Meet VampNet: A Masked Acoustic Token Modeling Approach to Music Synthesis, Compression, Inpainting, and Variation
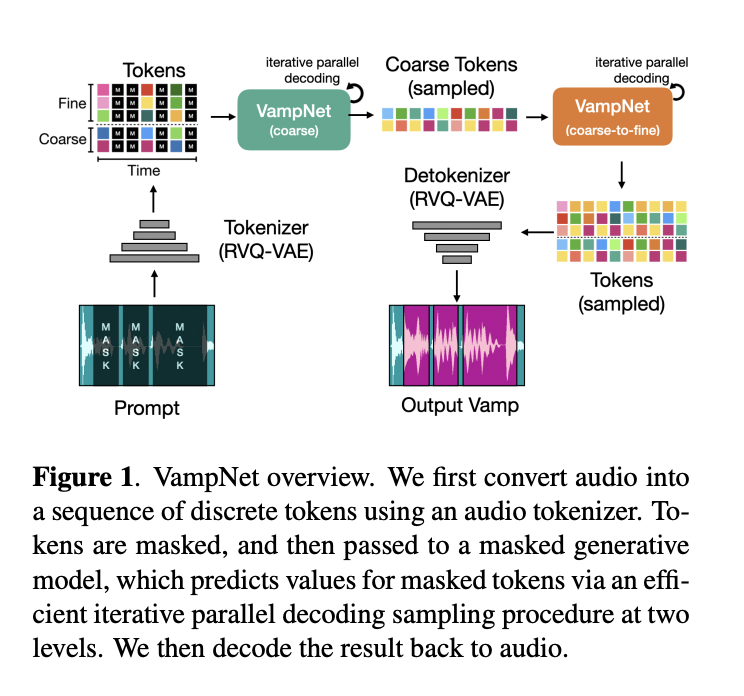
Significant improvements in the autoregressive creation of speech and music have recently been made due to discrete acoustic token modeling developments. For effective picture creation, non-autoregressive parallel iterative decoding methods have been devised. Infill jobs like these, which call for conditioning on both past and future sequence components, are better suited to parallel iterative decoding than autoregressive approaches. In this study, they utilize acoustic token modeling and simultaneous iterative decoding to music audio synthesis. To the best of their knowledge, theirs is the first use of parallel iterative decoding to neural audio music synthesis.
They use token-based prompting to adapt their model, known as VampNet, to a wide range of applications. With deliberately concealed music token sequences, they demonstrate their ability to direct VampNet’s creation and instruct it to fill in the blanks. The results of this process might be anything from a high-quality audio compression method to variants on the original input music that closely resembles it in terms of style, genre, beat, and instrumentation while changing some nuances of timbre and rhythm. Their method allows the prompts to be put anywhere, unlike auto-regressive music models, which can only execute music continuations by utilizing some prefix audio as a prompt and having the model produce music that may follow it.

They investigate various prompt designs, such as periodic, compression, and ones inspired by music (such as masking on the beat). They discover that their model performs admirably when instructed to create loops and variations; therefore, the name VampNet. They offer their code for download and strongly advise people to check out their audio samples. Researchers from Descript Inc. and Northwestern University introduced VampNet, a method for generating music using masked acoustic token modeling. An input audio file may prompt VampNet in various ways since it is bidirectional. VampNet is a great tool for creating variants on a piece of music since it can function in a continuum between music compression and production through various prompting approaches.
A musician might use VampNet to record a brief loop, input it into the system, and have VampNet come up with musical variants on the idea every time the looped area is repeated. They intend to study VampNet’s, and it is prompting approaches’ potential for interactive music co-creation in further work and the representation learning capabilities of masked acoustic token modeling.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.