Meet RAVEN: A Retrieval-Augmented Encoder-Decoder Language Model That Addresses The Limitations Of ATLAS
Large language models (LLMs) have played a significant role in recent developments in the field of Natural Language Processing (NLP). These models have demonstrated amazing abilities across a wide range of tasks and have significantly boosted the popularity of Artificial Intelligence. Their ability to learn in context is a critical component of their greatness as by utilizing the contextual information that is offered, in-context learning enables these LLMs to adapt to new activities and domains without the need for task-specific fine-tuning. With the help of that, LLMs have also been able to excel in situations involving zero-shot or few-shot learning, where only a small number of examples are available.
Recent research has studied the potential of in-context learning in retrieval-augmented encoder-decoder language models. The capabilities of the cutting-edge ATLAS model have been studied, and their limitations have been pinpointed, which primarily include how the pretraining and testing phases of the model are out of sync and how the amount of contextual information that can be processed is confined.
To address that, a team of researchers from the University of Illinois at Urbana-Champaign, USA, and NVIDIA, USA, has introduced a unique paradigm named RAVEN, a retrieval-augmented encoder-decoder language model. This model has addressed the difficulties presented by ATLAS, and in order to improve its capacity for in-context learning, RAVEN employs a two-pronged strategy. The first part combines prefix language modeling and retrieval-augmented masked language modeling methods. These techniques seek to improve the model’s comprehension of and production of contextually relevant content by minimizing the difference between pretraining and testing data.
Secondly, RAVEN has introduced an improvement which is referred to as Fusion-in-Context Learning. The goal of this method is to enhance the model’s performance in few-shot scenarios and is notable for its ability to increase the amount of in-context examples the model can use without requiring further model modifications or training repetitions. This is essential because it enables the model to more effectively and efficiently use contextual information.
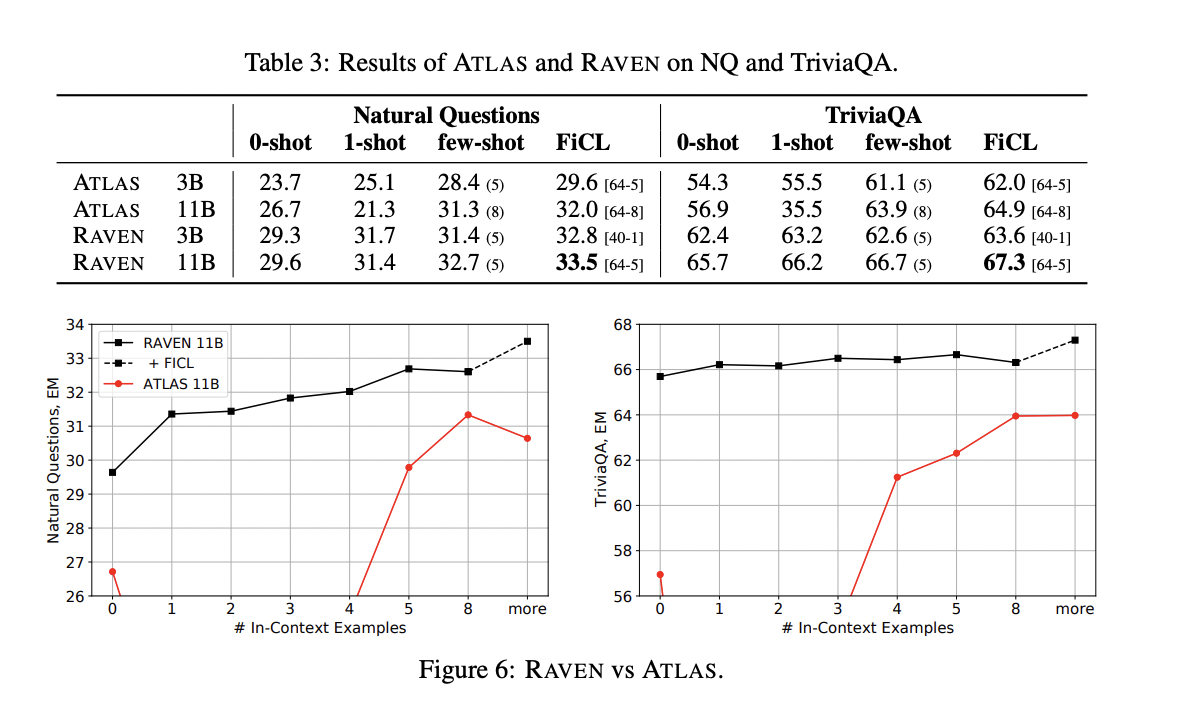
The research’s experimental phase entails a number of extensive testing and evaluations., which have been carried out to assess how RAVEN performs in comparison to the ATLAS model. The results demonstrate that RAVEN greatly outperforms ATLAS in terms of its comprehension of context and capacity to produce precise responses. While using substantially fewer parameters, RAVEN sometimes produces results that are on par with those of the most sophisticated language models.
The team has summarized their contributions as follows.
- ATLAS has been thoroughly studied, focusing on its in-context learning ability.
- RAVEN, a novel model constructed by integrating retrieval-augmented masked and prefix language modeling techniques, has been introduced, which aims to address the limitations identified in ATLAS.
- Fusion-in-Context Learning and In-Context Example Retrieval have been proposed to bolster the few-shot performance of retrieval-augmented encoder-decoder models like RAVEN. These methods allow improved utilization of context without major modifications or extra training.
- Through extensive experiments, the research has validated RAVEN’s effectiveness and the proposed techniques, where the results have demonstrated RAVEN’s superior performance across various scenarios, surpassing ATLAS and other baseline models.
In conclusion, this work highlights how retrieval-augmented encoder-decoder language models, like RAVEN, have the potential to improve in-context learning capacities.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.