Meet Pix2Act: An AI Agent That Can Interact With GUIs Using The Same Conceptual Interface That Humans Commonly Use Via Pixel-Based Screenshots And Generic Keyboard And Mouse Actions
By enabling users to connect with tools and services, systems that can follow directions from graphical user interfaces (GUIs) can automate laborious jobs, increase accessibility, and increase the utility of digital assistants.
Many GUI-based digital agent implementations rely on HTML-derived textual representations, which aren’t always readily available. People utilize GUIs by perceiving the visual input and acting on it with standard mouse and keyboard shortcuts; they don’t need to look at the application’s source code to figure out how the program works. Regardless of the underlying technology, they can rapidly pick up new programs with intuitive graphical user interfaces.
The Atari game system is just one example of how well a system that learns from pixel-only inputs may do. However, there are many obstacles presented by learning from pixel-only inputs in conjunction with generic low-level actions when attempting GUI-based instruction following tasks. To visually interpret a GUI, one must be familiar with the interface’s structure, able to recognize and interpret visually located natural language, recognize and identify visual elements and forecast the functions and interaction methods of those elements.
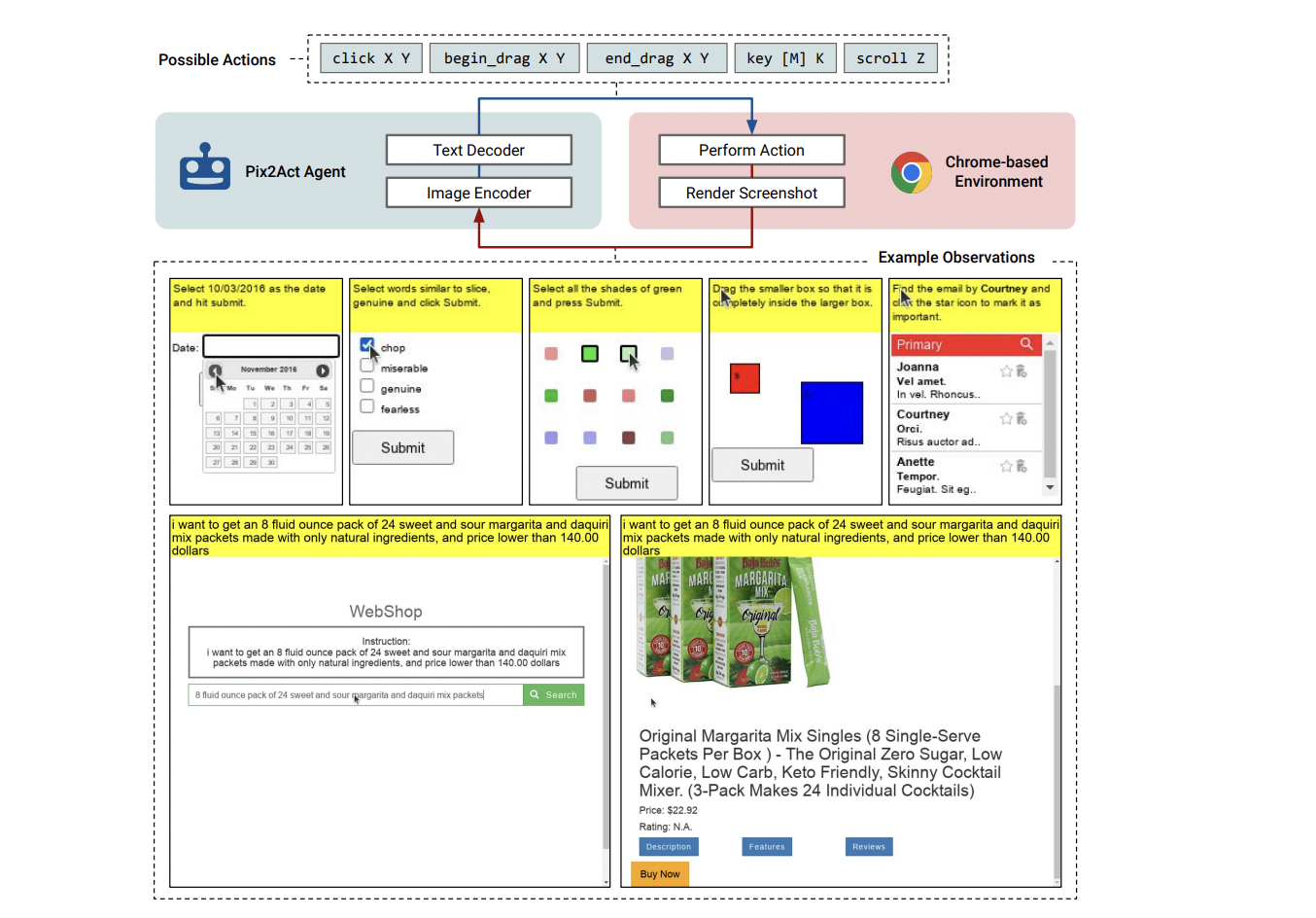
Google DeepMind and Google introduce PIX2ACT, a model that takes pixel-based screenshots as input and chooses actions matching fundamental mouse and keyboard controls. For the first time, the research group demonstrates that an agent with only pixel inputs and a generic action space can outperform human crowdworkers, achieving performance on par with state-of-the-art agents that use DOM information and a comparable number of human demonstrations.
For this, the researchers expand upon PIX2STRUCT. This Transformer-based image-to-text model has already been trained on large-scale online data to convert screenshots into structured representations based on HTML. PIX2ACT applies tree search to repeatedly construct new expert trajectories for training, employing a combination of human demonstrations and interactions with the environment.
The team’s effort here entails the creation of a framework for universal browser-based environments and adapting two benchmark datasets, MiniWob++ and WebShop, for use in their environment using a standard, cross-domain observation and action format. Using their proposed option (CC-Net without DOM), PIX2ACT outperforms human crowdworkers approximately four times on MiniWob++. Ablations demonstrate that PIX2STRUCT’s pixel-based pre-training is essential to PIX2ACT’s performance.
For GUI-based instruction following pixel-based inputs, the findings demonstrate the efficacy of PIX2STRUCT’s pre-training via screenshot parsing. Pre-training in a behavioral cloning environment raises MiniWob++ and WebShop task scores by 17.1 and 46.7, respectively. Although there is still a performance disadvantage compared to larger language models using HTML-based inputs and task-specific actions, this work set the first baseline in this environment.
Check Out The Paper. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.