Meet This Artificial Intelligence (AI) Image Dataset Called ‘DIFFUSIONDB,’ That Consists of 2 Million Stable Diffusion Images, And Their Text Prompts And Hyperparameters
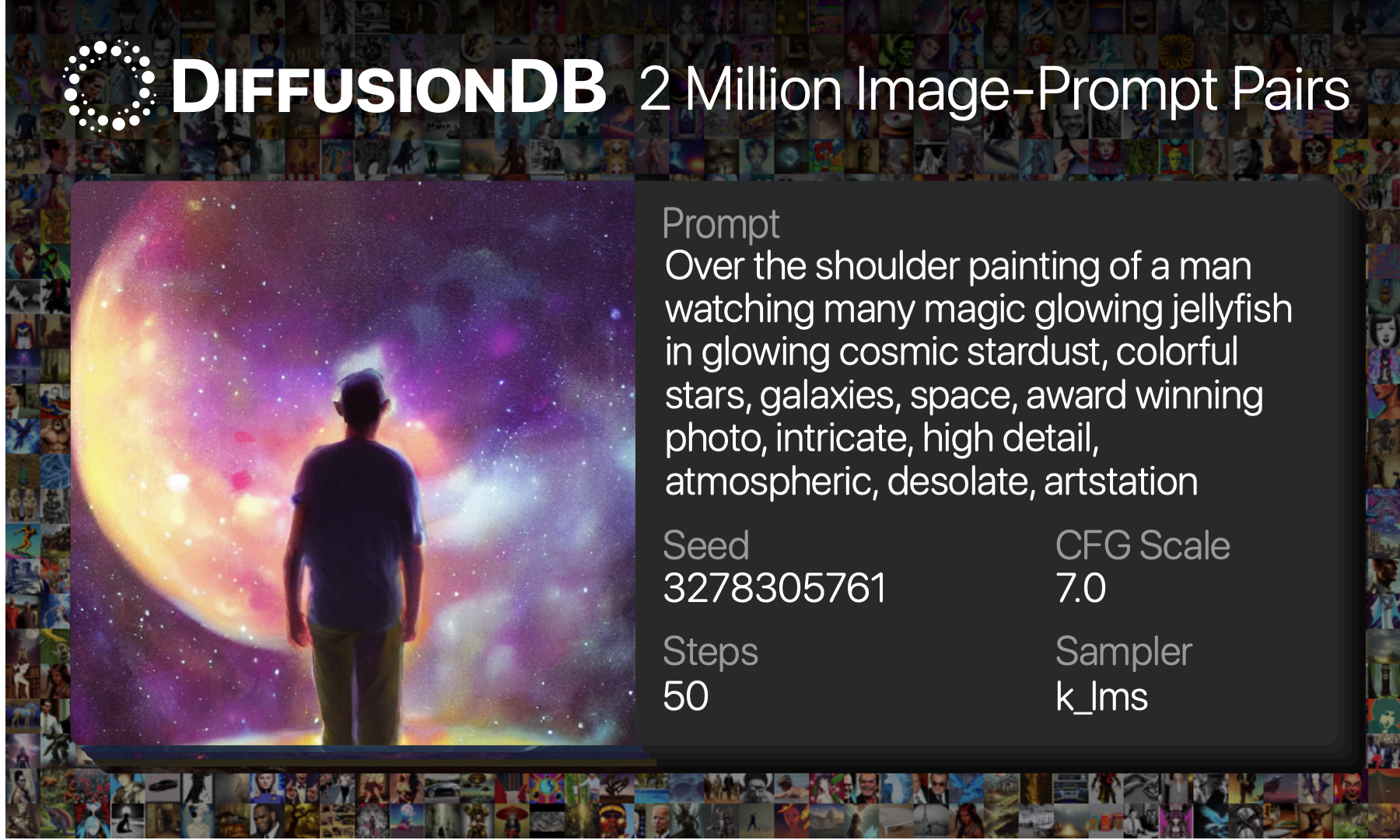
The first extensive text-to-image prompt dataset is called DiffusionDB. It has 2 million Stable Diffusion-generated photos that were produced using prompts and hyperparameters provided by actual users.
Users can now create high-quality photos by writing text prompts in natural language. Nevertheless, producing photographs with the appropriate details requires the right stimuli, but it sometimes needs to be clarified how a model will respond to various prompts or what the ideal prompts are. Researchers present DIFFUSIONDB, the first extensive text-to-image prompt dataset, to assist researchers in addressing these important issues. 2 million photos produced by Stable Diffusion utilizing prompts and hyperparameters given by actual users are contained in DIFFUSIONDB. They examine the dataset’s prompts and talk about their main characteristics. This human-actuated dataset’s exceptional size and diversity offer fascinating research prospects in figuring out how generative models and prompts interact, spotting deep fakes, and developing human-actuated systems.

Task Support and Leaderboards
The unmatched size and diversity of this human-actuated dataset present fascinating research opportunities to understand the interaction between prompts and generative models, detect deepfakes, and develop tools for human-AI interaction to facilitate user adoption of these models.
Adding Data Set Subsets
DiffusionDB measures 1.6 TB in size. However, thanks to our modularised file structure, you can quickly import a desired amount of photos along with their prompts and hyperparameters. They show three ways to load a portion of DiffusionDB.
Utilizing the HUGGING FACE DATASETS LOADER is Method 1
The Hugging Face Datasets library makes it simple to load questions and pictures from DiffusionDB. They predefined 16 DiffusionDB subsets using the number of instances.
METHOD #2: Download the Poloclub app
You can download and load DiffusionDB using the Python downloader download.py that is included in this repository. From the command line, you can utilize it.
obtaining a solitary file
On HuggingFace, the number at the end of the file indicates which specific file to download. The program will automatically inflate the number and produce the URL.
obtaining various files
The -i and -r parameters set the upper and lower boundaries of the list of files to download.
Utilize metadata.parquet in Method 3 (TEXT ONLY)
You can easily access all 2 million prompts and hyperparameters in the metadata.parquet table if your task does not require images.
DiffusionDB is the result of scraping user-generated images on the official Stable Diffusion Discord server. The server has strict rules against generating and sharing illegal, hateful, or NSFW (not suitable for work) images. It also disallows users to write or share prompts with personal information.
Creation of a dataset
Curation Justification
Recent diffusion models have become quite popular because they make it possible to generate high-quality, controlled images from text cues using natural language. Since the publication of these models, individuals from other fields have quickly used them to produce hyper-realistic films, synthetic radiological scans, and even award-winning artwork.
However, creating images with the appropriate information takes time because users must properly formulate prompts that explain the precise outcomes they seek. Such impulses must be developed by trial and error, frequently seeming random and unprincipled. A researcher compares writing prompts to wizards acquiring “magical spells”; users may not comprehend why some prompts are effective, but they will nevertheless add them to their “spell book.” For instance, it has become customary to include unique phrases like “trending on artstation” and “unreal engine” in the prompt to produce extremely detailed photos.
In the framework of text-to-text generation, prompt engineering has developed into a topic of study where researchers systematically analyze how to create prompts to successfully complete various downstream activities. Large text-to-image models are still in their infancy, therefore, it is crucial to comprehend how they respond to prompts, how to create compelling prompts, and how to create tools that assist users in creating images. They develop DiffusionDB, the first large-scale prompt dataset with 2 million real prompt-image pairs, to assist academics in addressing these important issues.
Social Impact of the Dataset: Data Use Considerations
This dataset aims to support the development of massively scalable text-to-image generative models. The unequaled richness and diversity of this human-actuated dataset present exciting research opportunities to understand the relationship between prompts and generative models, detect deepfakes, and develop tools for human-AI interaction to facilitate user adoption of these models.
It is important to note that they pull prompts and visuals from the Stable Diffusion Discord server. Users are prohibited from creating or sharing damaging or NSFW (not acceptable for work, such as sexual and violent content) photos on the Discord server. The server’s Stable Diffusion model additionally features an NSFW filter that distorts generated graphics when it encounters NSFW material. It is still possible that some users created damaging photos that the NSFW filter did not catch or that the server moderators did not remove. As a result, DiffusionDB might have these pictures. They offer a Google Form on the DiffusionDB website where users can report offensive or inappropriate images and prompts in order to lessen the possible harm. This form will be actively watched, and any reported photos or prompts will be removed from DiffusionDB.
DiffusionDB’s prompts may not accurately represent photos uploaded by beta testers, as they were taken in channels where a bot could test Stable Diffusion ahead of time. These users are likely to know alternative text-to-image generative models because they began using Diffusion before the model was made available to the general public.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'DIFFUSIONDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models'. All Credit For This Research Goes To Researchers on This Project. Check out the paper, dataset and project.
Please Don't Forget To Join Our ML Subreddit
![]()
Ashish kumar is a consulting intern at MarktechPost. He is currently pursuing his Btech from the Indian Institute of technology(IIT),kanpur. He is passionate about exploring the new advancements in technologies and their real life application.
Credit: Source link
Comments are closed.