Meet PV3D: A Novel AI 3D Framework For Portrait Video Generation

Machine learning and artificial intelligence are living the best moments of their lives. With the recent release of huge models like Stable Diffusion and ChatGPT, the era of generative models has reached a very interesting point.
For instance, we can pose ChatGPT whatever question comes to our mind, and the network will answer us in a satisfying and exhausting way.
Another example related to multimedia is the generation of stunning images from an input text description. Diffusion models like Stable Diffusion or Dall-E are recent but already well-known for these applications.
The era of generative models is wider than diffusion models that, despite having incredible learning capabilities, are still computationally heavy even with optimizations and tricks such as using a latent space in the diffusing process.
Other models, like generative adversarial networks (GANs), have recently achieved impressive progress, which has led human portrait generation to unprecedented success and spawned many industrial applications.
Generating portrait videos has emerged as the next challenge for deep generative models with wider applications like video manipulation and animation. A long line of work has been proposed to either learn a direct mapping from latent code to portrait video or decompose portrait video generation into two stages, i.e., content synthesis and motion generation.
Despite offering plausible results, such methods only produce 2D videos without considering the underlying 3D geometry, which is the most desirable attribute with broad applications such as portrait reenactment, talking face animation, and VR/AR. Current methods typically create 3D portrait videos through classical graphics techniques, which require multi-camera systems, well-controlled studios, and heavy artist works.
In the work presented in this article, the goal is to alleviate the effort of creating high-quality 3D-aware portrait videos by learning from 2D monocular videos only, without the need for any 3D or multi-view annotations.
Recent 3D-aware portrait generative methods have witnessed rapid advances. Integrating implicit neural representations (INRs) into GANs can produce photo-realistic and multi-view consistent results.
However, such methods are limited to static portrait generation and can hardly be extended to portrait video generation due to several challenges. First, how to effectively model 3D dynamic human portraits in a generative framework remains to be discovered. Second, learning dynamic 3D geometry without 3D supervision is highly under-constrained. Third, entanglement between camera movements and human motions/expressions introduces ambiguities to the training process.
The overview of the architecture is presented in the figure below.
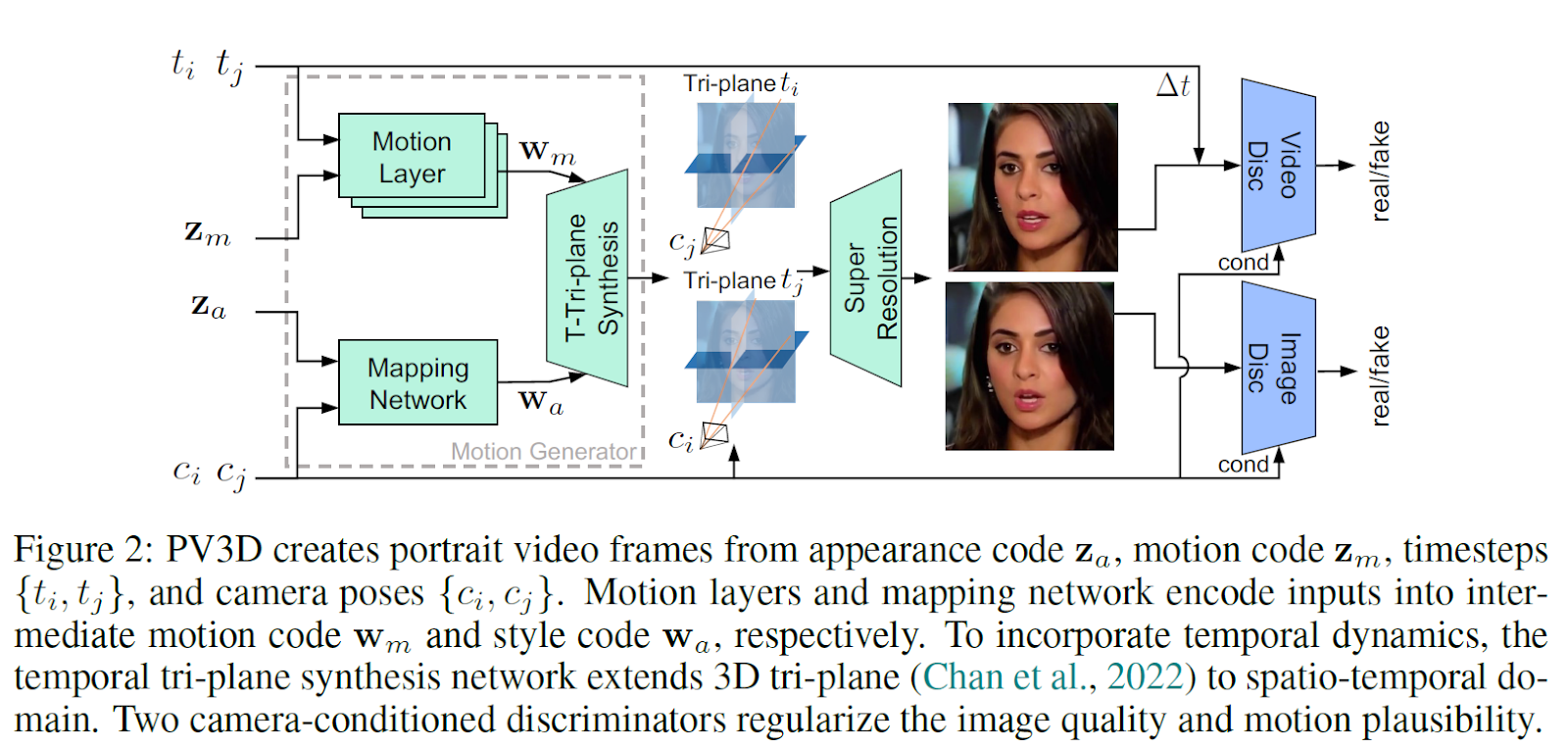
PV3D formulates the 3D-aware portrait video generation task as a generator and volume rendering function and considers parameters such as appearance code, motion code, timesteps, and camera poses.
The generator first generates a tri-plane representation using a pre-trained model and then extends it to a spatio-temporal representation for video synthesis, denoted as temporal tri-plane.
Instead of jointly modeling appearance and motion dynamics within a single latent code, the 3D video generation is divided into appearance and motion generation components, each encoded separately.
Video appearance involves characteristics such as gender, and skin color, while motion generation defines the motion dynamics expressed in the video, such as a person opening her mouth.
During training, timesteps and their corresponding camera poses are collected for each video. Following the tri-plane axis generation, the appearance code and camera pose are first projected into intermediate appearance codes for content synthesis. As for the motion component, a motion layer is designed to encode motion codes and timesteps into intermediate motion codes.
Following the output of the tri-plane representation, volume rendering is applied to synthesize frames with different camera poses.
The rendered frames are then upsampled and refined by a super-resolution module.
To ensure the fidelity and plausibility of the generated frame content and motion, two discriminators are exploited to supervise the training of the generator.
Despite being trained from only monocular 2D videos, PV3D can generate a large variety of photo-realistic portrait videos with diverse motions and high-quality 3D geometry under arbitrary viewpoints.
The figure reported below gives an example and comparison with state-of-the-art approaches.

This was the summary of PV3D, a novel AI framework to address the portrait video generation problem. If you are interested, you can find more information in the links below.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.