Meet SpQR (Sparse-Quantized Representation): A Compressed Format And Quantization Technique That Enables Near-Lossless Large Language Model Weight Compression
Large Language Models (LLMs) have demonstrated incredible capabilities in recent times. Learning from massive amounts of data, these models have been performing tasks with amazing applications, including human-like textual content generation, question-answering, code completion, text summarization, creation of highly-skilled virtual assistants, and so on. Though LLMs have been performing greatly, now there has been a shift toward developing smaller models trained on even more data. Smaller models require less computational resources as compared to the larger ones; for example, the LLaMA model having 7 billion parameters and trained on 1 trillion tokens, produces results that are 25 times better than those of the much bigger GPT-3 model despite being 25 times smaller.
Compressing the LLMs so that they fit into memory-limited devices, laptops, and mobile phones accompanies challenges such as difficulty in maintaining generative quality, accuracy degradation in 3 to 4-bit quantization techniques in models with 1 to 10 Billion parameters, etc. The limitations are due to the sequential nature of LLM generation, where little errors can add up to produce outputs that are seriously damaged, to avoid which it is important to design low-bit-width quantization methods that do not reduce predictive performance compared to the original 16-bit model.
To overcome the accuracy limitations, a team of researchers has introduced Sparse-Quantized Representation (SpQR), a compressed format and quantization technique. This hybrid sparse-quantized format enables nearly lossless compression of precise pretrained LLMs down to 3–4 bits per parameter. It is the first weight quantization technique to achieve such compression ratios with an end-to-end accuracy error of less than 1% in comparison to the dense baseline, as evaluated by perplexity.
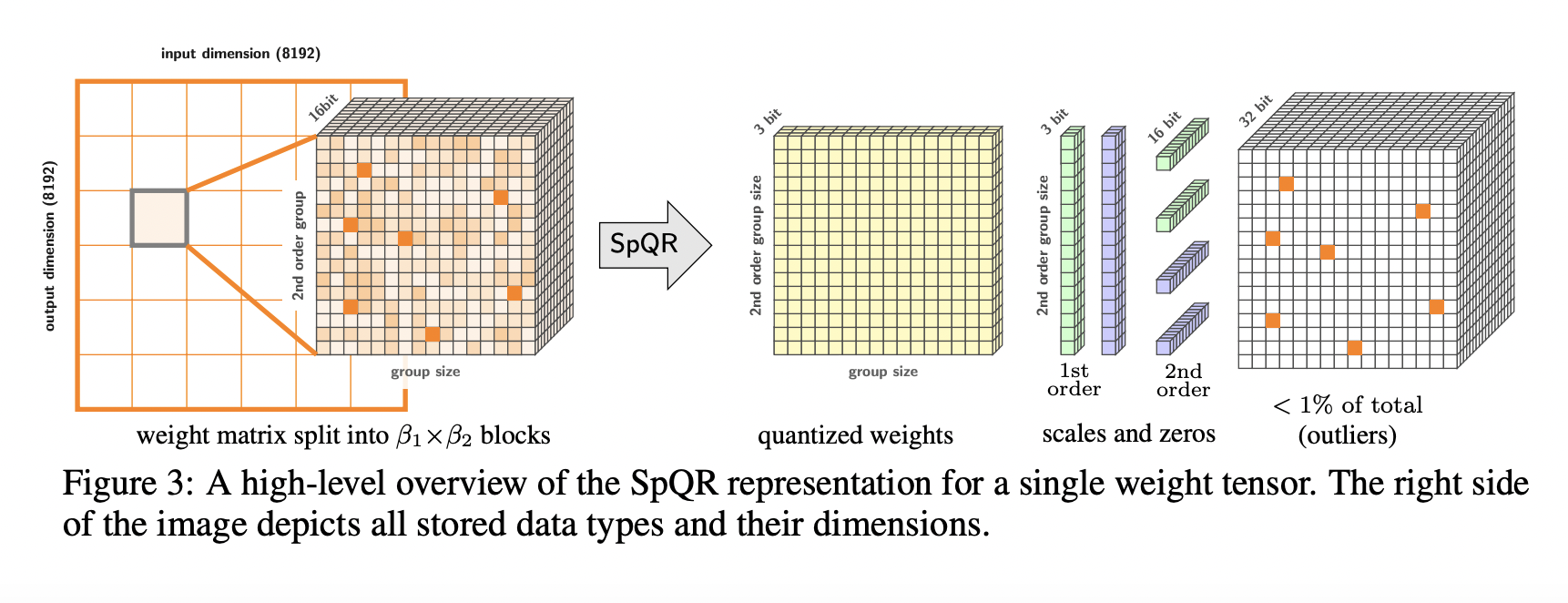
SpQR makes use of two ways. Firstly, it begins by locating outlier weights that, when quantized, give excessively high errors, and these weights are stored in high precision, while the remaining weights are stored in a much lower format, typically 3 bits. Secondly, SpQR employs a variant of grouped quantization with very small group size, such as 16 contiguous elements, and even the quantization scales themselves can be represented in a 3-bit format.
For converting a pretrained LLM into the SpQR format, the team has adopted an extended version of the post-training quantization (PTQ) approach, which, inspired by GPTQ, passes calibration data through the uncompressed model. SpQR allows for running 33 billion parameter LLMs on a single 24 GB consumer GPU without any performance degradation while providing a 15% speedup at 4.75 bits. This makes powerful LLMs accessible to consumers without suffering from any performance penalties.
SpQR offers effective methods for encoding and decoding weights into their format at runtime. These algorithms are made to maximize the SpQR memory compression advantages. A powerful GPU inference algorithm has also been created for SpQR, enabling faster inference than 16-bit baselines while maintaining comparable levels of accuracy. Because of this, SpQR provides memory compression benefits of more than 4x, making it very effective for use on devices with limited memory. In conclusion, SpQR seems like a promising technique as it efficiently addresses the challenge of accuracy loss associated with low-bit quantization in LLMs.
Check Out The Paper and Github. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.