Meet SEINE: a Short-to-Long Video Diffusion Model for High-Quality Extended Videos with Smooth and Creative Transitions Between Scenes
Given the success of diffusion models in text-to-image generation, a surge of video generation techniques has emerged, showcasing interesting applications in this realm. Nevertheless, most video generation techniques often produce videos at the “shot-level,” enclosing only a few seconds and portraying a single scene. Given the brevity of the content, these videos are clearly unable to meet the requirements for cinematic and film productions.
In cinematic or industrial-level video productions, “story-level” long videos are typically characterized by the creation of distinct shots featuring different scenes. These individual shots, varying in length, are interconnected through techniques such as transitions and editing, facilitating longer videos and more intricate visual storytelling. Combining scenes or shots in film and video editing, known as transition, plays a pivotal role in post-production. Traditional transition methods, such as dissolves, fades, and wipes, rely on predefined algorithms or established interfaces. However, these methods lack flexibility and are often constrained in their capabilities.
An alternative approach to seamless transitions involves using diverse and imaginative shots to switch from one scene to another in a smooth manner. This technique, commonly employed in films, cannot be directly generated using predefined programs.
This work introduces a model that addresses the less common problem of generating seamless and smooth transitions by focusing on generating intermediate frames between two different scenes.
The model demands the generated transition frames to be semantically relevant to the given scene image, coherent, smooth, and consistent with the provided text.
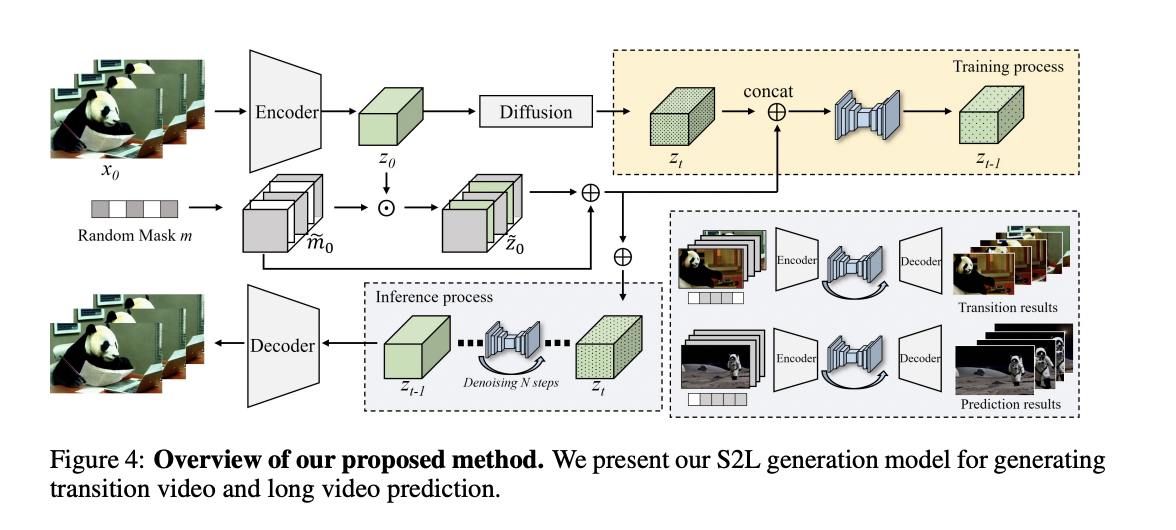
The presented work introduces a short-to-long video diffusion model, termed SEINE, for generative transition and prediction. The objective is to produce high-quality long videos with smooth and creative transitions between scenes, encompassing varying lengths of shot-level videos. An overview of the method is illustrated in the figure below.
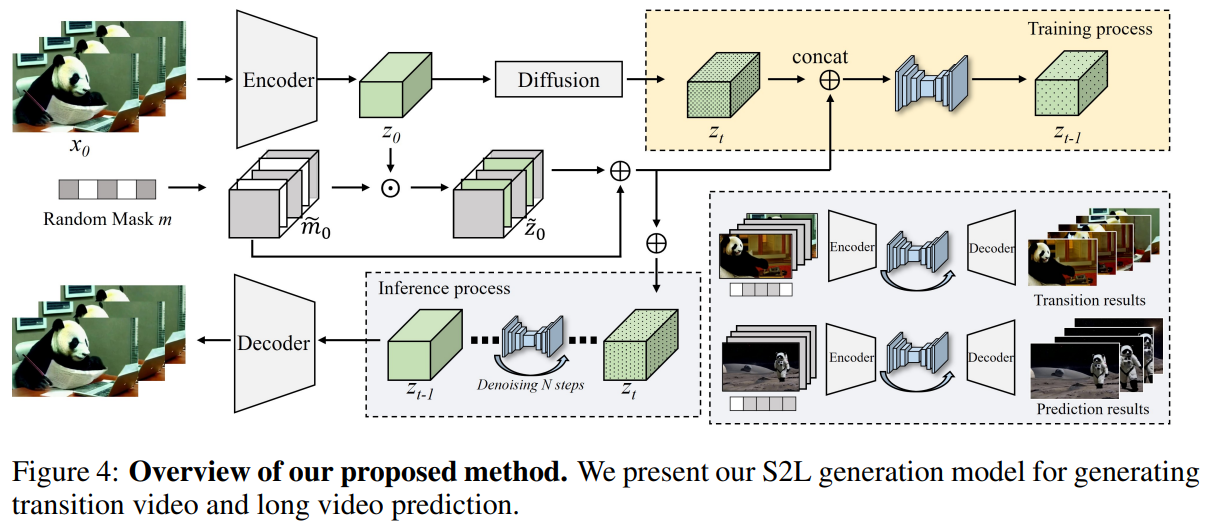
To generate previously unseen transition and prediction frames based on observable conditional images or videos, SEINE incorporates a random mask module. Based on the video dataset, the authors extract N-frames from the original videos encoded by a pre-trained variational auto-encoder into latent vectors. Additionally, the model takes a textual description as input to enhance the controllability of transition videos and exploit the capabilities of short text-to-video generation.
During the training stage, the latent vector undergoes corruption with noise, and a random-mask condition layer is applied to capture an intermediate representation of the motion between frames. The masking mechanism selectively retains or suppresses information from the original latent code. SEINE takes the masked latent code and the mask itself as conditional input to determine which frames are masked and which remain visible. The model is trained to predict the noise affecting the entire corrupted latent code. This entails learning the underlying distribution of the noise affecting both the unmasked frames and the textual description. Through modeling and predicting the noise, the model aims to generate transition frames that are realistic and visually coherent, seamlessly blending visible frames with unmasked frames.
Some sequences taken from the study are reported below.

This was the summary of SEINE, a short-to-long video diffusion model for generating high-quality extended videos with smooth and creative transitions between scenes. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.