Meet Prompt Diffusion: An AI Framework For Enabling In-Context Learning In Diffusion-Based Generative Models
State-of-the-art large language models (LLMs), including BERT, GPT-2, BART, T5, GPT-3, and GPT-4, have been developed as a result of recent advances in machine learning, notably in the area of natural language processing (NLP). These models have been effectively used for various tasks, including text production, machine translation, sentiment analysis, and question-answering. Their capacity to learn from context, often known as in-context learning, is one of these LLMs’ emergent behaviors. Without optimizing any model parameters, LLMs with in-context learning capabilities, like GPT-3, can complete a job by conditioning on input-output samples and fresh query inputs.
The pre-training of numerous language tasks may be combined with in-context learning and a well-designed prompt structure, allowing LLMs to generalize successfully to activities they have never encountered. Although in-context learning has been widely investigated in NLP, few applications in computer vision exist. There are two significant difficulties to demonstrating the practicality and promise of in-context learning as a standard technique for great vision applications: 1) Creating an effective vision prompt is more difficult than creating prompts for language activities because it requires both domain-specific input-output pairs as examples and picture searches as criteria. 2) In computer vision, big models are often trained for specialized tasks, including text-to-image generation, class-conditional creation, segmentation, detection, and classification.
These huge vision models must be more flexible to adapt to new tasks and are not built for in-context learning. Several recent attempts address these issues by using NLP’s answers. Specifically, when a fundamental visual cue is made by fusing sample photographs, query images, and output images into one massive embodiment, a Transformer-based image inpainting model is trained to anticipate the masked output images. However, stitching to huge photos will significantly raise the computational expense, particularly in high-resolution scenarios. This work addresses the in-context learning potential of text-guided diffusion-based generative models by addressing these two issues.
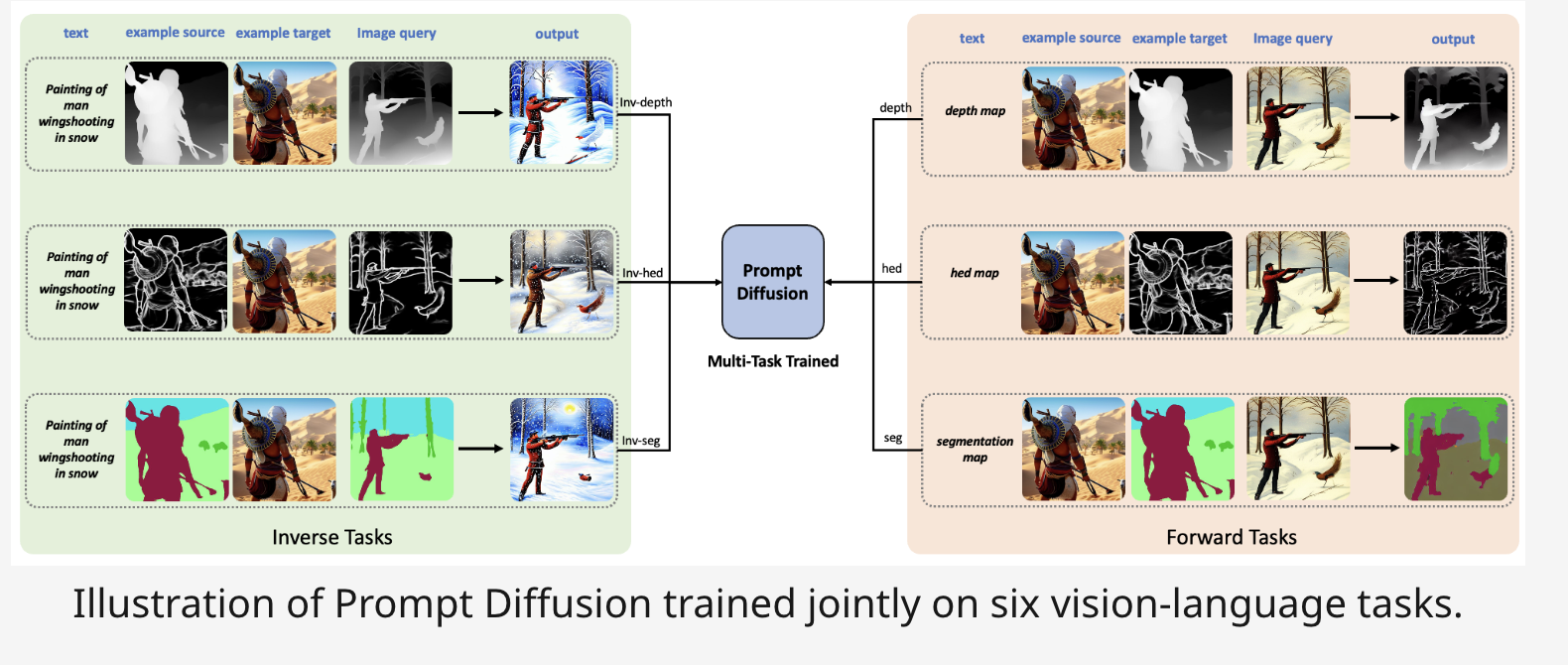
To execute in-context learning under a vision-language prompt that can handle a wide range of vision-language activities, researchers from Microsoft and UT Austin present a novel model architecture called Prompt Diffusion. Prompt Diffusion is put through six separate vision-language tasks in tandem. Specifically, they utilize their vision-language prompt to describe a generic vision-language task. Then, using the Stable Diffusion and ControlNet designs as inspiration, they construct Prompt Diffusion, which may use their vision-language prompt as input. They suggest Prompt Diffusion as a first step towards enabling text-guided diffusion models’ capacity for in-context learning. It may then use this knowledge to create the output image by re-mapping the connection onto the query image and including the language instructions. More crucially, learning across many tasks endows the model with the capacity for in-context learning. Prompt Diffusion may generalize successfully over several novel functions that have not yet been observed. This is in addition to performing well on the six tasks it has seen during training.
Empirically, Prompt Diffusion performs well on familiar and novel, unseen tasks regarding in-context learning. Prompt Diffusion’s effectiveness is expected to inspire and spur more study into diffusion-based, in-context visual learning. Following is a summary of their key contributions:
• A cutting-edge design for vision-language prompts that effectively enables the fusion of multiple vision-language activities.
• High-quality in-context generation on the learned and new, unseen tasks using the prompt diffusion model, the first diffusion-based adaptable vision-language foundation model capable of in-context learning.
• Pytorch code implementation can be found on GitHub.
Check out the Paper, Project, and Github Link. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.