Meet StableSR: A Novel AI Super-Resolution Approach Exploiting the Power of Pre-Trained Diffusion Models
Significant progress has been observed in the development of diffusion models for various image synthesis tasks in the field of computer vision. Prior research has illustrated the applicability of the diffusion prior, integrated into synthesis models like Stable Diffusion, to a range of downstream content creation tasks, including image and video editing.
In this article, the investigation expands beyond content creation and explores the potential advantages of employing diffusion priors for super-resolution (SR) tasks. Super-resolution, a low-level vision task, introduces an additional challenge due to its demand for high image fidelity, which contrasts with the inherent stochastic nature of diffusion models.
A common solution to this challenge entails training a super-resolution model from the ground up. These methods incorporate the low-resolution (LR) image as an additional input to constrain the output space, aiming to preserve fidelity. While these approaches have achieved commendable results, they often require substantial computational resources for training the diffusion model. Furthermore, initiating network training from scratch can potentially compromise the generative priors captured in synthesis models, potentially leading to suboptimal network performance.
In response to these limitations, an alternative approach has been explored. This alternative involves introducing constraints into the reverse diffusion process of a pre-trained synthesis model. This paradigm eliminates the need for extensive model training while leveraging the benefits of the diffusion prior. However, it’s worth noting that designing these constraints assumes prior knowledge of the image degradations, which is typically both unknown and intricate. Consequently, such methods demonstrate limited generalizability.
To address the mentioned limitations, the researchers introduce StableSR, an approach designed to retain pre-trained diffusion priors without requiring explicit assumptions about image degradations. An overview of the presented technique is illustrated below.
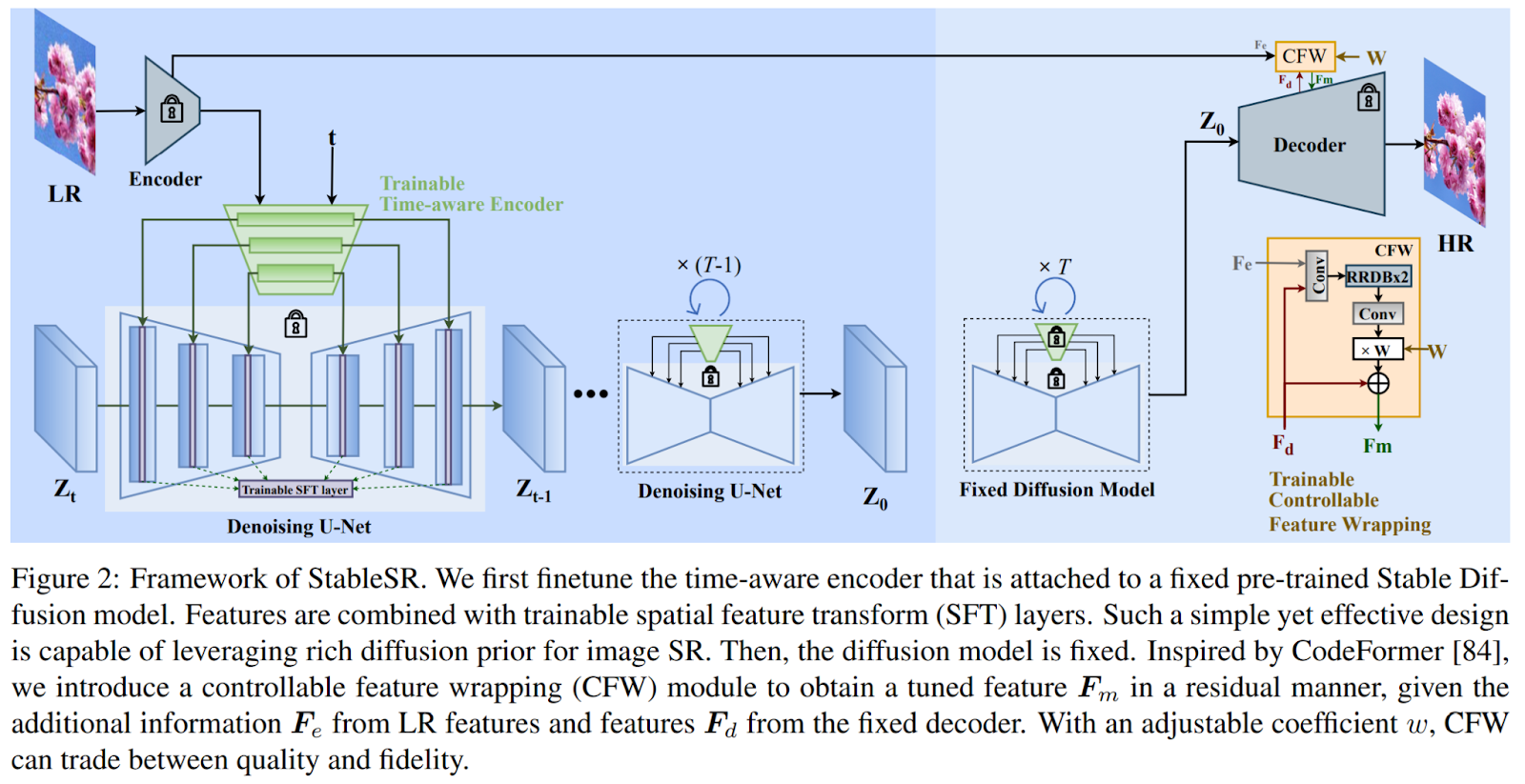
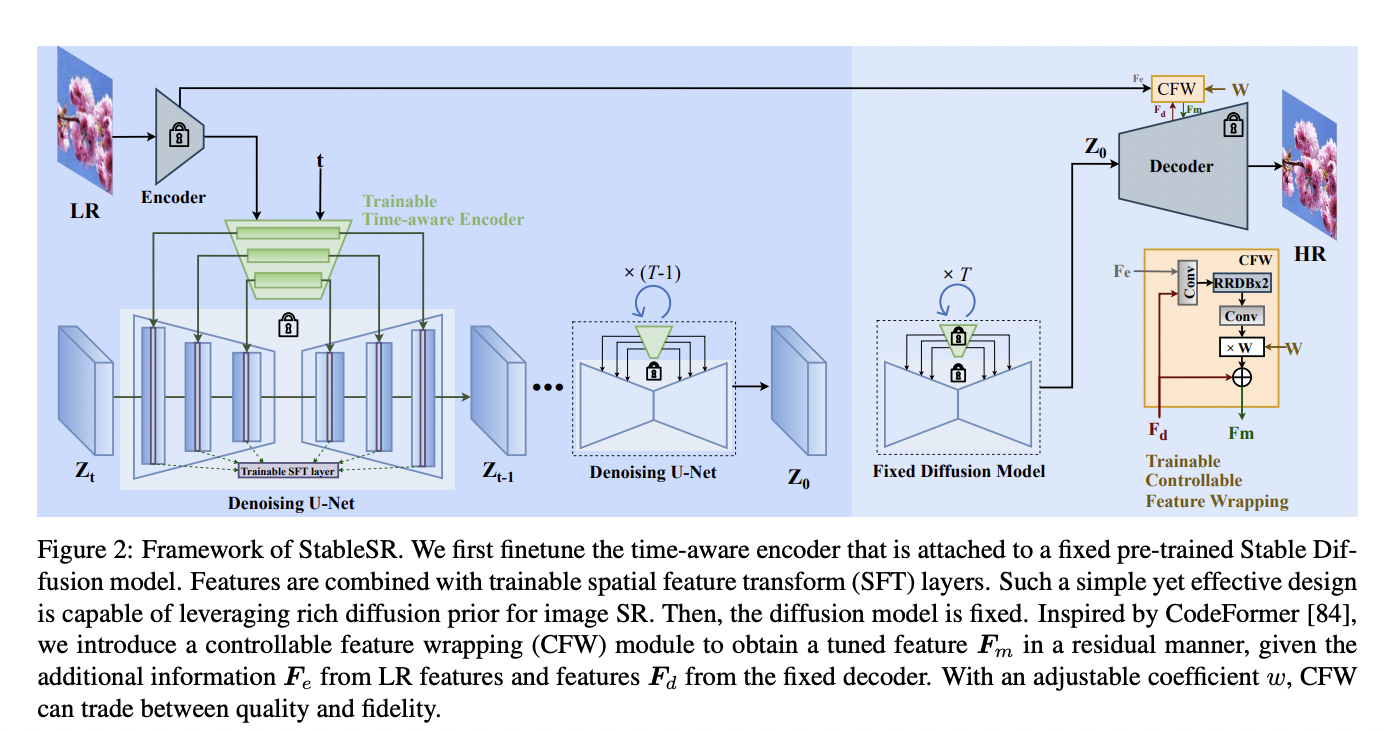
In contrast to prior approaches that concatenate the low-resolution (LR) image with intermediate outputs, necessitating the training of a diffusion model from scratch, StableSR involves fine-tuning a lightweight time-aware encoder and a few feature modulation layers specifically tailored for super-resolution (SR) tasks.
The encoder incorporates a time embedding layer to generate time-aware features, enabling adaptive modulation of features within the diffusion model at different iterations. This not only enhances training efficiency but also maintains the integrity of the generative prior. Additionally, the time-aware encoder provides adaptive guidance during the restoration process, with stronger guidance at earlier iterations and weaker guidance at later stages, contributing significantly to improved performance.
To address the inherent randomness of the diffusion model and mitigate information loss during the encoding process of the autoencoder, StableSR applies a controllable feature wrapping module. This module introduces an adjustable coefficient to refine the outputs of the diffusion model during the decoding process, using multi-scale intermediate features from the encoder in a residual manner. The adjustable coefficient allows for a continuous trade-off between fidelity and realism, accommodating a wide range of degradation levels.
Furthermore, adapting diffusion models for super-resolution tasks at arbitrary resolutions has historically posed challenges. To overcome this, StableSR introduces a progressive aggregation sampling strategy. This approach divides the image into overlapping patches and fuses them using a Gaussian kernel at each diffusion iteration. The result is a smoother transition at boundaries, ensuring a more coherent output.
Some output samples of StableSR presented in the original article compared with state-of-the-art approaches are reported in the figure below.

In summary, StableSR offers a unique solution for adapting generative priors to real-world image super-resolution challenges. This approach leverages pre-trained diffusion models without making explicit assumptions about degradations, addressing issues of fidelity and arbitrary resolution through the incorporation of the time-aware encoder, controllable feature wrapping module, and progressive aggregation sampling strategy. StableSR serves as a robust baseline, inspiring future research in the application of diffusion priors for restoration tasks.
If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper, Github, and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.