Meet Spectformer: A Novel Transformer Architecture Combining Spectral And Multi-Headed Attention Layers That Improves Transformer Performance For Image Recognition Tasks
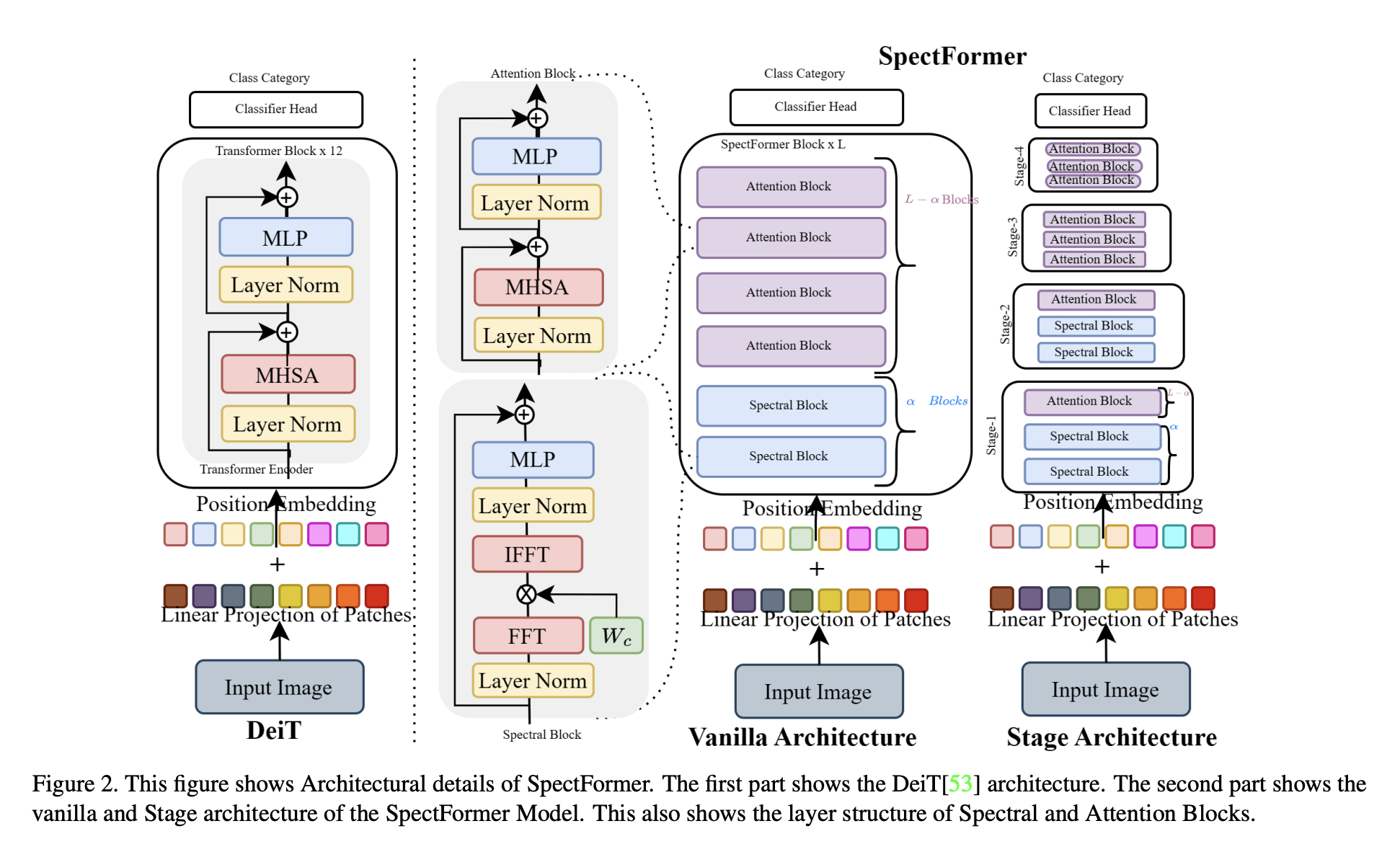
SpectFormer is a novel transformer architecture proposed by researchers from Microsoft for processing images using a combination of multi-headed self-attention and spectral layers. The paper highlights how SpectFormer’s proposed architecture can better capture appropriate feature representations and improve Vision Transformer (ViT) performance.
The first thing the study team looked at was how various combinations of spectral and multi-headed attention layers compare to models that only use attention or spectral models. The group came to the conclusion that the most promising results were obtained by the proposed design of SpectFormer, which included spectral layers initially implemented using the Fourier Transform and, afterward, multi-headed attention layers.
The SpectFormer architecture is made up of four basic parts: a classification head, a transformer block made up of a sequence of spectral layers followed by attention layers, and a patch embedding layer. The pipeline performs a frequency-based analysis of the image information and captures significant features by transforming picture tokens to the Fourier domain using a Fourier transform. The signal is then returned from spectral space to physical space using an inverse Fourier transform, learnable weight parameters, and gating algorithms.
The team used empirical validation to verify SpectFormer’s architecture and showed that it functions quite well in transfer learning mode on the CIFAR-10 and CIFAR-100 datasets. The scientists also demonstrated that object detection and instance segmentation tasks assessed on the MS COCO dataset yield consistent results using SpectFormer.
On a variety of object identification and picture classification tasks, the researchers in their study contrasted SpectFormer with multi-headed self-attention-based DeIT, parallel architecture LiT, and spectral-based GFNet ViTs. In the studies, SpectFormer surpassed all baselines and obtained top-1 accuracy on the ImageNet-1K dataset, which was 85.7% above current standards.
The results show that the suggested design of SpectFormer, which combines spectral and multi-headed attention layers, may more effectively capture suitable feature representations and enhance ViT performance. The results of SpectFormer offer hope for further study on vision transformers that combine both techniques.
The team has made two contributions to the field: first, they suggest SpectFormer, a novel design that blends spectral and multi-headed attention layers to enhance image processing efficiency. Second, they show the effectiveness of SpectFormer by validating it on multiple object detection and picture classification tasks and obtaining top-1 accuracy on the ImageNet-1K dataset, which is at the field’s cutting edge.
All things considered, SpectFormer offers a viable path for future study on vision transformers that combine spectral and multi-headed attention layers. The suggested design of SpectFormer might play a significant role in image processing pipelines with more investigation and validation.
Check out the Paper, Code, and Project Page. Don’t forget to join our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.