Meet RAP and LLM Reasoners: Two Frameworks Based on Similar Concepts for Advanced Reasoning with LLMs
Each passing day brings remarkable progress in Large Language Models (LLMs), leading to groundbreaking tools and advancements. These LLMs excel in various tasks, including text generation, sentiment classification, text classification, and zero-shot classification. Their capabilities extend beyond these areas, enabling automation of content creation, customer service, and data analysis, thereby revolutionizing productivity and efficiency.
Recently, the researchers have also started exploring the use and utility of LLMs for reasoning. These models can comprehend complex textual information and draw logical inferences from it. LLMs excel in tasks like question-answering, problem-solving, and decision-making. However, LLMs still cannot work like humans struggling with problems that would be easy for humans, such as generating action plans for executing tasks in a given environment or performing complex mathematical, logical, and commonsense reasoning. LLMs struggle with certain tasks because they don’t have an internal world model like humans do. This means they can’t predict how things will be in a given situation or simulate long-term outcomes of actions. Humans possess an internal world model, a mental representation of the environment, which enables humans to simulate actions and their effects on the world’s state for deliberate planning during complex tasks.
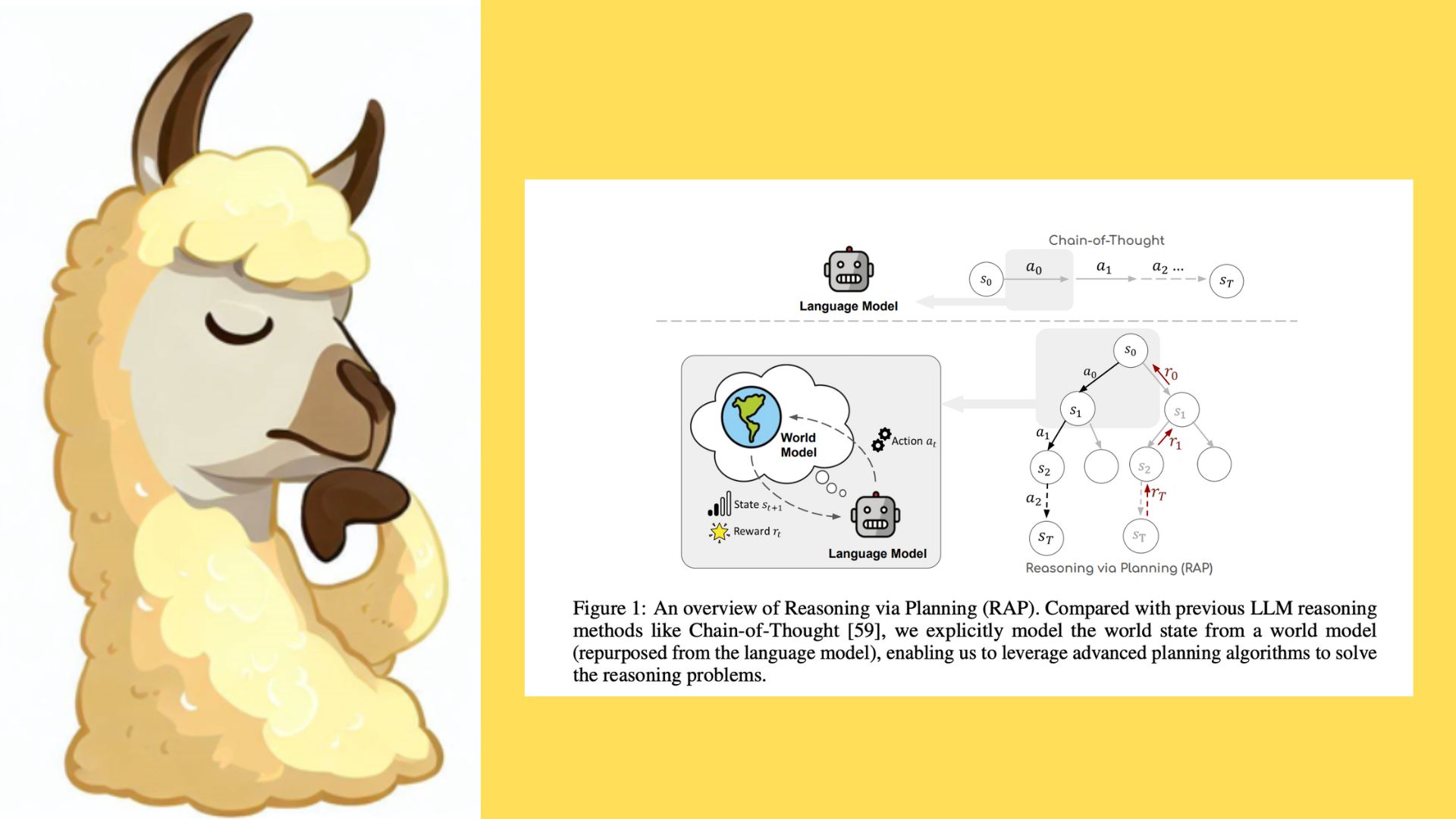
To overcome these issues, researchers have devised a new reasoning framework, Reasoning via Planning (RAP). This framework uses a library that enables LLMs to perform complex reasoning using advanced reasoning algorithms. This framework approaches multi-step reasoning methodology as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs. exploitation with the idea of “World Model” and “Reward.” Apart from the RAP paper, the research team also proposes LLM Reasoners. LLM Reasoners is an AI library designed to equip Language Models (LLMs) with the capability to carry out intricate reasoning through advanced algorithms. It perceives multi-step reasoning as planning, searching for the most efficient reasoning chain, and optimizing the balance between exploration and exploitation using the concepts of ‘World Model’ and ‘Reward’. All you need to do is define a reward function and, optionally, a world model. The LLM Reasoners handle the rest, encompassing Reasoning Algorithms, Visualization, LLM invocation, and more!
A world model regards the partial solution as the state and simply appends a new action/thought to the state as the state transition. The reward function is crucial in evaluating how well a reasoning step performs. The idea is that a reasoning chain with a higher accumulated reward is more likely to be correct.
The researchers performed extensive research on this framework. They applied RAP to several challenging reasoning problems on mathematical reasoning and logical inference. The practical results of these tasks show that RAP outperforms several strong baseline methods. When applied to LLaMA33B, RAP surpasses CoT on GPT-4, achieving an impressive 33% relative improvement in plan generation.
During the reasoning process, the LLM cleverly constructs a reasoning tree by continuously evaluating the best possible reasoning steps (actions). To do this, it uses its world model, which is the same LLM used in a different way. By simulating future outcomes, the LLM estimates potential rewards and uses this information to update its beliefs about the current reasoning steps. This way, it refines its reasoning by exploring better alternatives and improving its decisions. This framework offers cutting-edge reasoning algorithms, provides intuitive visualization and Interpretation, and is compatible with any other LLM libraries.
The researchers emphasize that after conducting extensive experiments on various challenging reasoning problems, RAP’s superiority over several contemporary CoT-based reasoning approaches was concluded. The framework even performed better than advanced GPT-4 in certain settings. The flexibility of RAP in designing rewards, states, and actions showcases its potential as a versatile framework for tackling various reasoning tasks. It’s fascinating to see how RAP combines planning and reasoning in an innovative way. This approach can potentially revolutionize how we approach LLM reasoning, paving the way for AI systems to achieve human-level strategic thinking and planning.
Check out the RAP Paper, LLM Reasoners Project Page, and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.