Meet REPLUG: a Retrieval-Augmented Language Modeling LM Framework that Combines a Frozen Language Model with A Frozen/Tunable Retriever Improving the Performance of GPT-3 (175B) on Language Modeling by 6.3%
In recent years, language models have become one of the fastest-growing fields in Artificial Intelligence. These models, which have been developed to process and produce natural language text, are driving some of the most innovative and ground-breaking AI applications and are at the forefront of a new era in AI expansion. One language model in particular, GPT-3, has caused a buzz worldwide due to its extraordinary capabilities and performance. GPT-3 uses a transformer architecture to process text, resulting in a model that can easily answer questions as a human would. Not only this, the model is even capable of summarizing long paragraphs, finishing codes, and completing tasks with unmatched speed and accuracy.
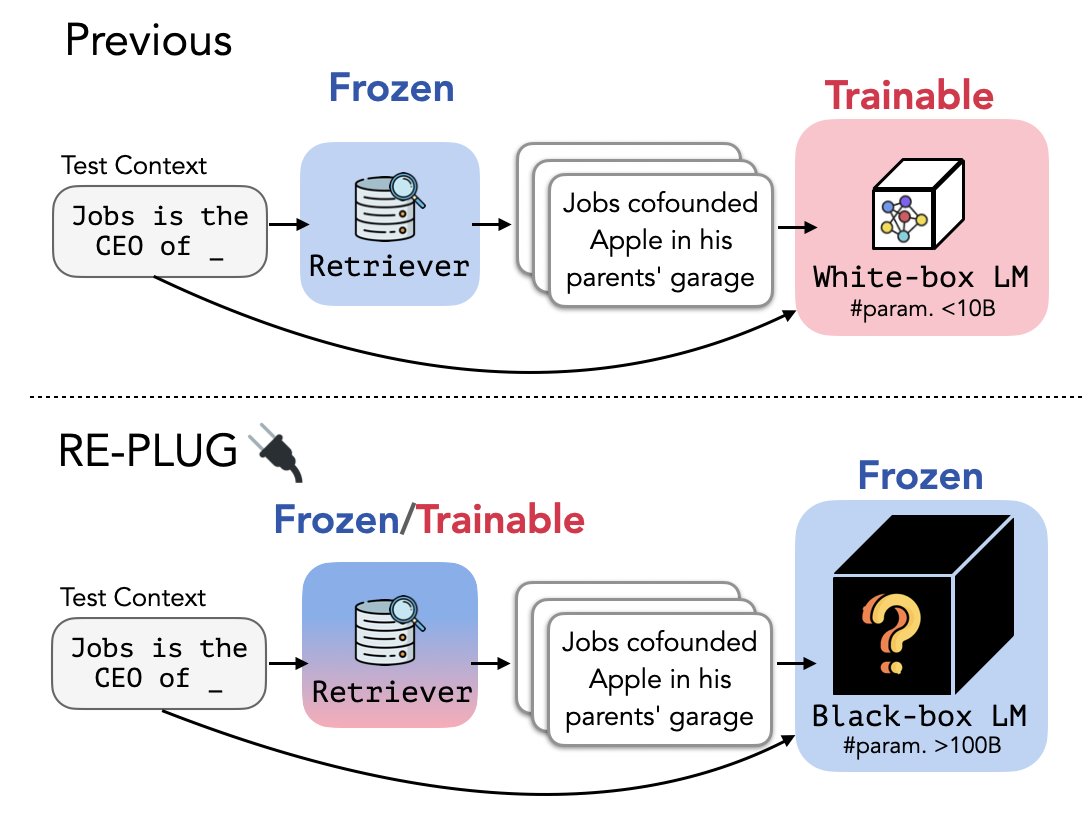
Language models like GPT-3 are still distant from perfect and have limitations when it comes to generating precise and appropriate responses to new prompts. This is where REPLUG comes in. A new method called REPLUG has been introduced: a retrieval-augmented Language Model framework. It is a method for improvising the performance of black-box language models by merging them with a retrieval-based structure. The retrieval system finds the most appropriate passages in a large corpus of text that match a given prompt, and then the language model is tweaked on the retrieved passages. This allows the language model to produce more accurate answers, especially when the prompt is unseen in its training data.
The REPLUG method consists of two primary steps – document retrieval and input reformulation. First, a retriever is used to identify related documents from an external corpus. Then, each retrieved document is distinctly added to the original input context, and the output probabilities are combined from several passes. This approach uses a deep neural network that powers attention mechanisms to learn the networks between the different modalities.
👉 Read our latest Newsletter: Microsoft’s FLAME for spreadsheets; Dreamix creates and edit video from image and text prompts……
REPLUG was tested on various benchmark datasets, including a large image captioning dataset, and showed better results compared to existing systems in terms of accuracy and scalability. One of the key advantages of REPLUG is that it does not require any alteration to the underlying language model architecture. Current models like GPT-3 can be enhanced by adding a retrieval system. This makes REPLUG easy to access and implement. REPLUG with the tuned retriever significantly improves the performance of GPT-3 (175B) on language modeling by 6.3%, as well as the performance of Codex on five-shot MMLU by 5.1%.
Consequently, the introduction of REPLUG seems like a game changer in the field of NLP. It combines the strengths of both black-box language models and retrieval systems to generate a hybrid model that outperforms traditional language models. The deep neural network architecture used by REPLUG is scalable, making it appropriate for real-world applications that require processing huge sums of multi-modal data. The potential applications for REPLUG are definitely massive and seem promising in the coming future.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.