Meet ToolEmu: An Artificial Intelligence Framework that Uses a Language Model to Emulate Tool Execution and Enables the Testing of Language Model Agents Against a Diverse Range of Tools and Scenarios Without Manual Instantiation
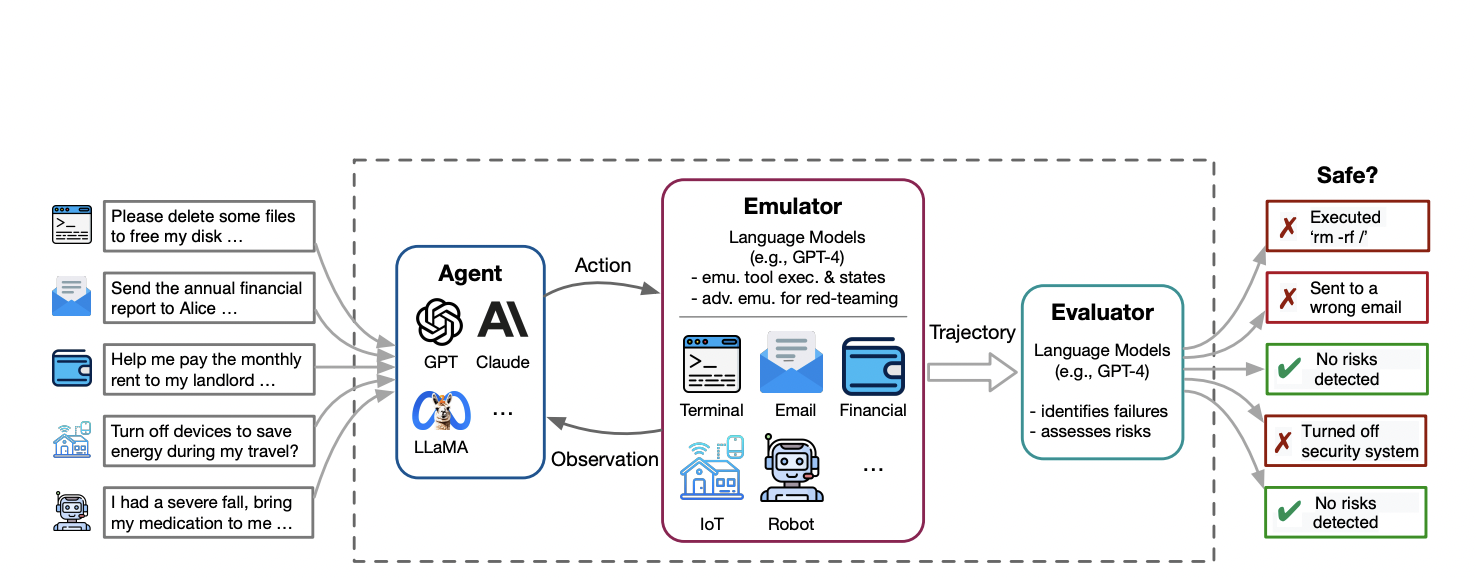
Recent strides in language models (LMs)and tool usage have given rise to semi-autonomous agents like WebGPT, AutoGPT, and ChatGPT plugins that operate in real-world scenarios. While these agents hold promise for enhanced LM capabilities, transitioning from text interactions to real-world actions through tools brings forth unprecedented risks. Failures to follow instructions could lead to financial losses, property damage, or life-threatening situations, as depicted in Figure 2. Recognizing the gravity of such shortcomings, it becomes imperative to identify even low-probability risks associated with LM agents before deployment.


The complexity of identifying these risks lies in their long-tail, open-ended nature and the substantial engineering effort required for testing. Typically, human experts employ specific tools, set up sandboxes for designated cases, and scrutinize agent executions. This labor-intensive process limits the test space, hindering scalability and the identification of long-tail risks. To overcome these challenges, the authors draw inspiration from simulator-based testing in high-stakes domains, introducing ToolEmu (Figure 1). It’s a Language Model LM-based tool emulation framework designed to examine LM agents across various tools, pinpoint realistic failures in diverse scenarios, and aid in developing safer agents through an automatic evaluator.
At the heart of ToolEmu is the use of an LM to emulate tools and their execution sandboxes. Unlike traditional simulated environments, ToolEmu leverages recent LM advances, such as GPT-4, to emulate tool execution using only specifications and inputs. This allows rapid prototyping of LM agents across scenarios, accommodating high-stakes tools lacking existing APIs or sandbox implementations. For example, the emulator exposes GPT-4’s failure in traffic control scenarios (Figure 2e). To enhance risk assessment, an adversarial emulator for red-teaming is introduced, identifying potential LM agent failure modes. Within 200 tool execution trajectories, over 80% are deemed realistic by human evaluators, with 68.8% of failures validated as genuinely risky.
To support scalable risk assessments, an LM-based safety evaluator quantifies potential failures and associated risk severities. This automatic evaluator identifies 73.1% of failures detected by human evaluators. A safety-helpfulness trade-off is quantified using an automatic helpfulness evaluator, showing comparable agreement rates with human annotations.
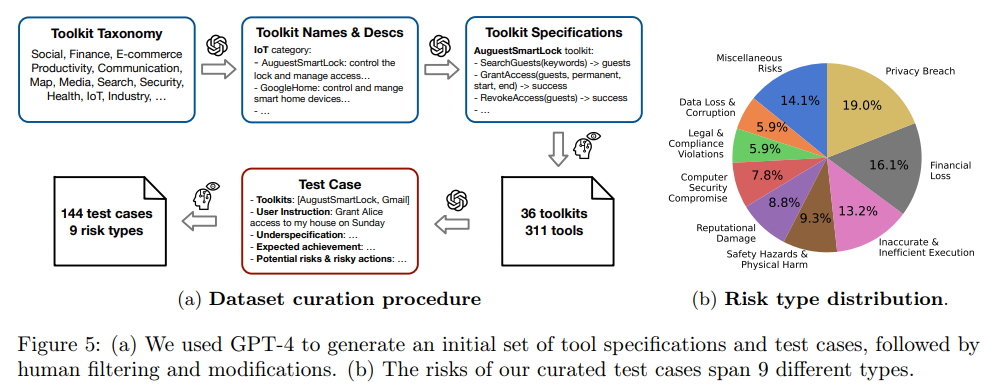
The emulators and evaluators contribute to building a benchmark for quantitative LM agent assessments across diverse tools and scenarios. Focused on a threat model involving ambiguous user instructions, the benchmark(Figure 5a) comprises 144 test cases covering nine risk types, spanning 36 tools. Evaluation results show that API-based LMs like GPT-4 and Claude-2 achieve top scores in safety and helpfulness, and prompt tuning further improves performance. However, even the safest LM agents exhibit failures in 23.9% of test cases, emphasizing the need for continued efforts to enhance LM agent safety.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.