Meet PRODIGY: A Pretraining AI Framework That Enables In-Context Learning Over Graphs
The GPT model, which is the transformer architecture behind the well famous chatbot developed by OpenAI called ChatGPT, works on the concept of learning tasks with the help of only a few examples. This approach, called in-context learning, saves the model from fine-tuning with thousands of input texts and enables it to learn to perform well on different tasks using only task-specific examples as input. Fine-tuning the models for specific tasks can be very expensive as GPT is a “large” Language model with billions of parameters, and as all the model parameters need to be updated during fine-tuning, it turns out to be comparatively costly.
In-context learning is effectively used for code generation, question answering, machine translation, etc., but it still lacks and faces challenges in its use for graph machine learning tasks. Some of the Graph machine learning tasks include the identification of spreaders spreading half-truths or false news on social networks and product recommendations across e-commerce websites. In-context learning faces limitations in formulating and modeling these tasks over graphs in a unified task representation that enables the model to tackle a variety of tasks without retraining or parameter tuning.
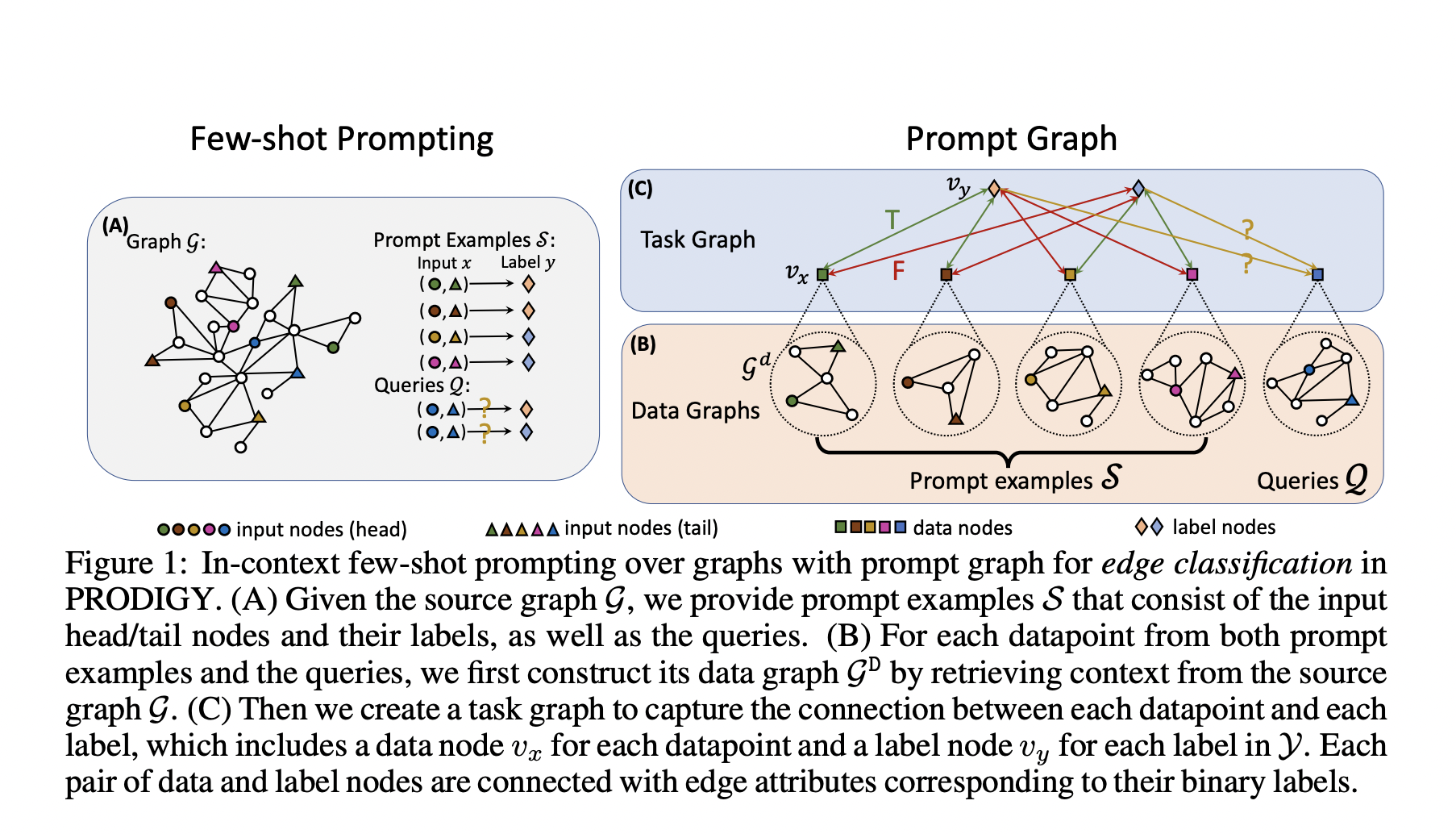
Recently, a team of researchers introduced PRODIGY in their research paper, a pretraining framework to enable in-context learning over graphs. PRODIGY (Pretraining Over Diverse In-Context Graph Systems) formulates in-context learning over graphs using prompt graph representation. Prompt graph serves as an in-context graph task representation that integrates the modeling of nodes, edges, and graph-level machine learning tasks. The prompt network connects the input nodes or edges with additional label nodes and contextualizes the prompt examples and inquiries. This interconnected representation allows diverse graph machine-learning tasks to be specified to the same model, irrespective of the size of the graph.
Proposed by researchers from Stanford University and the University of Ljubljana, the team has designed a graph neural network architecture that has been specifically tailored for processing the prompt graph and which effectively models and learns from graph-structured data. The suggested design makes use of GNNs to teach representations of the prompt graph’s nodes and edges. Also, a family of in-context pretraining objectives has been introduced to guide the learning process, which provides supervision signals enabling the model to capture relevant graph patterns and generalize across diverse tasks.
To evaluate the performance and how effective PRODIGY is, the authors have conducted experiments on tasks involving citation networks and knowledge graphs. Citation networks represent relationships between scientific papers, while knowledge graphs capture structured information about different domains. The pretrained model has been tested on these tasks using in-context learning, and the results are compared with contrastive pretraining baselines with hard-coded adaptation and standard fine-tuning with limited data. PRODIGY outperformed contrastive pretraining baselines with hard-coded adaptation by an average of 18% in terms of accuracy. It achieved an average improvement of 33% over standard fine-tuning with limited data when in-context learning was applied.
In conclusion, PRODIGY seems promising in graph-based scenarios like in-context learning in graph machine learning applications. It can even perform downstream classification tasks on previously unseen graphs, which makes it even more effective and beneficial.
Check Out The Paper. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.