Meet TextDeformer: An AI Framework For Text-guided 3D Mesh Deformation
Three-dimensional (3D) meshes are a primary component of computer graphics and 3D modeling and have several fields of application, including architecture, automotive design, video game development, and film production. A mesh is a digital representation of a three-dimensional object comprising a collection of vertices, edges, and faces that define its shape and structure. The vertices represent the points in space where the edges meet, while the faces define the object’s surface.
Since creating 3D meshes is challenging, it is usually reserved for experts with special artistic skills. This implies that a person would find it difficult to create 3D meshes from zero without this knowledge. The internet makes it possible to find diverse datasets with 3D objects crafted by digital artists. However, when customization (even minimal) is required, the editing process is as arduous as plain creation.
For this reason, the problem of deforming meshes is a topic that has received a great deal of attention in computer graphics and geometry processing. In many existing AI techniques, a user can manipulate deformations through control handles, allowing coarse, low-frequency deformations that preserve details. These are commonly referred to as detail-preserving deformations. However, in 3D modeling, it is often necessary to incorporate fine geometric information, which can be time-consuming and complicated, even for skilled artists.
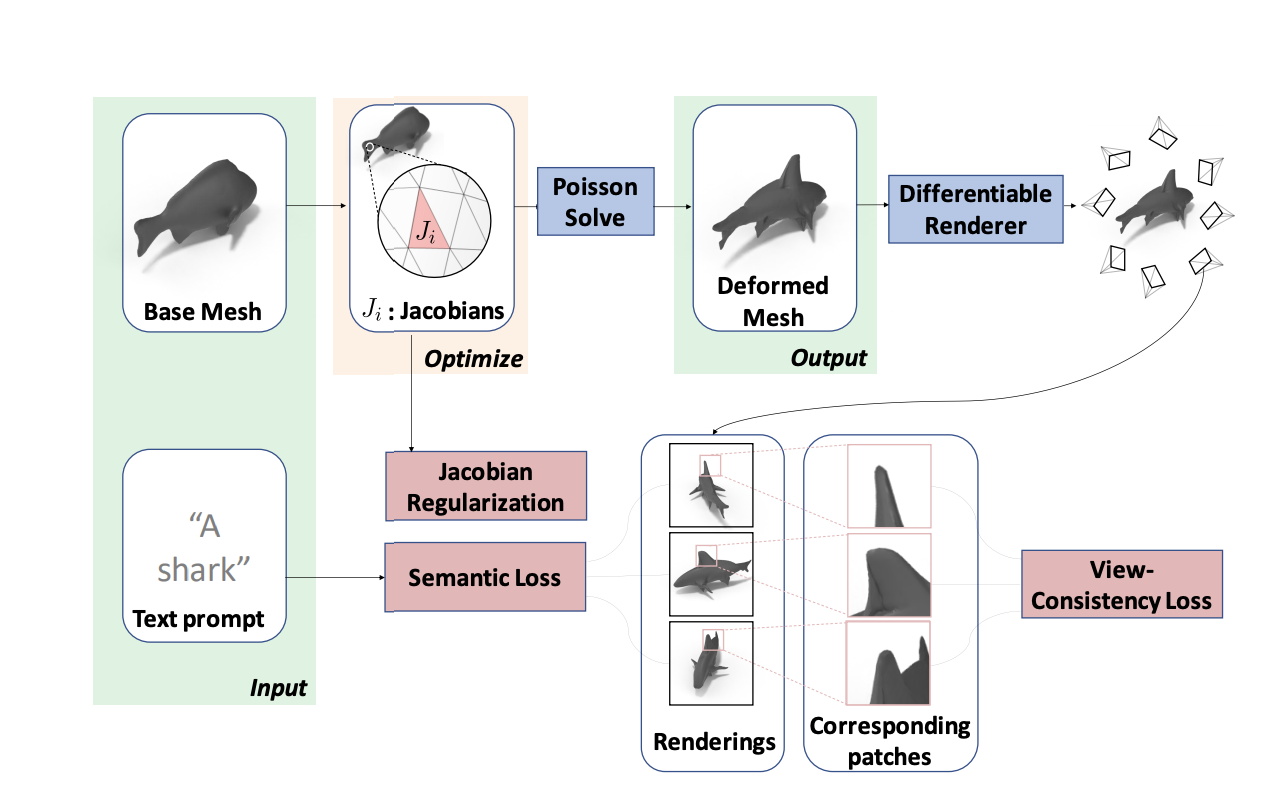
In this sense, a novel AI approach, termed TextDeformer, has been proposed to automate the deformation process of 3D meshes. TextDeformer aims to transform a given source shape to a desired target shape while maintaining semantic consistency between the two. An overview of the system workflow and architecture is presented below.

This approach is based on the success of recent text-guided generative techniques and NeRFs (Neural Radiance Fields) but does not require 3D training data. Instead, the authors use differentiable rendering with pre-trained image encoders like CLIP to adjust and optimize the geometry of the rendered objects.
After deformation, the structure and properties of the source mesh are preserved, and the resulting geometry adheres to the text specifications. This work differs from previous ones in the type of task the model performs. Unlike previous text-guided works that generate geometry from scratch or add detail while preserving input mesh geometry, TextDeformer focuses on the deformation task.
In detail, this framework is designed to modify an existing input shape to create high-quality geometry that accurately reflects the source mesh. In addition, it can produce low-frequency shape changes and high-frequency details, such as elongating a cow’s neck when deforming it into a giraffe or adding scales when deforming into an alligator. The authors insist that the resulting correspondences from the source shape to the target are continuous and semantically meaningful (e.g., “leg deforms to leg”) by coloring the source mesh, which is visible throughout the visualizations.
Some examples of the produced results reported by the authors of this work are illustrated in the figure below. Furthermore, this figure includes a comparison between TextDeformer and the state-of-the-art DreamFusion.

This was the summary of TextDeformer, a novel AI framework to enable accurate text-guided 3D mesh deformation. If you are interested, you can learn more about this technique in the links below.
Check out the Paper. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.