Meet VideoChat: An End-to-End Chat-Centric Video Understanding System Developed by Merging Language and Visual Models
Real-world applications like autonomous driving and human-robot interaction rely heavily on intelligent visual understanding. Current video comprehension methods’ spatial and temporal interpretations do not successfully generalize and instead rely on task-specific fine-tuning of video foundation models. Due to the task-specific tailoring of pre-trained video foundation models, the existing video understanding paradigm needs to be expanded in its ability to provide a general spatiotemporal understanding of client-level needs. Recent years have seen the emergence of vision-centric multimodal discourse systems as a crucial study area. These systems may conduct image-related activities through multi-round dialogues with user inquiries by leveraging a pre-trained large language model (LLM), an image encoder, and extra learnable modules. This changes the game for various uses, but current solutions need to properly approach video-centric problems from a data-centric viewpoint using machine learning.
Researchers from the Shanghai AI Laboratory’s OpenGVLab, Nanjing University, the University of Hong Kong, the Shenzhen Institute of Advanced Technology, and the Chinese Academy of Sciences collaborated to create VideoChat. This innovative end-to-end chat-centric video understanding system employs state-of-the-art video and language models to enhance spatiotemporal reasoning, event localization, and causal relationship inference. The group developed a novel dataset containing thousands of videos and densely captioned descriptions and discussions given to ChatGPT chronologically. This dataset is useful for training video-centric multimodal discourse systems because of its focus on spatiotemporal objects, actions, events, and causal relationships.
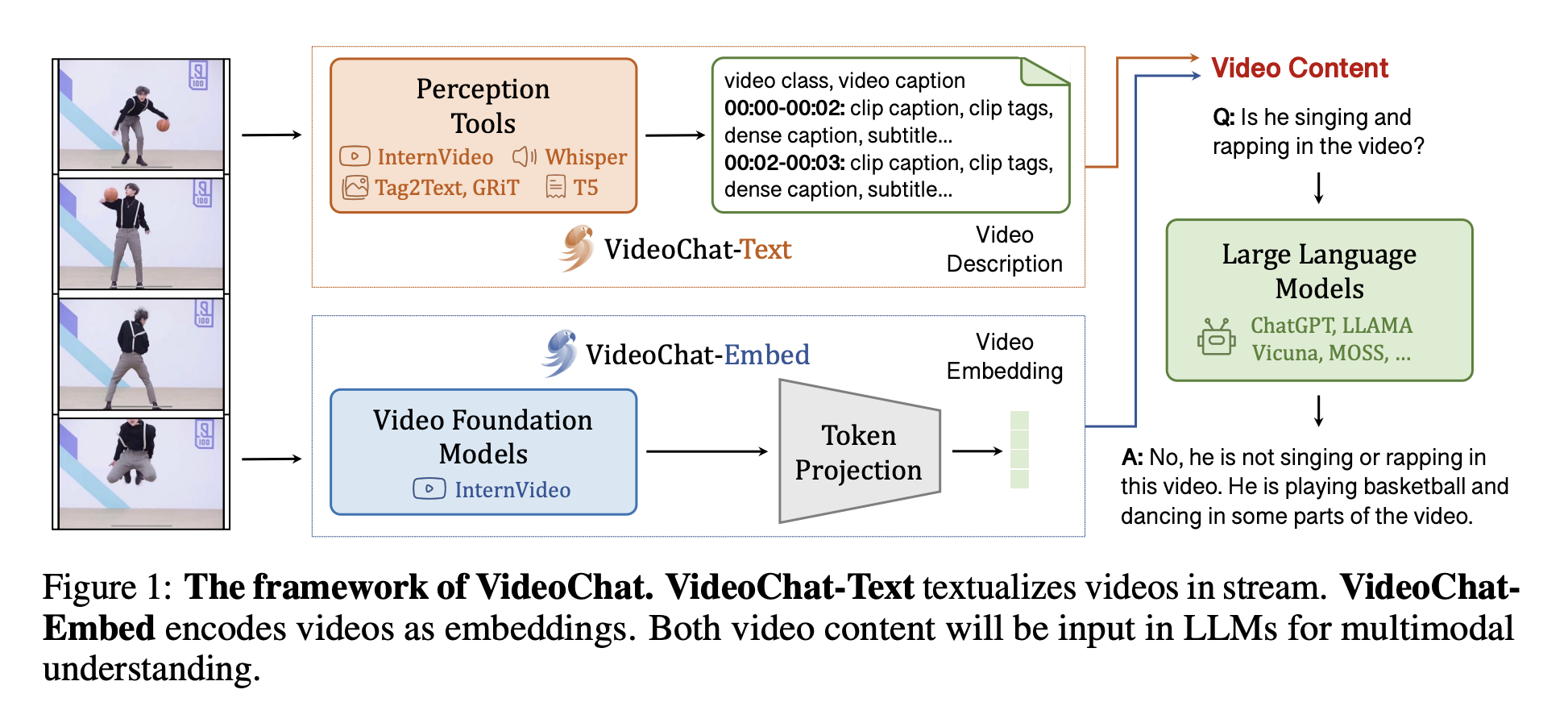
All of the methods required to develop the system from a data perspective are provided by the proposed VideoChat, which combines state-of-the-art video foundation models with LLMs in a learnable neural interface. The video and language foundation models are combined with a learnable video-language token interface (VLTF) tuned with video-text data to encode the videos as embeddings; these two processes make up the proposed framework. After that, an LLM is fed the video tokens, user inquiries, and dialogue context for talking.
The stack consists of a pre-trained vision transformer equipped with a global multi-head relation aggregator temporal modeling module and a pre-trained QFormer that serves as the token interface and features additional linear projection and query tokens. The generated video embeddings are tiny and LLM-compatible, making them useful for subsequent conversations. To fine-tune their system, the researchers also designed a video-centric instruction dataset consisting of thousands of videos matched with detailed descriptions and conversations and a two-stage joint training paradigm that uses publicly available image instruction data.
Researchers have begun a groundbreaking exploration of broad video comprehension by creating VideoChat, a multimodal discussion system optimized for videos. A text-based version of VideoChat shows how well big language models work as universal decoders for video jobs, and an end-to-end performance makes an initial attempt to solve the problem of video understanding using an instructed video-to-text formulation. All the pieces work together thanks to a neural interface that can be trained to combine video foundation models with huge language models successfully. Researchers have presented a video-centric instructional dataset to boost the system’s performance. The dataset emphasizes spatiotemporal reasoning and causality and is a learning resource for video-based multimodal dialogue systems. Early qualitative assessments demonstrate the system’s potential across various video applications and motivate its continued development.
Challenges and Constraints
- Long-form videos (> 1 minute) are difficult to manage in both VideoChat-Text and VideoChat-Embed. On the one hand, further investigation is still needed into how to model the context of long videos efficiently and effectively. Conversely, it might be difficult to provide user-friendly interactions when processing lengthier films due to balancing response time, GPU memory utilization, and user expectations for system performance.
- Temporal and causal reasoning abilities are still in their infancy in the system. The current magnitude of the instruction data and the methods utilized to produce it impose these limitations on the system and the models employed.
- Egocentric task instruction prediction and intelligent monitoring are examples of time-sensitive and performance-critical applications where addressing performance gaps is a continuing problem.
The group’s goal is to pave the path for various real-world applications in multiple fields by advancing the integration of video and natural language processing for video understanding and reasoning. Future focus, according to the team:
- Improving video foundation models’ spatiotemporal modeling requires expanding their capacity and data.
- Multimodal training data and reasoning benchmark with a focus on video for large-scale assessments.
- Methods of processing videos for the long haul.
Check out the Paper and Github link. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.