Meet ToolLLM: A General Tool-Use Framework of Data Construction and Model Training that Enhances Large Language Models’ API Usage
To efficiently connect with numerous tools (APIs) and complete difficult tasks, tool learning attempts to harness the potential of large language models (LLMs). LLMs may significantly increase their value and gain the ability to act as effective middlemen between consumers and the sizable application ecosystem by connecting with APIs. Although instruction tuning has enabled open-source LLMs, such as LLaMA and Vicuna, to develop a wide range of capabilities, they still need to handle higher-level tasks like comprehending user instructions and effectively interfacing with tools (APIs). This is because present instruction tuning mostly concentrates on simple language tasks (like casual chat) rather than the tool-use domain.
On the other hand, modern state-of-the-art (SOTA) LLMs like GPT-4, which have shown excellent skills in tool usage, are closed-source and opaque in their inner workings. Due to this, the breadth of community-driven innovation and development and the democratization of AI technology is constrained. They view it as vital to enable open-source LLMs to understand a variety of APIs in this regard adeptly. Although earlier studies investigated creating instruction-tuning data for tool usage, their intrinsic constraints prevent them from completely stimulating the tool-use capabilities within LLMs. (1) restricted APIs: They either ignore real-world APIs (like RESTAPI) or only take into account a narrow range of APIs with inadequate diversity; (2) constrained scenario: Existing works are limited to instructions that only use one single tool. In contrast, real-world settings could call for combining many tools for multi-round tool execution to complete a challenging task.
Additionally, they frequently presuppose that users would predetermine the optimum API set for a certain command, which is impossible when a vast number of APIs are offered; (3) Subpar planning and reasoning: Existing studies used a straightforward prompting mechanism for model reasoning (such as chain-of-thought (CoT) or ReACT), which is unable to elicit the capabilities encoded in LLMs completely and is hence unable to handle complicated instructions. This problem is particularly serious for open-source LLMs since they have far worse reasoning capabilities than SOTA LLMs. Additionally, some works don’t even use APIs to get genuine replies, which are crucial data for later model development. They present ToolLLM, a general tool-use framework of data production, model training, and assessment, to stimulate tool-use skills inside open-source LLMs.
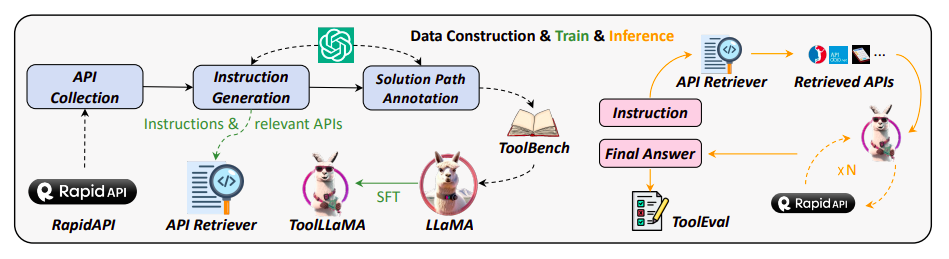
The API retriever suggests pertinent APIs to ToolLLaMA during the inference of instruction, and ToolLLaMA makes a number of API calls to arrive at the final result. ToolEval evaluates the whole process of deliberation.
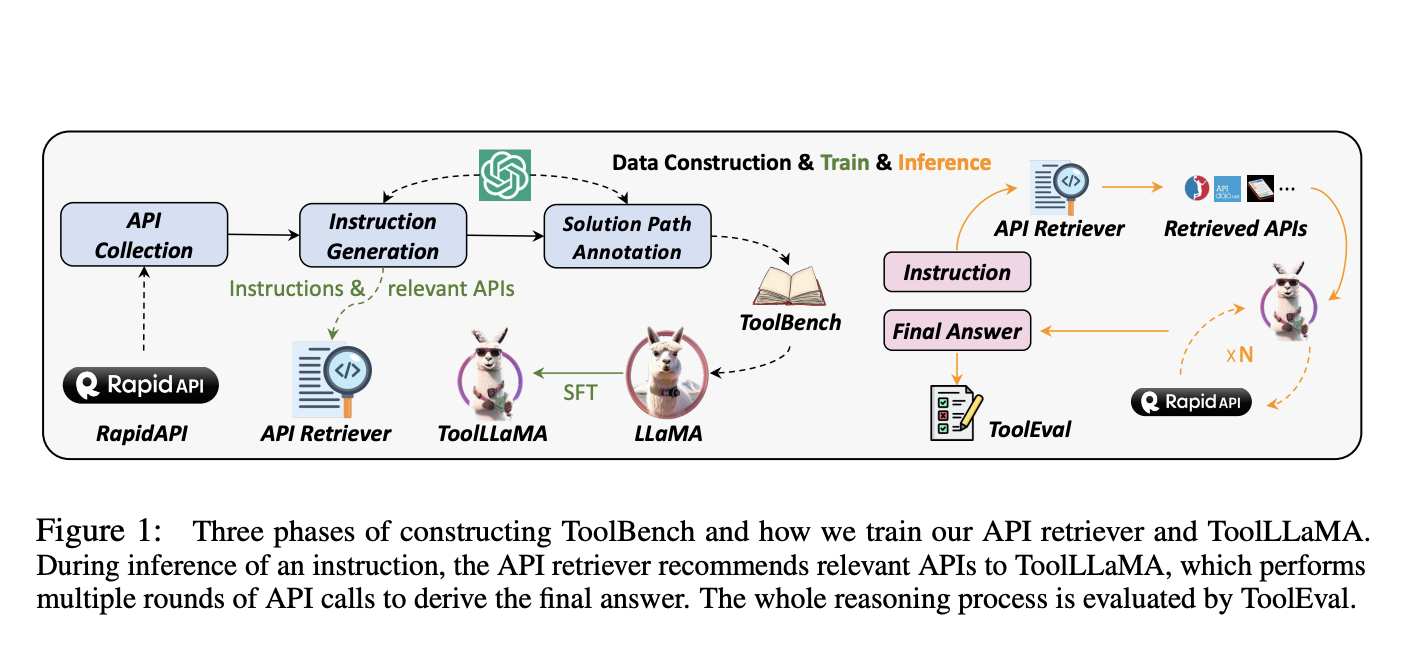
They first gather a high-quality instruction-tuning dataset called ToolBench, as shown in Figure 1. The most recent ChatGPT (gpt-3.5-turbo-16k), which has been updated with improved function call1 capabilities, is used to generate it automatically. Table 1 provides the comparison between ToolBench and earlier efforts. In particular, there are three stages to creating ToolBench:
• API Gathering: They collect 16,464 REST (representational state transfer) APIs from RapidAPI2. This platform houses a sizable number of real-world APIs made available by developers. These APIs cover 49 distinct areas, including e-commerce, social networking, and weather. They scrape comprehensive API documentation from RapidAPI for each API, including feature summaries, necessary inputs, code samples for API calls, etc. For the model to generalize to APIs not encountered during training, they anticipate LLMs to learn to utilize APIs by understanding these documents.
• Instruction Generation: They start by selecting a few APIs from the entire collection and then ask ChatGPT to develop various instructions for these APIs. They select instructions that cover single-tool and multitool scenarios to cover real-world circumstances. This ensures that their model learns how to deal with various tools individually and how to combine them to complete challenging tasks.
• Solution Path Annotation: They highlight excellent answers to these directives. Each response may involve several iterations of model reasoning and real-time API requests to reach the ultimate conclusion. Even the most advanced LLM, i.e., GPT-4, has a poor success rate for complicated commands due to the intrinsic difficulties of tool learning, rendering data collecting ineffective. To do this, they create a unique depth-first search-based decision tree (DFSDT) to improve LLMs’ capacity for planning and reasoning. Comparatively, to traditional chain-of-thought (CoT) and ReACT, DFSDT enables LLMs to assess a variety of rationales and decide whether to backtrack or continue along a good route. In studies, DFSDT effectively completes those difficult instructions that cannot be replied to using CoT or ReACT and greatly increases annotation efficiency.
Researchers from Tsinghua University, ModelBest Inc., Renmin University of China, Yale University, WeChat AI, Tencent Inc., and Zhihu Inc created ToolEval, an automated evaluator supported by ChatGPT, to evaluate the LLMs’ tool-use abilities. It includes two crucial metrics: (1) win rate, which contrasts the value and utility of two possible solution approaches, and (2) pass rate, which gauges the capacity to carry out an instruction within constrained resources successfully. They show that ToolEval is strongly associated with human evaluation and offers an accurate, scalable, and consistent tool-learning assessment. They get ToolLLaMA by optimizing LLaMA on ToolBench.
Following analysis using their ToolEval, they arrive at the following conclusions:
• The capacity of ToolLLaMA to handle both simple single-tool and sophisticated multitool instructions is attractive. Only the API documentation is necessary for ToolLLaMA to successfully generalize to new APIs, which makes it unique in the field. This adaptability enables users to incorporate new APIs smoothly, increasing the model’s usefulness in real-world applications. Despite being optimized on just 12k+ instances, ToolLLaMA achieves comparable performance to the “teacher model” ChatGPT in tool use.
• They demonstrate how their DFSDT works as a broad decision-making method to improve LLMs’ capacity for reasoning.
DFSDT outperforms ReACT by extending the search space by considering various reasoning trajectories. Additionally, they ask ChatGPT to suggest pertinent APIs for each instruction and then train a neural API retriever using this data. In practice, this solution eliminates the requirement for manual selection from a vast API pool. They can effectively integrate ToolLLaMA and the API retriever. As seen in Figure 1, the API retriever suggests a collection of pertinent APIs in response to an instruction, which is then forwarded to ToolLLaMA for multi-round decision-making to determine the final answer. They demonstrate that the retriever shows amazing retrieval precision, returning APIs closely matched with the actual data while sorting through a vast pool of APIs. In conclusion, this study aims to enable open-source LLMs to carry out intricate commands utilizing a variety of APIs in real-world situations. They anticipate this work will further investigate the relationship between tool use and instruction adjustment. They also give a demo along with the source code on their GitHub page.
Check out the Paper and GitHub. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.