Meet PromptingWhisper: Using Prompt Engineering to Adapt the Whisper Model to Unseen Tasks, the Proposed Prompts Enhances Performance by 10% to 45% on Three Zero-Shot Tasks
All the advancements that have been recently taking place in the field of Artificial Intelligence have enabled us to define intelligent systems with a better and more articulate understanding of language than ever before. With each upgradation and release, Large Language Models are becoming more capable of catering to different necessities in applications and scenarios. For any robust and efficient model, it is important to have a proper training prompt along with its design and content. Prompt engineering involves designing a prompt that would enable the user to receive a suitable response from the model. Its main objective is to feed the model with a good quality training prompt so that the model easily finds patterns and trends in the data.
Specifically focussing on the domain of audio and speech processing, the study of prompt engineering has gained attention but is relatively new compared to other domains. The Whisper model, which OpenAI released, is a transformer-based encoder-decoder model that can be classified into two groups: English-only and multilingual. Trained on a large dataset consisting of 680,000 hours of web-scraped speech data, Whisper is an automatic speech recognition model.
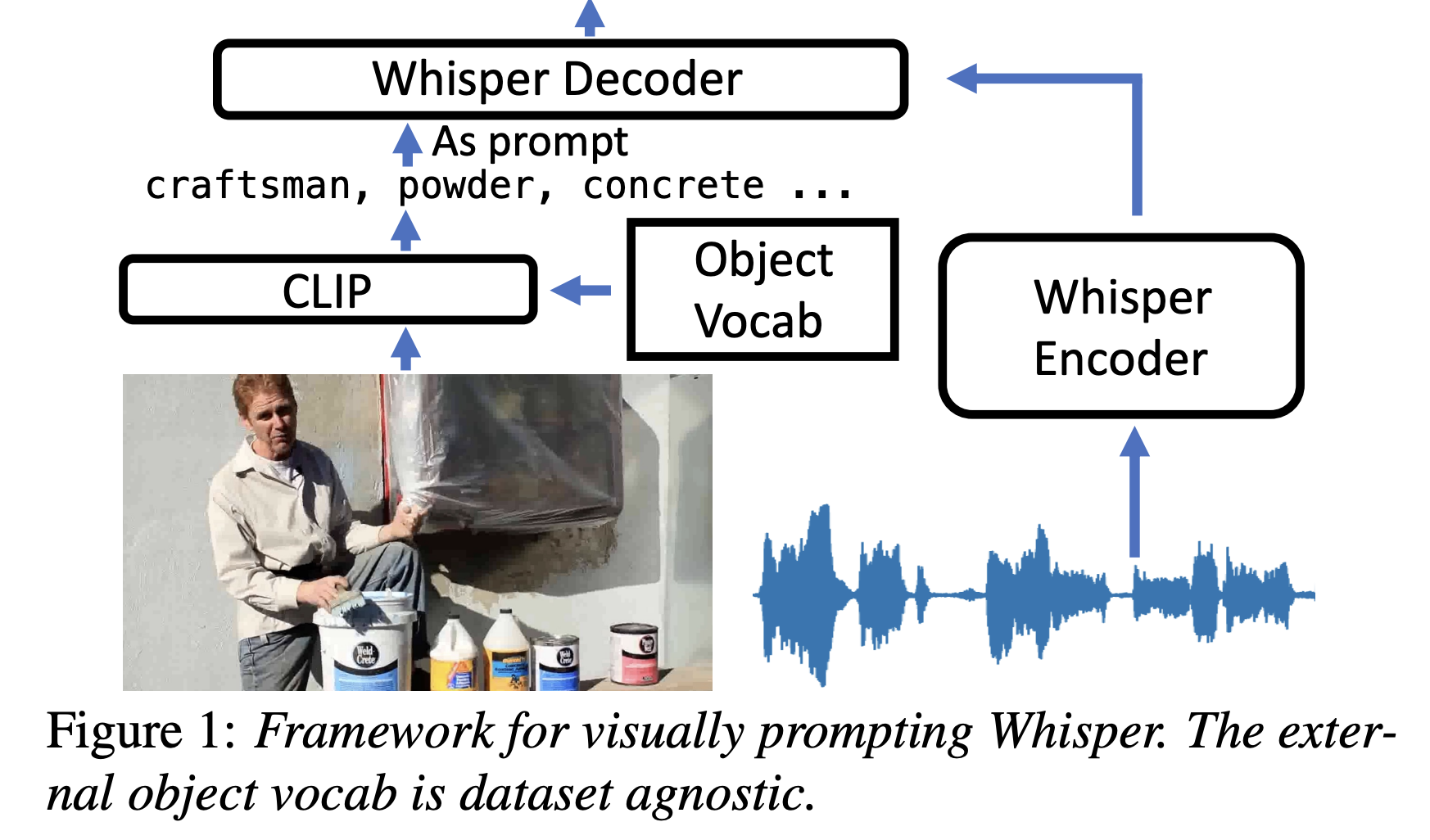
In a recently released research paper, a team of researchers discussed adapting the Whisper model to unseen tasks using simple prompts. Called PromptingWhisper, the main approach of the researchers has been to investigate the zero-shot task generalization abilities of the Whisper model by analyzing its strengths and weaknesses. For adapting Whisper to unseen tasks, the team has used prompt engineering to design task-specific prompts. They have mainly discussed three specific tasks, which are – audio-visual speech recognition (AVSR), code-switched speech recognition (CS-ASR), and speech translation (ST) involving unseen language pairs.
In AVSR, the team has found that Whisper exhibited a robust nature in terms of the length and noisiness of the visual prompt. Its efficiency for visual prompts in English models is different as compared to the multilingual models. In CS-ASR, some performance gaps were found between different accents. Lastly, in ST, it was found that the task token in the prompts could be effectively used to instruct the model to perform translation. To customize the prompts to the specific requirements of each task, the team has manipulated the special tokens within the default prompts provided by Whisper or used another large-scale model.
The team has conducted experiments to evaluate the performance of the Whisper model. After comparing the default prompts to their proposed task-specific prompts, the results showed that their prompts significantly improved performance across the three zero-shot tasks, with performance gains ranging from 10% to 45%. In some cases, the proposed prompts even outperformed the SOTA-supervised models on certain datasets.
In conclusion, the researchers have investigated the Whisper model in great depth. While evaluating, they observed how Whisper is robust to different prompts, efficiently uncovers biases related to accents, and identifies the model’s ability to understand multiple languages within its latent space. They have studied and analyzed Whisper’s hidden strengths and weaknesses in detail by focusing on the gradient-free zero-shot task generalization abilities of webscale speech models.
Check out the Paper and Code. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.