Meet RLPrompt: A New Prompt Optimization Approach with Reinforcement Learning (RL)
Prompting is a promising approach to solving NLP problems with pre-trained language models (LMs) such as GPTs and BERT. Unlike conventional fine-tuning that updates the massive LM parameters for each downstream task, prompting concatenates inputs with additional text to steer the LM towards producing the desired outputs. A key question is finding optimal prompts to improve the LM’s performance on various tasks with few training examples.
Reinforcement Learning (RL) for prompt optimization challenges learning efficiency as the large black-box language model navigates a complex environment involving multiple transitions before computing rewards. This complexity makes it challenging to learn from the unstable reward signals. However, to overcome this, we propose two simple but effective strategies. Firstly, normalizing the training signal by computing the z-score of rewards for the same input can stabilize the reward signals. Secondly, designing piecewise reward functions that offer sparse, qualitative bonuses for desirable behaviors, such as achieving a certain accuracy on a specific class, can improve optimization efficiency.
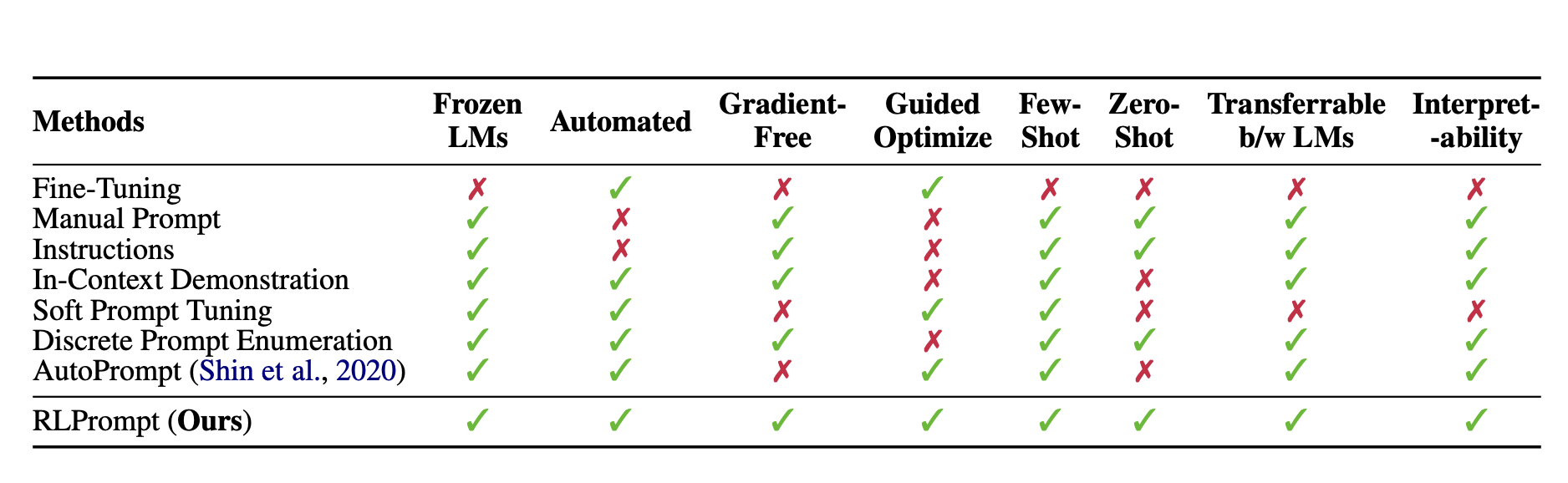
Existing work relies on soft prompt tuning that needs more interpretability, reusability, and applicability in the absence of gradients. Discrete prompt optimization is complex, and heuristics such as paraphrasing and selection must be more systematic. In the latest research paper, researchers from CMU and UCSD propose RLPrompt, an efficient discrete prompt optimization approach using reinforcement learning (RL) applicable to different LMs for classification and generation tasks.
Experiments show superior performance over finetuning or prompting methods for few-shot classification and unsupervised text style transfer. Interestingly, optimized prompts often consist of ungrammatical gibberish text, which shows LMs may have understood common frameworks for prompting, but they do not adhere to human language norms.
What’s new
This paper introduces RLPrompt, a new approach to prompt optimization that utilizes reinforcement learning (RL). This method combines desirable properties for optimizing prompts across different tasks and language models.
Instead of editing the discrete tokens directly, which has proven difficult and inefficient, RLPrompt employs a policy network that generates the desired prompts. Learning a small number of policy parameters enables discrete prompt optimization by inserting them as an MLP layer into a frozen compact model like distilGPT-2.
This formulation also enables off-the-shelf RL algorithms (such as soft Q-learning) that learn the policy with arbitrary reward functions. These reward functions can be defined with available data, such as in few-shot classification, or with other weak signals when supervised data is not accessible, like in controllable text generation.
The study found that strongly optimized prompts are less coherent but transferable between language models, resulting in a remarkable performance. This observation opens up new and promising possibilities for prompting, such as learning cheap prompts from smaller models and performing inferences with larger ones.
However, the limitations and potential drawbacks of RLPrompt are yet to be explored, and it is uncertain whether it is a suitable method for all types of applications. Further research is needed to fully understand the strengths and weaknesses of RLPrompt.
Check out the Paper, Github, and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.