Meet this Artificial Intelligence Model called ‘PhysDiff,’ which Instills the Laws of Physics into the Diffusion Process to Generate Physically Plausible Human Motions
Human motion generation via deep learning is crucial with many applications in virtual reality, gaming, and animation. They must learn a conditional generative model that can capture the multi-modal distribution of human motions in common contexts like text-to-motion synthesis. Due to the wide range of human motions and the various interactions between human body parts, the distribution can be very complex. Due to their excellent capacity to simulate complex distributions, which has been extensively proved in the image generation domain, denoising diffusion models are generative models that are particularly well suited for this task.
High test likelihood has frequently demonstrated strong mode coverage for these models. Additionally, they outperform variational autoencoders (VAEs), normalizing flows, and generative adversarial networks (GANs) in sample quality and training stability. This inspired recent efforts to propose motion diffusion models that perform substantially better than conventional deep generative models in generating motion. However, existing motion diffusion models disregard the fundamental principles governing human motion. Even though diffusion models are better at simulating the distribution of human motion, they still need to explicitly simulate complicated dynamics brought on by pressures and contact or enforce physical limitations.
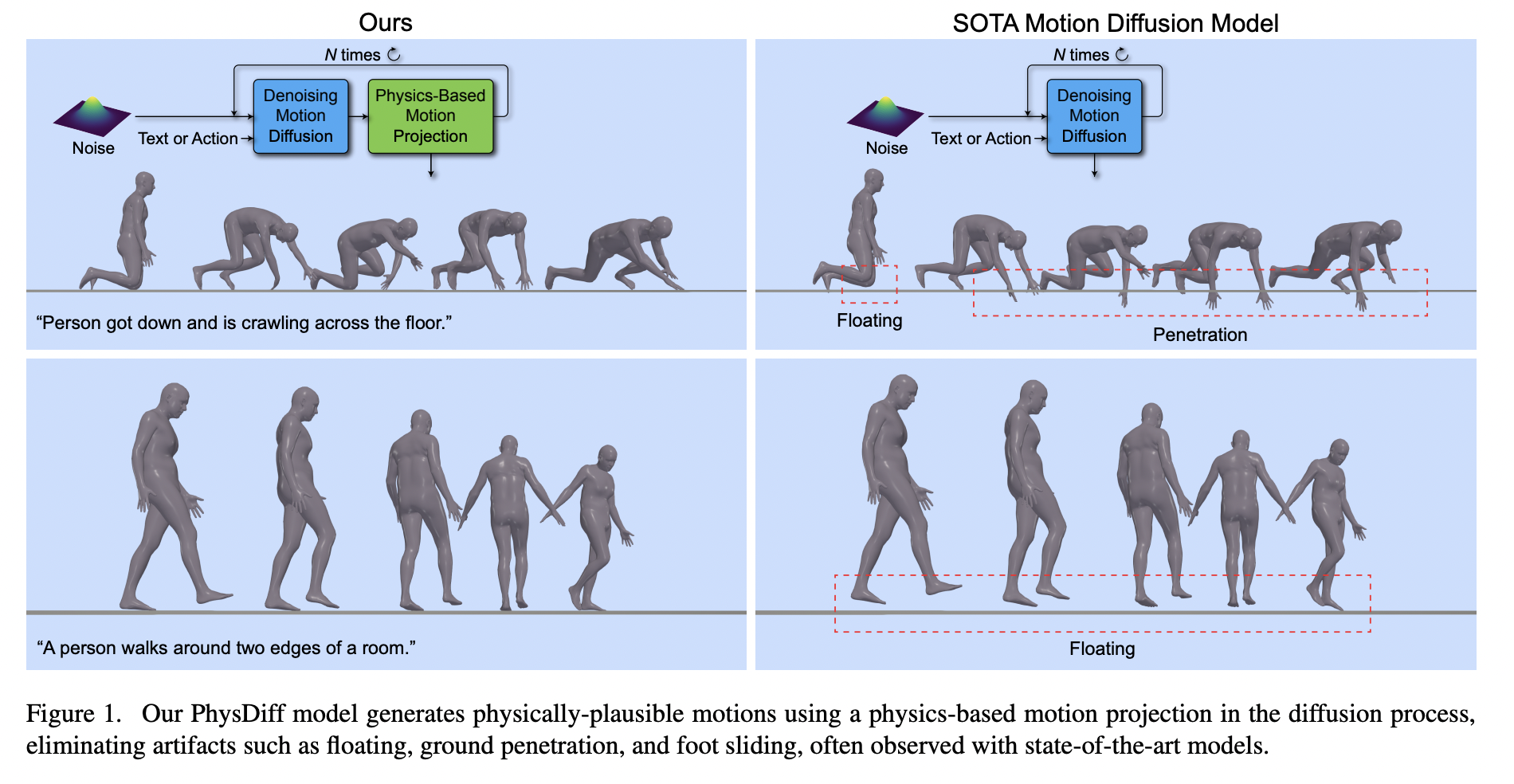
Because of this, their motions frequently have noticeable abnormalities like floating, foot sliding, and ground penetration. Many real-world applications, including animation and virtual reality, are significantly hampered by this because people are so sensitive to even the smallest indication of physical inaccuracy. Making human motion diffusion models physics-aware is a crucial issue that needs to be solved. They suggest a brand-new physics-guided motion diffusion model (PhysDiff) address this issue by incorporating physics principles into the denoising diffusion procedure. PhysDiff uses a physics-based motion projection module (details will be provided later) to project an input motion into a physically credible space. They project the denoised motion of a diffusion step using the motion projection module during the diffusion process.
This new motion further guides the denoising diffusion process in the following diffusion stage. It could be tempting to include the physics-based projection after the diffusion process. However, as the denoised motion from diffusion could be too improbable for one physics-based projection step to rectify, this might result in strange motions (see figure below for an example). To keep the motion close to the data distribution while progressing toward the physically-plausible space, they must instead include the projection in the diffusion process and apply physics and diffusion iteratively. By simulating motion in a physics simulator, the physics-based motion projection module plays the crucial job of enforcing physical limitations in PhysDiff.
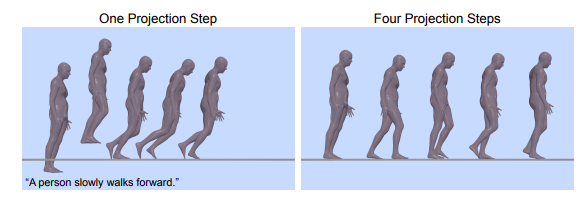
Since the motion is too physiologically improbable to be corrected in one step, the ultimate result is an unnatural motion. Multiple projections (right) stages iteratively employ physics and diffusion to resolve this issue.
They train a motion imitation policy that can command a character agent in the simulator to mimic various input motions, specifically utilizing large-scale motion capture data. The resulting simulated motion eliminates artifacts like floating, foot sliding, and ground penetration while enforcing physical limits. Once trained, the motion imitation policy can produce a physically appropriate motion by simulating the denoised motion of a diffusion step. On the tasks of text-to-motion generation and action-to-motion generation, they assess their model, PhysDiff. They use the network of the state-of-the-art (SOTA) motion diffusion model (MDM) as their model’s denoiser because their approach is indifferent to the precise instantiation of the denoising network used for diffusion.
On the large-scale HumanML3D benchmark, their model greatly outperforms SOTA motion diffusion methods for text-to-motion creation, cutting physics errors by more than 86% while enhancing motion quality by more than 20%, as shown by the Frechet inception distance (FID). Their model again reduces the physics error metric for action-to-motion generation by more than 78% on HumanAct12 and 94% on UESTC while still getting competitive FID scores. They also conduct in-depth studies to explore different timetables for the physics-based projection or the projection’s diffusion timesteps. They notice an interesting tradeoff between motion quality and scientific plausibility when changing the number of physics-based projection steps.
More specifically, up to a certain point, increasing the number of projection steps improves physical plausibility and motion quality; however, after that point, the motion quality tends to degrade, meaning that the motion still respects the physical restrictions but may still appear artificial. This insight directs us to employ a balanced number of physics-based projection phases to produce motion with great physical believability. Additionally, they discovered that late diffusion steps perform better than early steps when the physics-based projection is added. They postulate that early diffusion steps’ movements may gravitate toward the training data’s mean motion and that the physics-based projection may cause this motion to deviate even farther from the distribution of the data, hindering the diffusion process.
The following is a summary of their contributions:
• They provide a unique physics-guided motion diffusion model that creates physically proper motions by including physics principles in the diffusion process.
• To enforce physical limits, they suggest using human motion imitation as a motion projection module in a physics simulator.
• On large-scale motion datasets, their model significantly increases physical plausibility and achieves SOTA performance in motion quality. Their thorough research also offers information on physics-guided diffusion timetables and tradeoffs.
Check out the Paper and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.