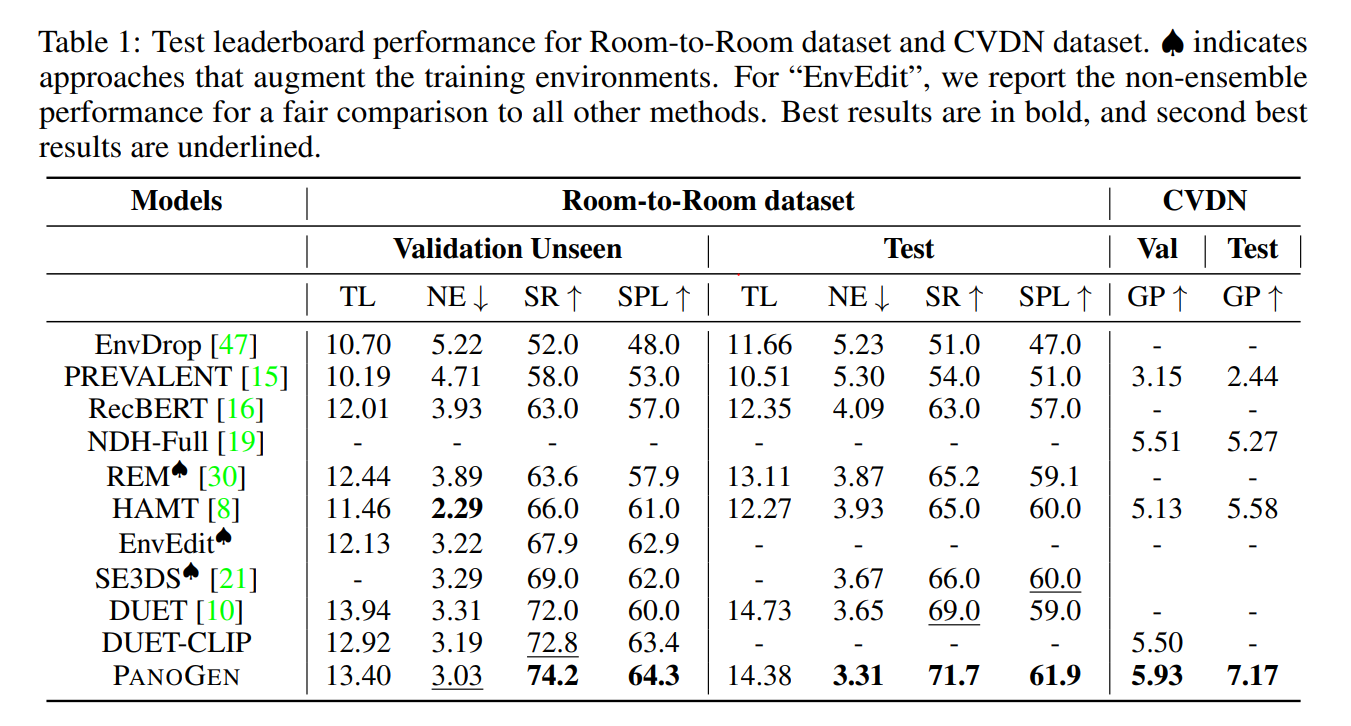
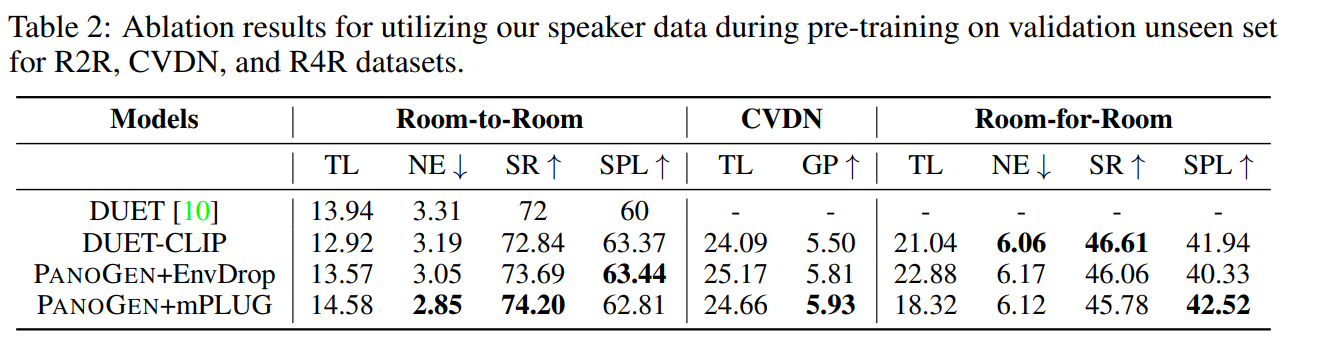
Conclusively, PanoGen is a breakthrough development that addresses the key challenges in Visual-and-Language Navigation problems. With the ability to generate unlimited training samples with many variations, PanoGen opens up new possibilities for AI systems to understand and navigate the real world as humans do. The approach’s remarkable ability to surpass the SoTA highlights its potential to revolutionize AI-driven VLN tasks.
Check Out The Paper, Code, and Project. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Anant is a Computer science engineer currently working as a data scientist with experience in Finance and AI products as a service. He is keen to build AI-powered solutions that create better data points and solve daily life problems in an impactful and efficient way.
Credit: Source link
Comments are closed.