Meet TableGPT: A Unified Fine-Tuned Framework that Enables LLMs to Understand and Operate on Tables Using External Functional Commands
Tables are frequently used to represent the vast and complex world of data and serve as the basis for data-driven decision-making in various contexts, including financial analysis, supply chain management, and healthcare analytics. Stakeholders may use it to analyze trends, patterns, and linkages, which helps them make well-informed business choices and optimize processes and resources. Data scientists have long grappled with processing tables using intricate Excel formulae or custom programs. As a result, there has been a pressing demand for more effective understanding and interpretation of tabular data. Large Language Models (LLMs) or Generative Pre-trained Transformers (GPTs) have revolutionized the language data mining paradigm in natural language processing.
In keeping with these studies, researchers have looked into extensive models for voice and vision, among other modalities. Their capacity to produce text that resembles human speech has opened up new avenues for handling tabular data. However, it is difficult to use the standard ChatGPT model in the tabular area for two reasons: (i)Global Table Understanding: It is well known that GPTs have a token length limitation, making it difficult for them to scan huge tables and comprehend the information they contain. (ii), their training procedures are designed for natural languages, so they are less generalizable when working with tabular data. Several works have been created to include natural language for tabular data analysis.
Natural language to SQL (NL2SQL) is a well-established research area that translates natural language into SQL instructions that control relational databases. To use a wide range of spreadsheet software functions, SheetCopilot recently investigated languages to control VBA (Visual Basic for Applications, an embedded script language for Microsoft Excel). They discovered, however, that neither of the alternatives performs satisfactorily. They believe these inherently unstructured computer code types add complexity, making automated post-processing all but impossible. Researchers from Zhejiang University create TableGPT in this study, pushing the limits of what is feasible when using LLM approaches to analyze data. This is a significant advancement in their quest to make data easier to access and comprehend. Their TableGPT system combines tables, spoken instructions, and plain language into a unified GPT model, improving the user-friendliness and intuitiveness of data interpretation.
They combine many key elements into TableGPT by reimagining how tables, spoken language, and instructions interact:
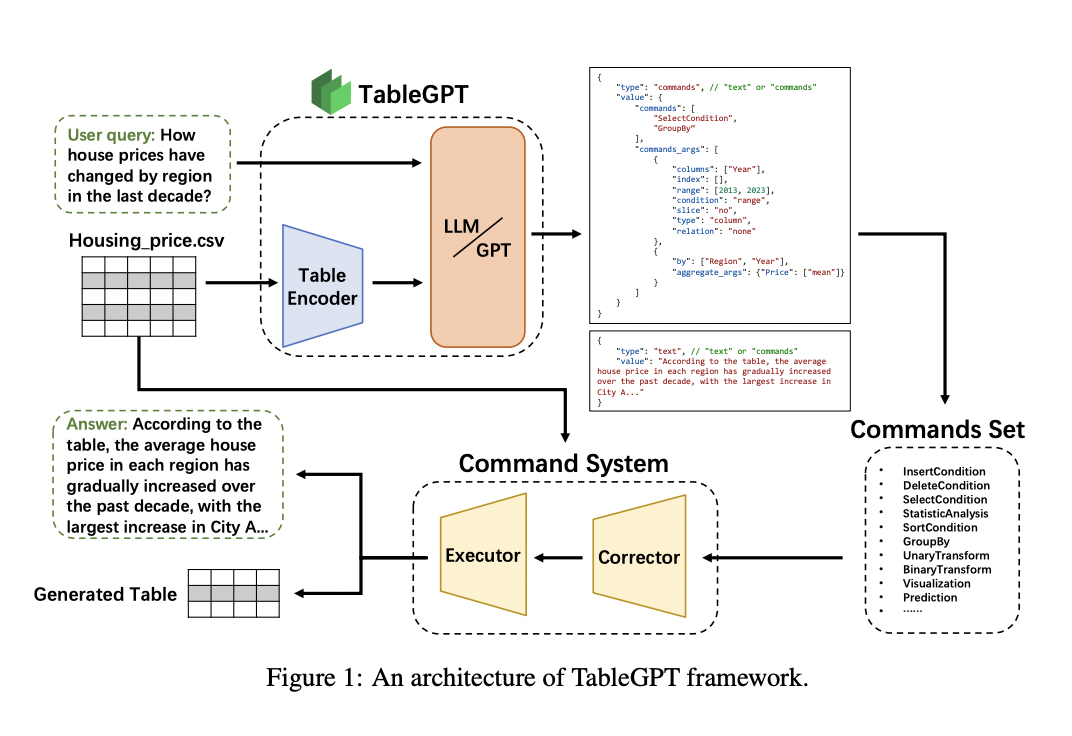
• Global Table Representation: They make the first attempt to create a learning paradigm for global representations of tables that encodes the entire table into a single vector. They equip the table encoder to effectively capture the worldwide information of the input table by concurrently training the LLM and the encoder on enormous volumes of text and table data. Thus, a more comprehensive and improved understanding of tables is provided since the LLM can better see and comprehend the table data.
• Chain-of-Command: They use this notion to highlight the significance of an organized, hierarchical approach to task execution. TableGPT follows the same sequence of commands, breaking difficult jobs into simpler ones and carrying them out step-by-step, much like a well-coordinated organization where each direction is cascaded from a higher level to its lower equivalent. Additionally, it encourages the capacity to reject unclear or improper instructions, much like a real data scientist would, rather than mindlessly adhering to any potentially incorrect instruction, thereby enhancing communication between people and LLM systems in the context of data science. Their suggested command set is simpler to use and lessens the ambiguity that frequently comes with using conventional techniques to handle tabular data.
• Domain-aware fine-tuning: To improve the model’s understanding of particular domain table data, domain-aware fine-tuning involves tailoring training so that the model produces text containing similar stylistic and logical elements found in the given domain. This fosters the ability to adapt to different domains of tables and corresponding textual materials. A data processing pipeline has also been created to make this strategy practical and scaleable. The unstructured code generated by NL2SQL presents major difficulties for preemptive checks and mistake repairs in real-world production environments. As a result, they support the usage of structured command sequences to make post-processing easier.
With self-instruct, Data-Copilot likewise adopts this command-based methodology. Still, its dependence on native LLMs, an API used to understand the processing and analytical logic of tabular data directly, has drawbacks. They believe a successful solution should be specifically designed for tabular data while keeping wide applicability to larger downstream activities due to the inherent data unpredictability and task-specificity of tabular data. This conviction emphasizes how crucial it is to implement an especially pre-trained LLM for tabular data. In conclusion, this study proposes a ground-breaking TableGPT framework, a comprehensive, integrated, and all-natural language-driven solution that enables effective tabular data processing, analysis, and visualization.
They list a few significant benefits of TableGPT:
• Language-driven EDA: Using plain language, TableGPT analyses user intent, breaks down the required actions, and performs external commands on the table. The user is then provided with the processed findings in tabular and written explanations. Exploratory Data Analysis (EDA) is given an intuitive instantiation because of this innovative technique, which makes it easier for users to interact with tabular data.
• Unified Cross-modal Framework: They creatively develop a global table encoder to comprehend the entire table. Due to TableGPT’s ability to completely comprehend user queries, metaknowledge, and whole tabular data, table manipulation execution commands are significantly more trustworthy.
• Generalisation and Privacy: Their TableGPT can manage data heterogeneity in tables better and generalize to many domains thanks to domain-aware fine-tuning. Additionally, their system allows for private deployment and provides strong data privacy protections. In the present day, where data privacy and protection are essential, this feature is crucial.
Check out the Paper. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 900+ AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.