Meet the Matryoshka Embedding Models that Produce Useful Embeddings of Various Dimensions
In the significantly developing field of Natural Language Processing (NLP), embedding models are essential for converting complicated items like text, images, and audio into numerical representations that computers can comprehend and interpret. These embeddings, which are essentially fixed-size dense vectors, form the basis for many different applications, such as clustering, recommendation systems, and similarity searches.
However, as these models become more complex, the size of the embeddings they generate also increases, which causes efficiency problems for jobs that come after. To address this, a team of researchers has presented a new approach called Matryoshka Embeddings, models that produce useful embeddings of various dimensions. Matryoshka Embeddings have been named so because they resemble the Russian nesting dolls that hold smaller dolls inside, and thus, they operate on a similar idea.
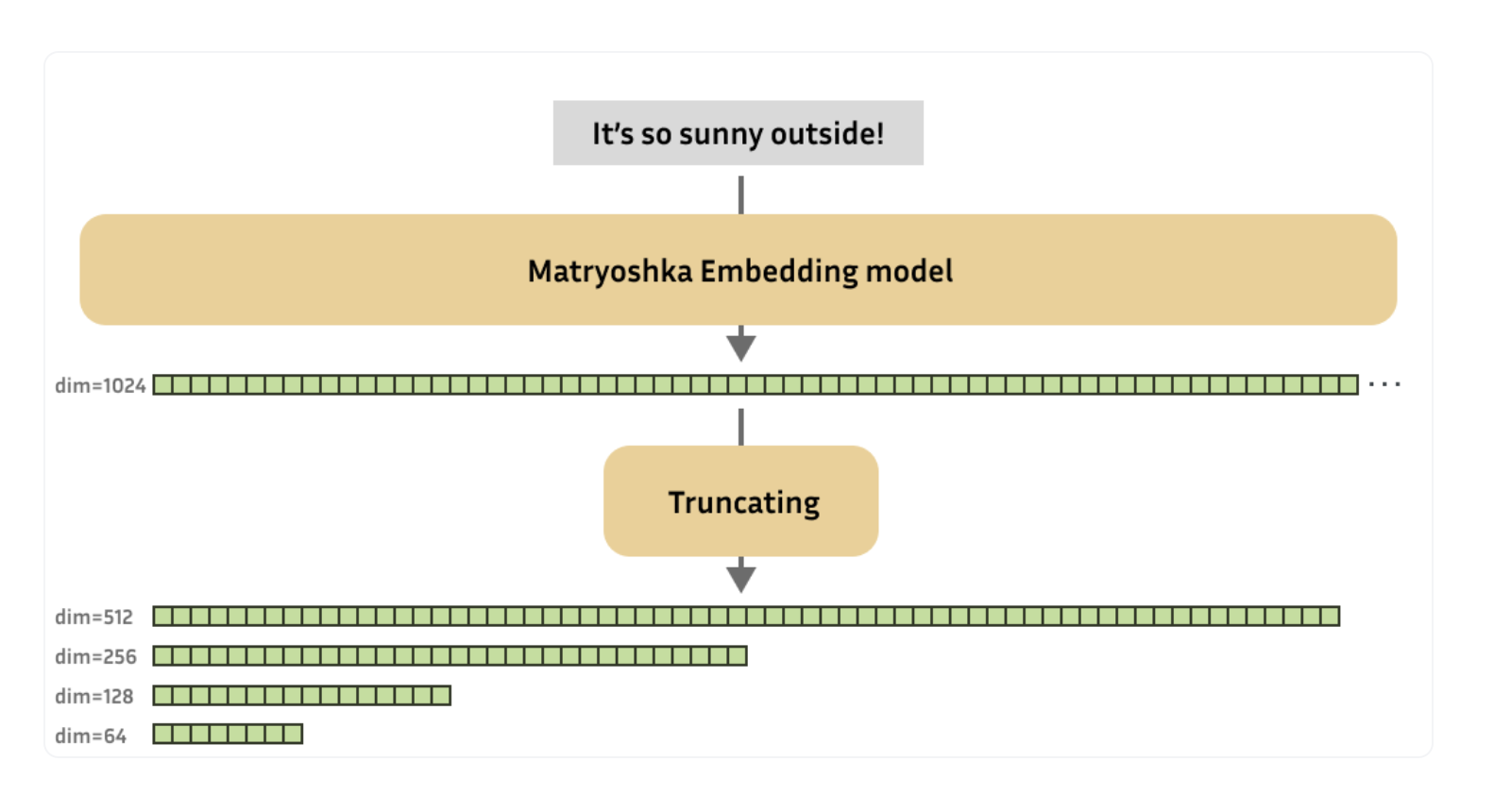
These models are made to generate embeddings that capture the most important information in the embedding’s initial dimensions, allowing them to be truncated to smaller sizes without appreciable loss in performance. Variable-size embeddings that can be scaled in accordance with storage requirements, processing speed requirements, and performance trade-offs are made possible by this characteristic.
Matryoshka Embeddings has several applications. For example, reduced embeddings can be used to quickly shortlist candidates before doing more computationally demanding analysis utilizing the complete embeddings, as in the case of closest neighbor search shortlisting. This flexibility in controlling the embeddings’ size without significantly sacrificing accuracy offers a big benefit in terms of economy and scalability
.
The team has shared that as compared to typical models, Matryoshka Embedding models require a more sophisticated approach during training. The procedure involves evaluating the quality of embeddings at different reduced sizes as well as at their full size. The model prioritizes the most important information in the first dimensions with the help of a specialized loss function that assesses the embeddings at several dimensions.
Matryoshka’s models are supported by frameworks such as Sentence Transformers, which makes it relatively easy to put this strategy into practice. These models can be trained with little overhead by using a Matryoshka-specific loss function across various truncations of the embeddings.
When using Matryoshka Embeddings in practice, embeddings are generated normally, but they can be optionally truncated to the required size. This technique reduces the computational load, which greatly improves the efficiency of downstream activities without slowing down the formation of embeddings.
Two models trained on the AllNLI dataset have been used as an example to show the effectiveness of Matryoshka Embeddings. First, compared to a regular model, the Matryoshka model performs better on a number of different aspects. The Matryoshka model maintains around 98% of its functionality even when reduced to slightly over 8% of its initial size, demonstrating its effectiveness and offering the possibility of considerable processing and storage time savings.
The possibilities of Matryoshka Embeddings have also been demonstrated by the team in an interactive demo that lets users dynamically change an embedding model’s output dimensions and see how it affects retrieval performance. This practical demonstration not only highlights the adaptability of Matryoshka Embeddings but also highlights how they have the ability to transform the effectiveness of embedding-based applications completely.
In conclusion, Matryoshka Embeddings has helped solve the growing problem of maintaining the efficiency of embedding models as they scale in size and complexity. These models provide new opportunities for optimizing NLP applications in various domains, as they enable the dynamic scaling of embedding sizes without significant loss in accuracy.
Check out the Models. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.