Meet Q-Align: The All-in-One Visual Scorer Based on Large Multi-Modality Models
With the vast amount of visual content available online, it is essential to assess images and videos accurately. The challenge is to develop robust machine assessment tools that can determine various types of visual content and align closely with human opinions. This need spans different domains, such as image and video quality assessment (IQA and VQA) and image aesthetic assessment (IAA), each requiring unique approaches to effectively rate and understand visual content.
Traditional methods, ranging from handcrafted algorithms to advanced deep-learning models, have focused on assessing visual content by regressing from mean opinion scores (MOS). However, these methods must be revised, particularly when dealing with new content types and diverse scoring scenarios. Their inadequacy largely stems from poor out-of-distribution generalization abilities, an issue that becomes increasingly prominent with the complexity and variety of modern visual content.
A breakthrough in this field is the introduction of Q-ALIGN, a novel methodology developed by researchers from Nanyang Technological University, Shanghai Jiao Tong University, and SenseTime Research. Q-ALIGN represents a departure from conventional approaches and educates Large Multi-Modality Models (LMMs) to rate visual content using text-defined rating levels, not direct numerical scores. This approach is more akin to how human raters evaluate and judge in subjective studies, marking a significant shift in machine-based visual assessment.
The methodology of Q-ALIGN is intricate and carefully designed. It converts existing score labels into discrete text-defined rating levels during the training phase. This process is analogous to how human raters learn and judge in subjective studies. They typically work with predefined levels like ‘excellent,’ ‘good,’ ‘fair,’ etc., rather than specific numerical scores. The innovation here is teaching LMMs to understand and use these text-defined levels for visual rating, which aligns more with human cognitive processes.
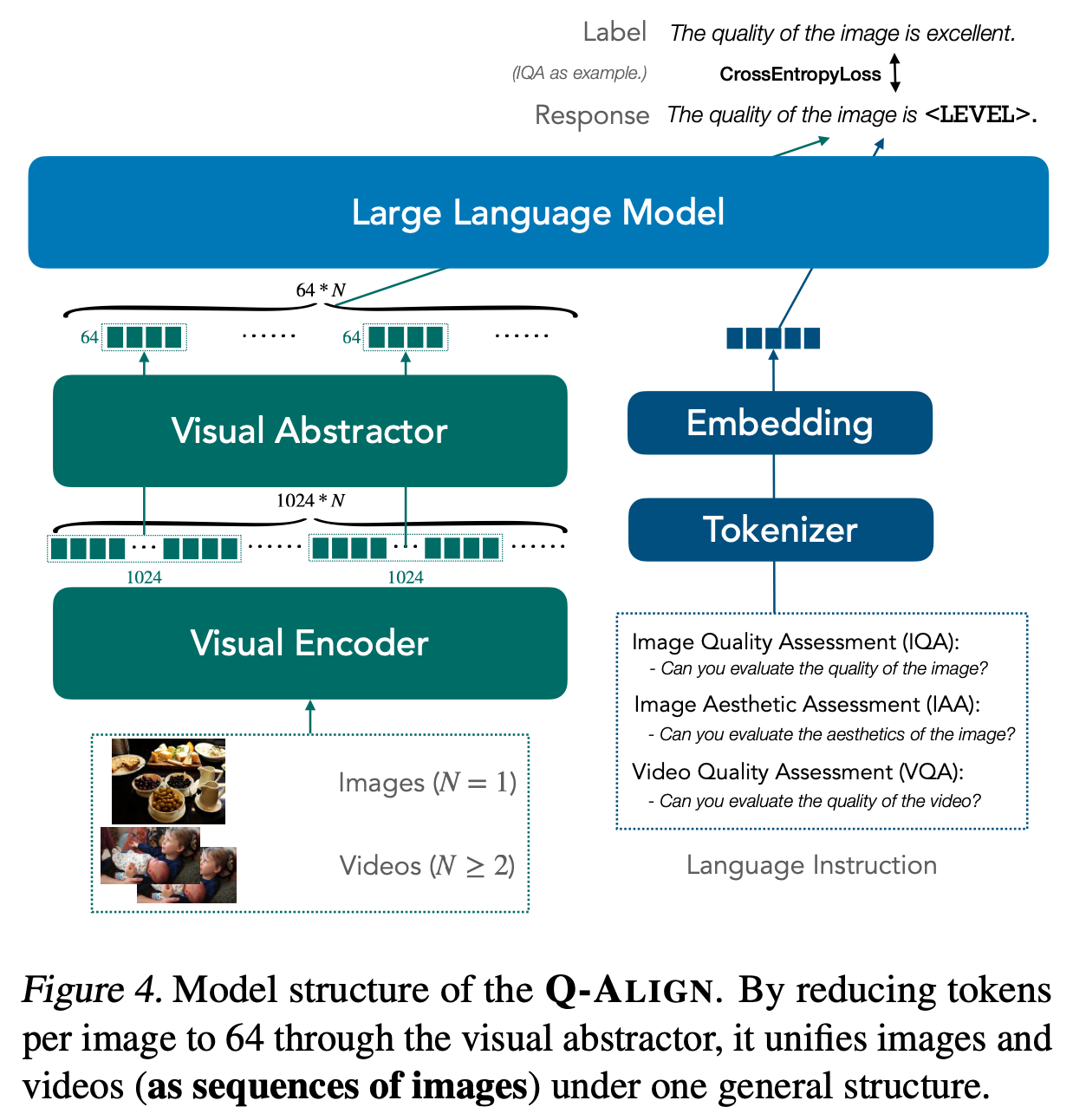
In the inference phase, Q-ALIGN emulates the strategy of collecting MOS from human ratings. It extracts the log probabilities on different rating levels and employs softmax pooling to obtain the close-set probabilities of each level. The final score is then derived from a weighted average of these probabilities. This process mirrors how human ratings are converted into MOS in subjective visual assessments.
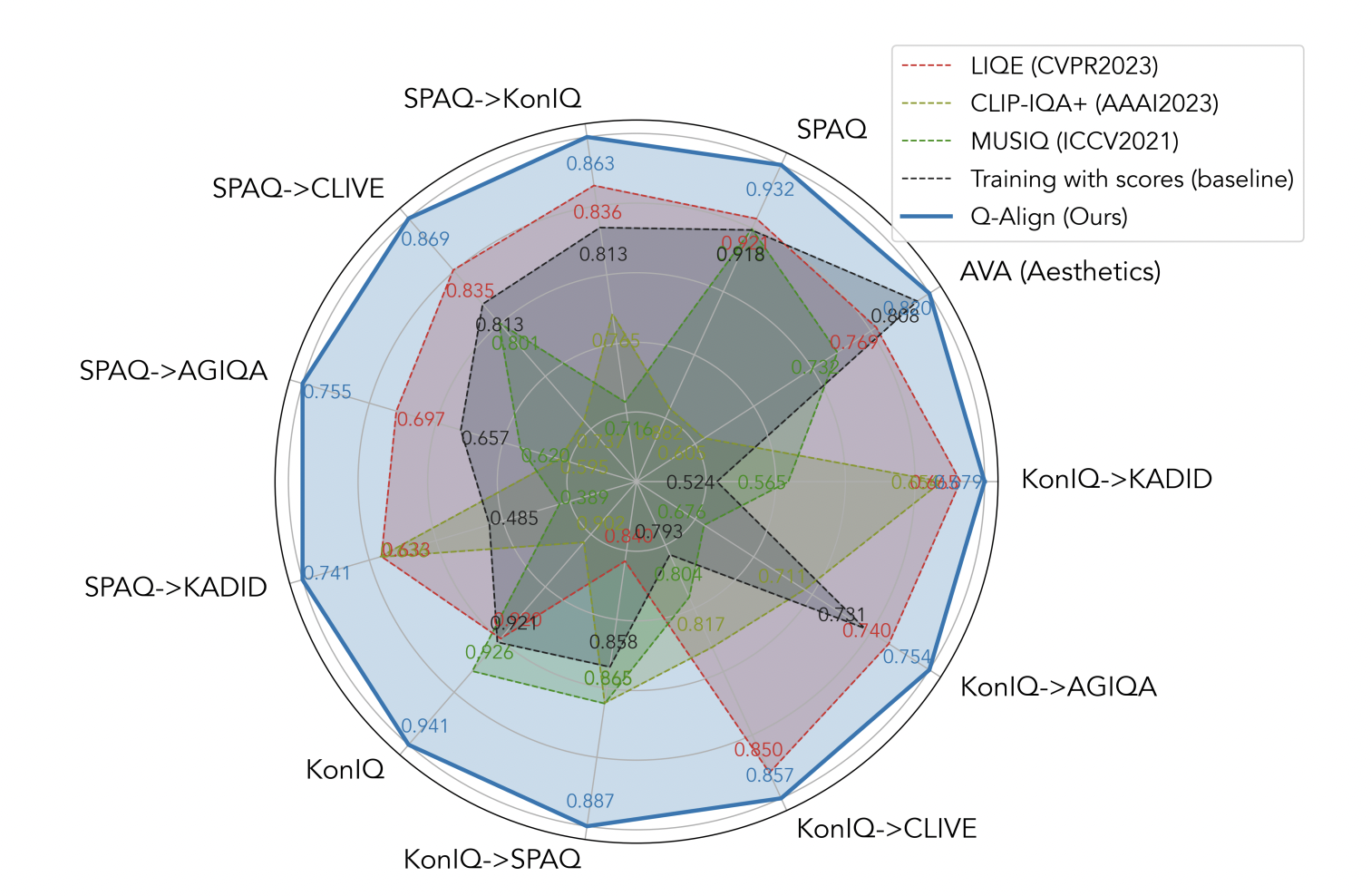
The performance and results of Q-ALIGN are noteworthy. It has achieved state-of-the-art performance in IQA, IAA, and VQA tasks. Compared to existing methods that struggle with novel content types and diverse scoring scenarios, Q-ALIGN’s discrete-level-based syllabus has shown superior performance, especially in out-of-distribution settings. These results indicate its effectiveness in accurately assessing a wide range of visual content.
Q-ALIGN’s ability to generalize effectively to new types of content underlines its potential for broad application across various fields. It represents a paradigm shift in the domain of visual content assessment. Adopting a methodology that aligns more closely with human judgment offers a robust, accurate, and more intuitive tool for scoring diverse types of visual content. The work addresses the limitations of existing methods and opens up new possibilities for future advancements in the field.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.
Credit: Source link
Comments are closed.