Meet ProtST: A Framework That Enhances Protein Sequence Pre-Training and Understanding By Biomedical Texts
Large Language Models have been able to dive into almost every domain. From Natural Language Processing and Natural Language Understanding to Computer vision, these models have incredible capabilities to provide solutions in every field of Artificial Intelligence. Developments in Artificial Intelligent and Machine Learning have shown how these Language Models can also be used for predicting the structure of protein and its functionality. Protein language models (PLMs), which are pre-trained on large-scale protein sequence datasets, have demonstrated abilities to enhance protein structure and function prediction.
Proteins being essential for biological growth and repairing and regeneration of cells, has significant applications in drug discovery and healthcare as well. Currently, existing PLMs only learn protein representations while recording co-evolutionary information based on protein sequences and do not include protein functions or other crucial characteristics like subcellular locations. These models lack explicit acquisition of protein functionalities.
For a number of proteins, textual property descriptions are available that provide insights into their important functions and properties. To dive more into this, a team of researchers has introduced ProtST, a framework to improve pre-training and comprehension of protein sequences using biomedical texts. The team has also developed a dataset called ProtDescribe, which combines protein sequences with text descriptions of their functions and other properties. The ProtST framework based on the ProtDescribe dataset aims to preserve the representation power of conventional PLMs in capturing co-evolutionary information during the process of pre-training.
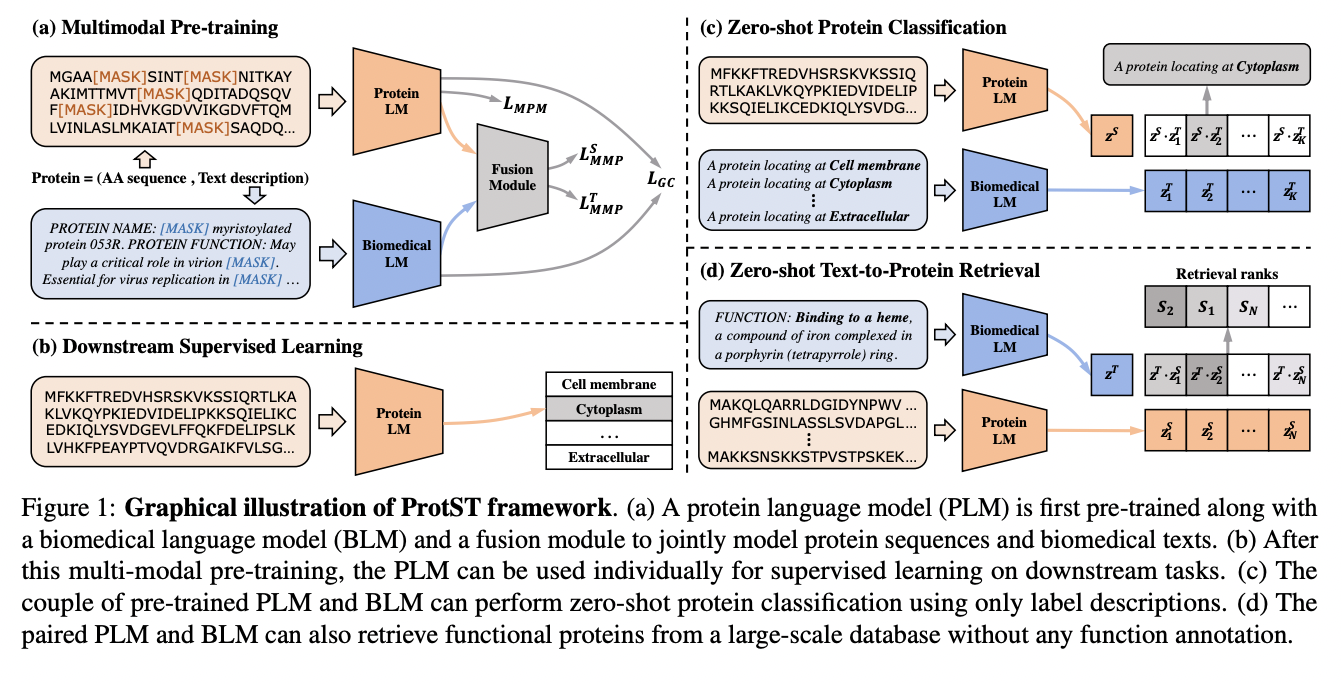
Three separate jobs have been created to add protein property data of various granularities to a PLM during the pre-training phase while maintaining the model’s initial representation power. First is Unimodal Mask Prediction, which aims to preserve the PLM’s capacity to record co-evolutionary information using masked protein modeling. The model is trained to anticipate the masked parts based on the surrounding context by masking certain regions in protein sequences, which makes sure that the PLM retains its ability to represent despite adding more property data.
The second is Multimodal Representation Alignment, in which protein sequences and their related text representations are lined up. Structured text representations of protein property descriptors are extracted using a biological language model, and following the alignment of the protein sequences to these text representations, the PLM is able to record the semantic relationship between the sequences and their textual descriptions.
In the third task, i.e., the Multimodal Mask Prediction, fine-grained dependencies between the residues in protein sequences and the words in the descriptions of the properties of the proteins are defined. To create multimodal representations of both residues and words, a fusion module is used to predict masked residues and words, and by doing this, the PLM is able to record the complex connections between protein sequences and the textual descriptions of their properties.
Upon evaluation, the team has found that to perform better on various representation learning benchmarks, supervised learning in ProtST makes use of the enriched protein representations. In these many representation learning challenges, ProtST-induced PLMs outperform earlier models. ProtST has shown good performance in zero-shot protein categorization in the zero-shot environment, as a result of which, even for classes that were not present during training, the trained model was able to classify proteins into several functional categories. ProtST also permits the retrieval of functional proteins from a sizable database without the need for function annotation.
In conclusion, this framework that enhances protein sequence pre-training and understanding with biomedical texts seems promising and a good addition to the advancements in AI.
Check out the Paper and Github link. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.