Meet Video-ControlNet: A New Game-Changing Text-to-Video Diffusion Model Shaping the Future of Controllable Video Generation

In recent years, there has been a rapid development in text-based visual content generation. Trained with large-scale image-text pairs, current Text-to-Image (T2I) diffusion models have demonstrated an impressive ability to generate high-quality images based on user-provided text prompts. Success in image generation has also been extended to video generation. Some methods leverage T2I models to generate videos in a one-shot or zero-shot manner, while videos generated from these models are still inconsistent or lack variety. Scaling up video data, Text-to-Video (T2V) diffusion models can create consistent videos with text prompts. However, these models generate videos lacking control over the generated content.
A recent study proposes a T2V diffusion model that allows for depth maps as control. However, a large-scale dataset is required to achieve consistency and high quality, which is resource-unfriendly. Additionally, it’s still challenging for T2V diffusion models to generate videos of consistency, arbitrary length, and diversity.
Video-ControlNet, a controllable T2V model, has been introduced to address these issues. Video-ControlNet offers the following advantages: improved consistency through the use of motion priors and control maps, the ability to generate videos of arbitrary length by employing a first-frame conditioning strategy, domain generalization by transferring knowledge from images to videos, and resource efficiency with faster convergence using a limited batch size.
Video-ControlNet’s architecture is reported below.
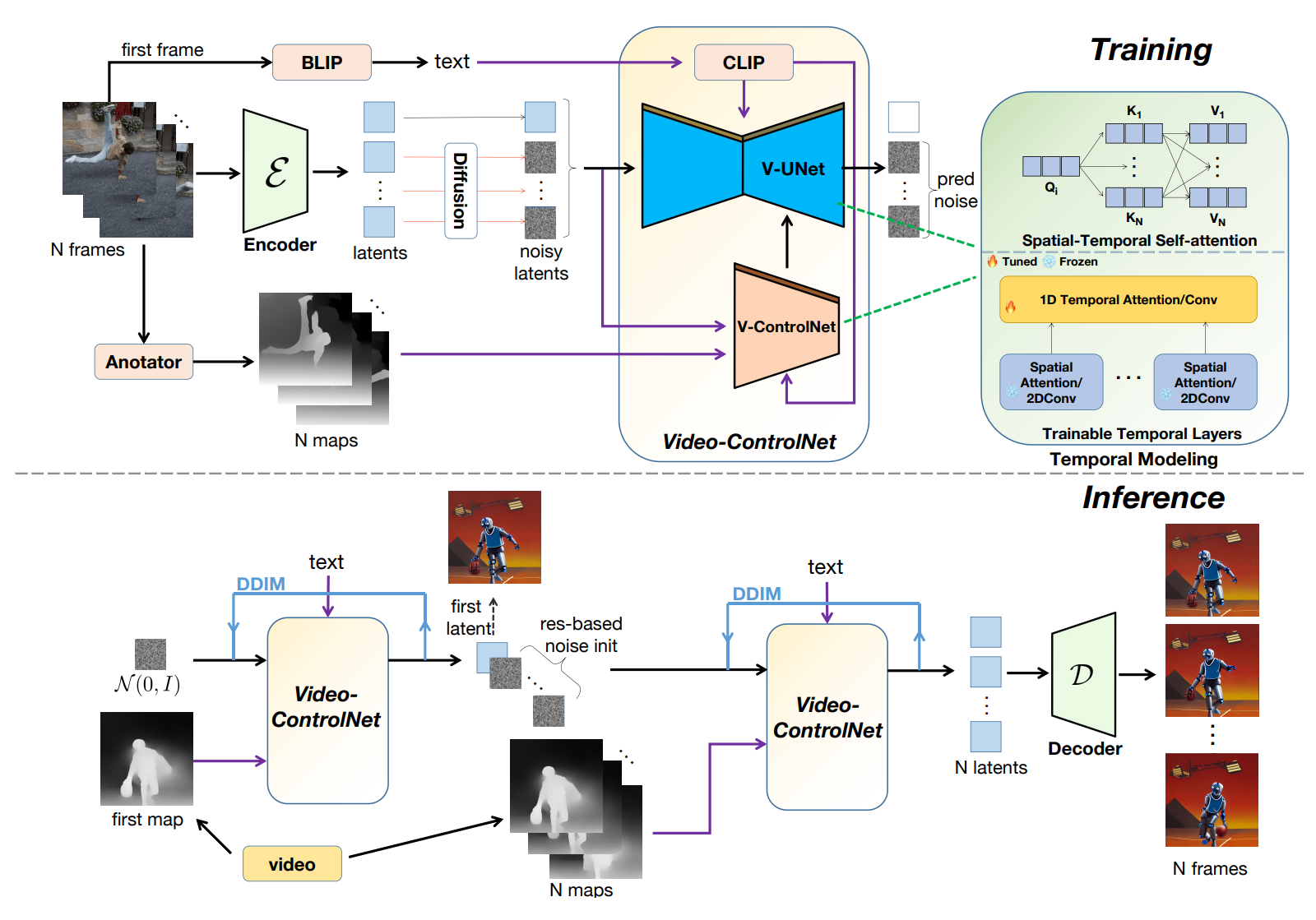

The goal is to generate videos based on text and reference control maps. Therefore, the generative model is developed by reorganizing a pre-trained controllable T2I model, incorporating additional trainable temporal layers, and presenting a spatial-temporal self-attention mechanism that facilitates fine-grained interactions between frames. This approach allows for the creation of content-consistent videos, even without extensive training.
To ensure video structure consistency, the authors propose a pioneering approach that incorporates the motion prior of the source video into the denoising process at the noise initialization stage. By leveraging motion prior and control maps, Video-ControlNet is able to produce videos that are less flickering and closely resemble motion changes in the input video while also avoiding error propagation in other motion-based methods due to the nature of the multi-step denoising process.
Furthermore, instead of previous methods that train models to directly generate entire videos, an innovative training scheme is introduced in this work, which produces videos predicated on the initial frame. With such a straightforward yet effective strategy, it becomes more manageable to disentangle content and temporal learning, as the former is presented in the first frame and the text prompt.
The model only needs to learn how to generate subsequent frames, inheriting generative capabilities from the image domain and easing the demand for video data. During inference, the first frame is generated conditioned on the control map of the first frame and a text prompt. Then, subsequent frames are generated, conditioned on the first frame, text, and subsequent control maps. Meanwhile, another benefit of such a strategy is that the model can auto-regressively generate an infinity-long video by treating the last frame of the previous iteration as the initial frame.
This is how it works. Let us take a look at the results reported by the authors. A limited batch of sample outcomes and comparison with state-of-the-art approaches is shown in the figure below.

This was the summary of Video-ControlNet, a novel diffusion model for T2V generation with state-of-the-art quality and temporal consistency. If you are interested, you can learn more about this technique in the links below.
Check Out The Paper. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.