Meet VidProM: Pioneering the Future of Text-to-Video Diffusion with a Groundbreaking Dataset

Text-to-video diffusion models are transforming how individuals create and interact with media. These sophisticated algorithms can craft compelling, high-definition videos from simple text descriptions, bringing to life scenes that range from the serenely picturesque to the wildly imaginative. The potential for such technology is vast, spanning entertainment, education, and beyond. Yet, its advancement has yet to be hampered by a notable absence: a comprehensive dataset of text-to-video prompts.
The field has leaned heavily on datasets geared towards text-to-image generation, limiting the scope and depth of video content that could be produced. This gap restricted the creative potential of diffusion models and posed significant challenges in evaluating and refining these complex systems.
A research team from the University of Technology Sydney and Zhejiang University has introduced VidProM, a large-scale dataset comprising text-to-video prompts from real users. This pioneering dataset includes over 1.67 million unique prompts collected from real user interactions and 6.69 million videos generated by state-of-the-art diffusion models. VidProM is a treasure for researchers, offering a rich, diverse foundation for exploring the intricacies of video generation.
VidProM’s significance dataset embodies a spectrum of human creativity, with prompts that capture everything from the mundane to the magical. Its creation involved meticulous curation and classification, ensuring a breadth of content that reflects the complexity and dynamism of real-world interests and narratives. For instance, prompts leading to the generation of videos range from enchanting forest adventures in the style of animated classics to futuristic cityscapes patrolled by dragons, showcasing the dataset’s versatility in catering to a wide array of thematic preferences.
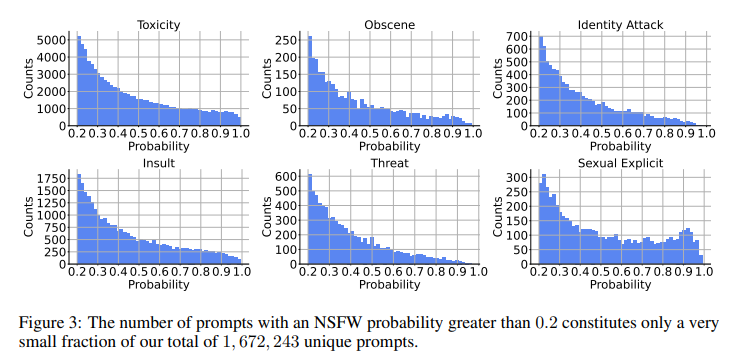
VidProM empowers researchers to facilitate the exploration of new methodologies for prompt engineering, improve the efficiency of video generation processes, and develop robust mechanisms to ensure the integrity and authenticity of produced content. Moreover, VidProM’s public availability under a Creative Commons license democratizes access to these resources, encouraging a collaborative approach to tackling the challenges and seizing the opportunities presented by text-to-video diffusion models.

VidProM’s impact extends beyond the technical achievements of compiling such a dataset. Bridging a critical gap in available resources sets the stage for a wave of innovation that could redefine the capabilities of text-to-video diffusion models. Researchers can now delve deeper into understanding how different prompts influence video generation, uncover patterns in user preferences, and develop models that can more accurately and effectively translate textual descriptions into visual narratives.
In conclusion, VidProM is a great dataset for the future of multimedia content creation. It underscores the importance of having targeted resources specifically designed to advance the state of the art in digital technology. VidProM offers a glimpse into a future where stories can be visualized as vividly as imagined.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.