Meet ‘SegNeXt,’ A simple Convolutional Neural Network Architecture For Semantic Segmentation
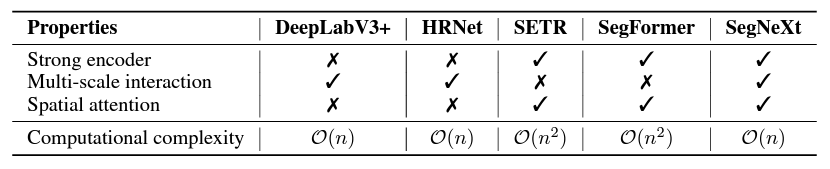
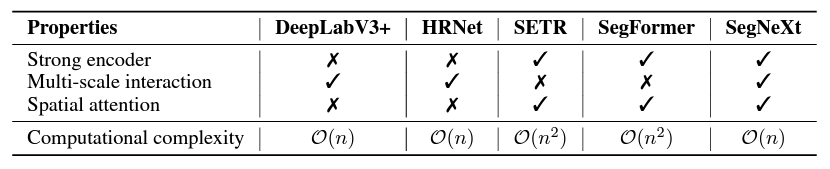
Semantic segmentation, which tries to give a semantic category to each pixel, has gotten a lot of interest in the last decade as one of the most fundamental research areas in computer vision. From early CNN-based models, such as the FCN and DeepLab series, to more modern transformer-based approaches, such as SETR and SegFormer, semantic segmentation models have seen substantial network architectural change. They outline various critical features different models contain by revisiting prior successful semantic segmentation research, as shown in the Table below.
Based on the above observations, they contend that an effective semantic segmentation model should have the following characteristics:
- A robust backbone network serves as the encoder: The performance gain of transformer-based models over prior CNN-based models is primarily due to a better backbone network.
- Information exchange at several scales: In contrast to image classification, which mainly recognizes a single item, semantic segmentation is a dense prediction job that must handle objects of varied sizes in a single image.
- Spatial awareness: Models can do segmentation using spatial attention by prioritizing locations inside semantic regions.
- The computational complexity is low: It is essential when working with photos and urban landscapes of high-resolution remote sensing.
Considering the initial study, they rethink the design of convolutional attention in this article and offer an efficient but effective encoder-decoder architecture for semantic segmentation. In contrast to prior transformer-based models that used decoder convolutions as feature refiners, their solution inverts the transformer-convolution encoder-decoder architecture. They refurbish the architecture of typical convolutional blocks and use multi-scale convolutional features. This inspires spatial attention using a simple element-wise multiplication following for each block in their encoder. They discovered that this primary method of constructing spatial awareness is more efficient than ordinary convolutions and self-attention in spatial information encoding.
Their SegNeXt network comprises convolutional processes, except the decoder, which includes a decomposition-based Hamburger module (Ham) for global information extraction. They gather multi-level information from several stages for the decoder and utilize Hamburger to extract global context. Their technique may get multi-scale context from local to international, accomplish adaptation in geographical and channel dimensions, and aggregate information from low to high levels in this context. As a result, their SegNeXt is far more efficient than earlier segmentation approaches that relied mainly on transformers.

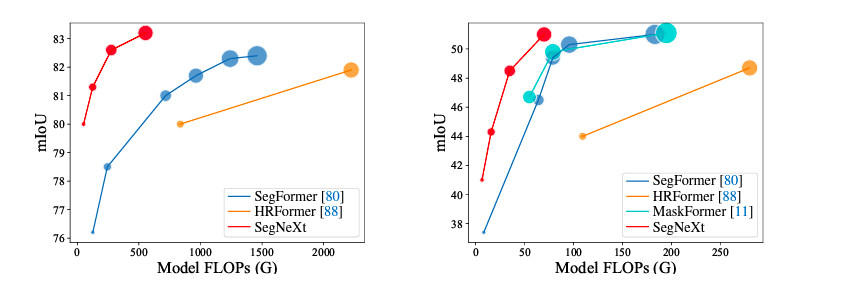
As seen in the figure above, SegNeXt significantly outperforms current transformer-based techniques. When dealing with high-resolution urban images from the Cityscapes dataset, their SegNeXt-S surpasses SegFormer-B2 requiring only roughly 1/6 computational cost and 1/2 parameters. Their contributions are listed below:
• They identify the qualities of a successful semantic segmentation model and introduce SegNeXt, a unique customized network architecture that stimulates spatial attention through multi-scale convolutional features.
• They demonstrate that an encoder using basic and inexpensive convolutions may outperform vision transformers, mainly when processing object details, while requiring far less computing cost.
• On numerous segmentation benchmarks, including ADE20K, Cityscapes, COCO-Stuff, Pascal VOC, Pascal Context, and iSAID, their technique outperforms state-of-the-art semantic segmentation methods by a wide margin.
Official Pytorch implementations of SegNext training and evaluation algorithms, as well as pre-trained models, are freely available on GitHub.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.