Meet PolyLM (Polyglot Large Language Model): An Open Source Multilingual LLM trained on 640B Tokens, Available In Two Model Sizes 1.7B and 13B
With the recent introduction of Large Language Models (LLMs), its versatility and capabilities have drawn everyone’s interest in the Artificial Intelligence sector. These models have been trained on massive amounts of data and possess some brilliant human-imitating abilities in understanding, reasoning, and generating text based on natural language instructions. Having good performance in zero-shot and few-shot tasks, these models can handle unforeseen challenges based on instructions given in natural language by being fine-tuned on various sets of tasks.
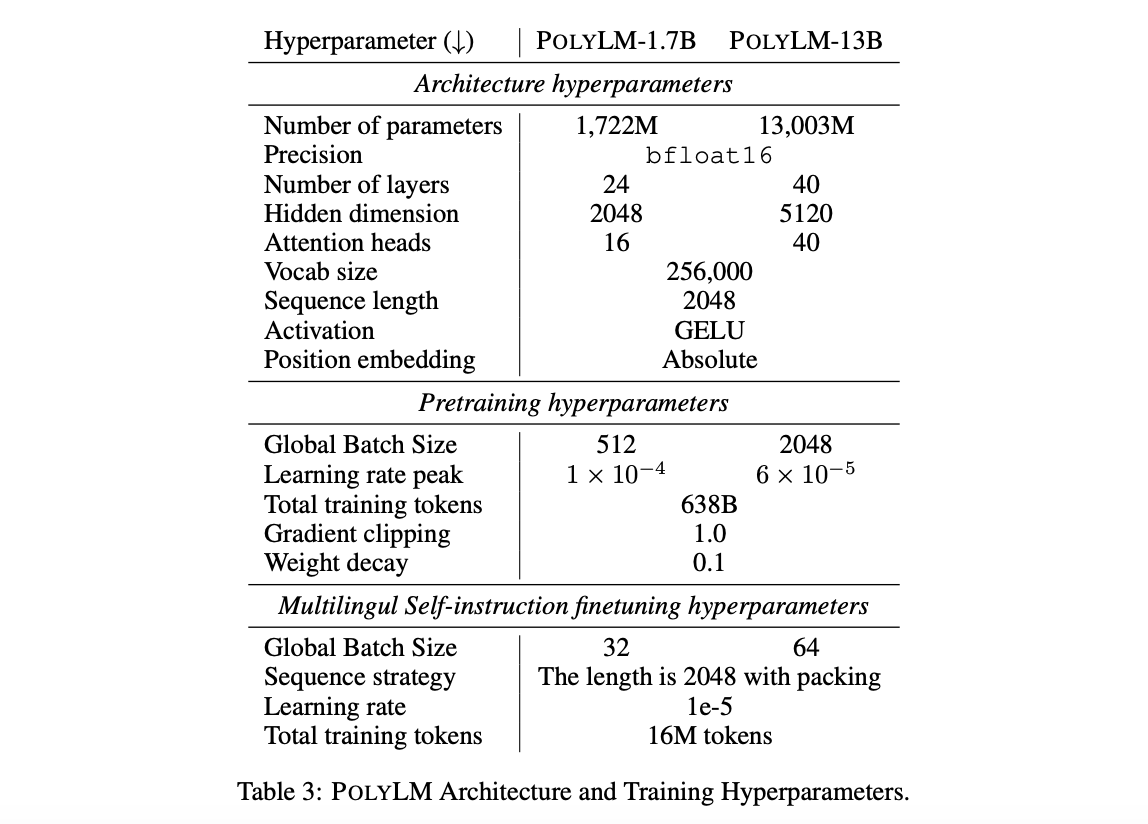
Current LLMs and their development focus on English and resource-rich languages. Most of the existing LLMs have been specifically designed and trained for the English language, resulting in a predominant bias towards English in the research and development of these models. To address this limitation, a team of researchers from DAMO Academy and Alibaba Group have proposed a multilingual LLM called POLYLM (Polyglot Large Language Model). Unlike existing multilingual LLMs that lack a 13B model, the team has released POLYLM-13B and POLYLM-1.7B to facilitate usage.
POLYLM has been built using a massive dataset of 640B tokens from publically accessible sources, including Wikipedia, mC4, and CC-100. The team has also suggested a curricular learning technique to address the issue of insufficient data for low-resource languages. This method involves gradually increasing the ratio of high-quality, low-resource languages during training while initially focusing more on English. Focus has been made on transferring general knowledge from English to other languages.
The team has also developed MULTIALPACA, a multilingual instruction dataset, for the supervised fine-tuning (SFT) phase. Existing multilingual SFT datasets are either obtained through manual annotation, which is time-consuming and expensive, or through machine translation, which may result in translation errors and lacks cultural nuances. This multilingual self-instruct approach automatically provides high-quality multilingual instruction data to overcome these restrictions and makes use of English seeds, translations into many languages, instruction production, and filtering systems.
For evaluation and to assess the multilingual capabilities of LLMs, the team has developed a benchmark derived from existing multilingual tasks, including question answering, language understanding, text generation, and cross-lingual machine translation. The benchmark has been developed with meticulous prompting and covers ten tasks across 15 languages. The team has demonstrated through extensive experiments that their pretrained model outperforms open-source models of comparable size in non-English languages. The proposed curriculum training strategy improves multilingual performance while maintaining English proficiency. The use of multilingual instruction data also significantly enhances POLYLM’s ability to tackle multilingual zero-shot tasks.
The team has summarized the contributions as follows.
- A proficient 13B scale model has been performed that performs well in major non-English languages like Spanish, Russian, Arabic, Japanese, Korean, Thai, Indonesian, and Chinese. This model complements existing open-source models that either lack proficiency in these languages or have smaller versions without the same capabilities.
- An advanced curriculum learning approach has been proposed that facilitates the transfer of general knowledge, mainly acquired in English, to diverse non-English languages and specific natural language processing tasks, such as machine translation.
- A dataset called MULTIALPACA has been proposed that complements existing instruction datasets, allowing LLMs to better follow multilingual instructions, particularly from non-native English speakers.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.