Meet POCO: A Novel Artificial Intelligence Framework for 3D Human Pose and Shape Estimation
Estimating 3D Human Pose and Shape (HPS) from photos and moving pictures is necessary to reconstruct human actions in real-world settings. Nevertheless, 3D inference from 2D images poses significant challenges due to factors such as depth ambiguities, occlusion, unusual clothing, and motion blur. Even the most advanced HPS methods make errors and are often unaware of these mistakes. HPS is an intermediate task that provides output consumed by downstream tasks like understanding human behavior or 3D graphics applications. These downstream tasks require a mechanism to assess the accuracy of HPS results, and, as a result, these methods must produce an uncertainty (or confidence) value that correlates with the quality of HPS.
One approach to addressing this uncertainty is to output multiple bodies, yet this still lacks an explicit measure of uncertainty. Some exceptions do exist, which estimate a distribution over body parameters. One approach is to compute uncertainty by drawing samples from a distribution over bodies and calculating the standard deviation of these samples. While this method is valid, it suffers from two limitations: it is slow since it necessitates multiple forward network passes to generate samples, and it trades off accuracy for speed. More samples improve accuracy but increase computational demands.
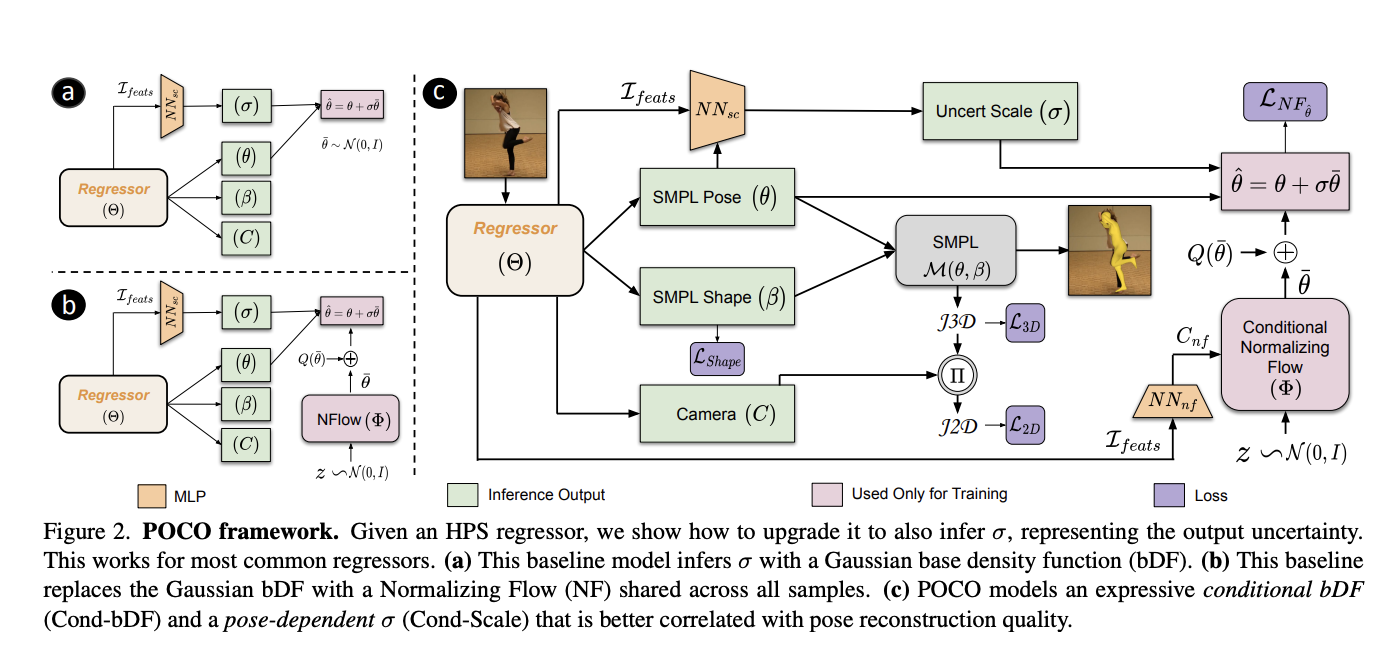
Recently, an approach has been developed to skip explicit supervision by training a network to output both body parameters and uncertainty simultaneously. Inspired by work on semantic segmentation, it uses a Gaussian-based base density function but recognizes the need for more complex distributions for modeling human poses. Methods directly estimating uncertainty typically include a base density function and a scale network. Existing methods use an unconditional bDF and solely rely on image features for the scale network. This approach works well when samples share a similar distribution but falls short when handling diverse datasets required for robust 3D HPS models.
The authors introduce POCO (“POse and shape estimation with COnfidence”), a novel framework applicable to standard HPS methods to address these challenges. POCO extends these methods to estimate uncertainty. In a single feed-forward pass, POCO directly infers both Skinned Multi-Person Linear Model (SMPL) body parameters and its regression uncertainty, which is highly correlated with the reconstruction quality. The key innovation in this framework is the Dual Conditioning Strategy (DCS), which enhances the base density function and scale network. An overview of the framework is presented in the figure below.

Unlike previous approaches, POCO introduces a conditional vector (Cond-bDF) to model the base density function of the inferred pose error. Rather than using a simplistic one-hot data source encoding, POCO employs image features for conditioning, enabling more scalable training on diverse and complex image datasets. Furthermore, POCO’s authors introduce an enhanced approach for estimating uncertainty in HPS models. They use image features and condition the network on the SMPL pose, resulting in improved pose reconstruction and better uncertainty estimation. Their method can be seamlessly integrated into existing HPS models, improving accuracy without downsides. The study claims this approach outperforms state-of-the-art methods in correlating uncertainty with pose errors. The results displayed in their work are reported below.

This was the summary of POCO, a novel AI framework for 3D human pose and shape estimation. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.