Meet TR0N: A Simple and Efficient Method to Add Any Type of Conditioning to Pre-Trained Generative Models

Recently, large machine-learning models have excelled across a variety of tasks. However, training such models calls for a lot of computer power. Thus, it is crucial to properly and effectively leverage current, sizable pre-trained models. However, the challenge of plug-and-playably merging the capabilities of various models still needs to be solved. Mechanisms to do this task should preferably be modular and model-neutral, allowing for simple model component switching (e.g., replacing CLIP with a new, cutting-edge text/image model with a VAE).
In this work, researchers from Layer 6 AI, University of Toronto and Vector Institute investigate conditional generation by mixing previously trained models. Given a conditioning variable c, conditional generative models seek to learn a conditional data distribution. They are normally trained from scratch on pairings of data with matching c, such as pictures x with corresponding class labels or text prompts supplied via a language model c. They want to change any pre-trained unconditional pushforward generative model into a conditional model by using a model G that converts latent variables z sampled from a prior p(z) to data samples x = G(z). To do this, they provide TR0N, a broad framework to train pre-trained unconditional generative models conditionally.
TR0N presupposes access to a trained auxiliary model f, a classifier, or a CLIP encoder to map each data point x to its associated condition c = f(x). TR0N additionally expects access to a function E(z, c) that assigns lower values to latents z for which G(z) “better satisfies” a criterion c. Using this function, TR0N minimizes the gradient of E(z, c) over z in T steps for a given c to locate latents that, when applied to G, would provide the necessary conditional data samples. However, they demonstrate that initially optimizing E naively could be much better. In light of this, TR0N begins by studying a network they employ to optimize the optimization process more effectively.
Since it “translates” from a condition c to a matching latent z such that E(z, c) is minimal, this network is known as the translator network since it essentially amortizes the optimization issue. The translation network is trained without adjusting G or utilizing a pre-made dataset, which is important. TR0N is a zero-shot approach, with a lightweight translation network as the only trainable part. TR0N’s ability to employ any G and any f also makes upgrading any of these components easy whenever a newer state-of-the-art version becomes available. This is important since it avoids the extremely expensive training of a conditional model from scratch.
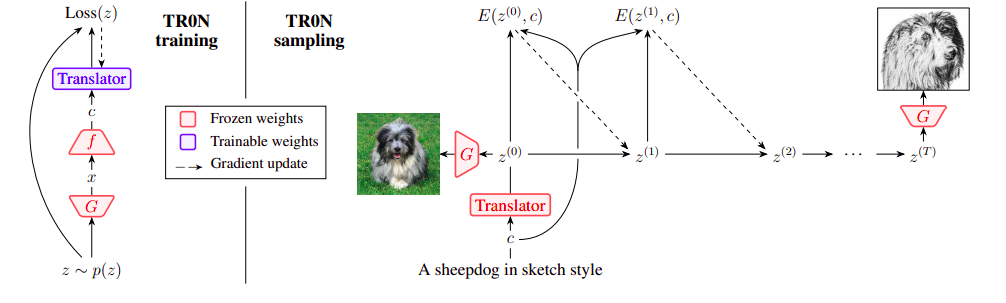
On the left panel of Figure 1, they describe how to train the translator network. After the translation network has been trained, the optimization of E is started using its output. Compared to naive initialization, this recovers any lost performance owing to the amortization gap, producing better local optima and faster convergence. It is possible to interpret TR0N as sampling with Langevin dynamics using an effective initialization strategy because TR0N is a stochastic method. The translator network is a conditional distribution q(z|c) that assigns high density to latents z so that E(z, c) is small. They also add noise during the gradient optimization of E. On the right panel of Figure 1, they demonstrate how to sample with TR0N.
They make three contributions: (i) introducing translator networks and a particularly effective parameterization of them, allowing for different ways to initialize Langevin dynamics; (ii) framing TR0N as a highly general framework, whereas previous related works primarily focus on a single task with specific choices of G and f; and (iii) demonstrating that TR0N empirically outperforms competing alternatives across tasks in image quality and computational tractability, while producing diverse samples. A demo is available on HuggingFace.
Check out the Paper and Demo. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.