Meet TEXTure: A Novel Artificial Intelligence (AI) Framework For Text-Guided Texturing of 3D Meshes
Text-to-image generation is a novel and fascinating area of research in the field of artificial intelligence (AI), where the goal is to generate realistic images based on textual descriptions. The ability to generate images from text has a wide range of applications, from art to entertainment, where it can be used to create visuals for books, movies, and video games.
One specific application of text-to-image generation is texture imagery, which involves the creation of images that represent different types of textures, such as fabrics, surfaces, and materials. Texture imagery accounts for essential applications in computer graphics, animation, and virtual reality, where lifelike textures can enhance the user’s immersive experience.
Another area of interest in AI research is 3D texture transfer, which involves the transfer of texture information from one object to another in a 3D environment. This process creates truthful 3D models by transferring texture information from a source to a target object. This approach can be employed in fields like product visualization, where realistic 3D models are essential.
Deep learning techniques have revolutionized the field of text-to-image generation, allowing for the creation of highly realistic and detailed images. By using deep neural networks, researchers are able to train models to generate images that closely match the textual descriptions or transfer textures between 3D objects.
Recent work on language-guided models indirectly exploits the well-known text-to-image generative model Stable Diffusion for score distillation. This technique involves distilling knowledge from a large network to a smaller one, which is trained to predict the scores assigned to images from the first network.
Although it represents a major improvement in comparison with previously employed techniques, these models fall short in terms of quality achieved for the 3D texture transfer process compared to their 2D counterparts.
To improve the accuracy of 3D texture transfer, a novel AI framework termed TEXTure has been proposed.
An overview of the pipeline is depicted below.

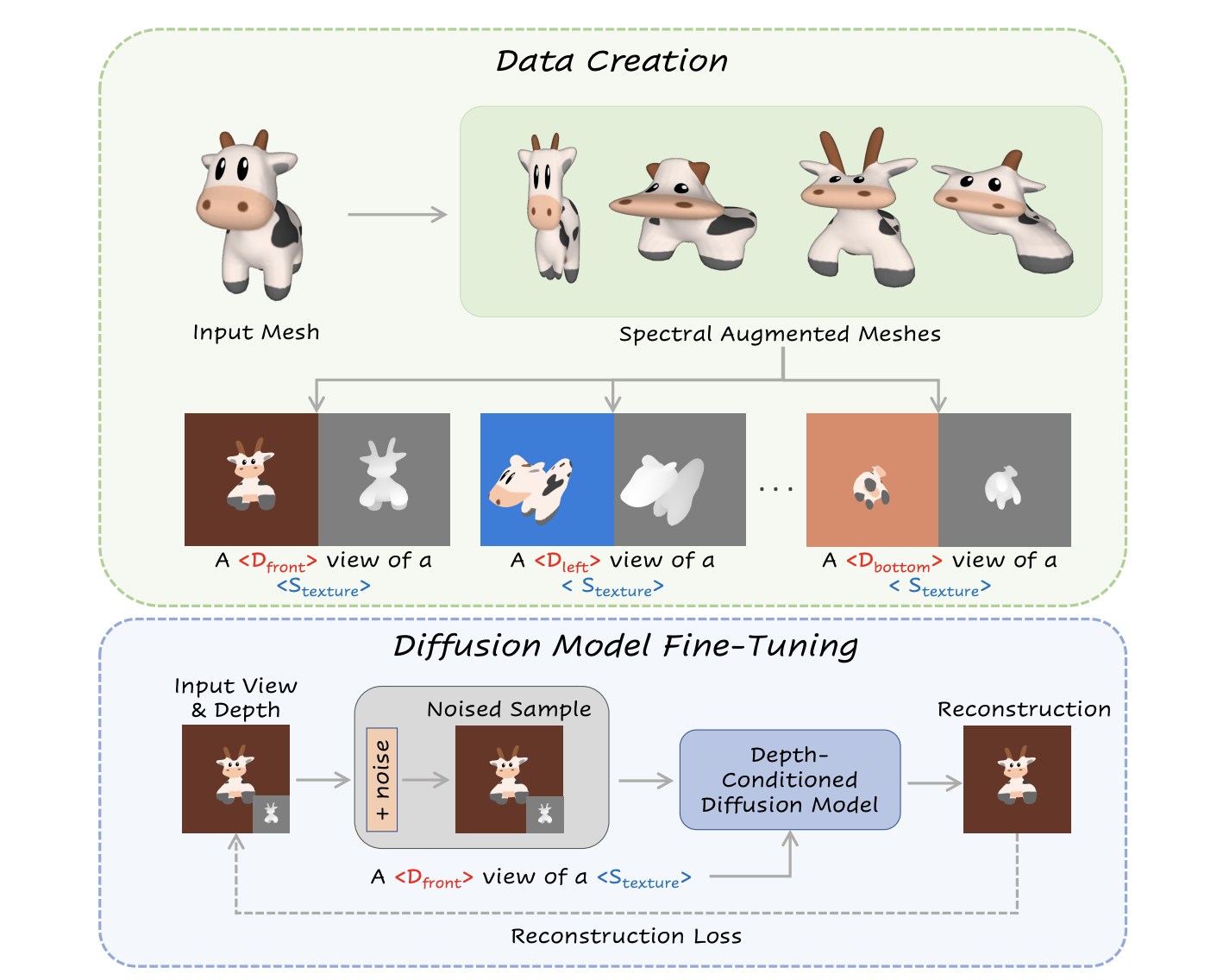
Unlike the above-mentioned approaches, TEXTure applies a full denoising process on rendered images leveraging a depth-conditioned diffusion model.
Given a 3D mesh to texture, the core idea is to iteratively render it from different viewpoints, apply a depth-based painting scheme, and project it back to an atlas.
However, the risk of applying this process naively is the generation of unrealistic or inconsistent texturing due to the stochastic nature of the generation process.
To deal with this problem, the selected 3D mesh is partitioned into a trimap of “keep,” “refine,” and “generate” regions.
The “generate” regions are object parts that need to be painted from the ground; “refine” refers to object parts that were textured from a different perspective and now need to be adjusted to a new viewpoint; “keep” describes the act of preservation of the painted texture.
According to the authors, combining these three techniques allows the generation of highly-realistic results in mere minutes.
The results presented by the authors are reported below and compared with state-of-the-art approaches.

This was the summary of TEXTure, a novel AI framework for text-guided texturing of 3D meshes.
If you are interested or want to learn more about this framework, you can find a link to the paper and the project page.
Check out the Paper, Code, and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 16k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.