Meet VisionGPT-3D: Merging Leading Vision Models for 3D Reconstruction from 2D Images
The transition from text to visual components has significantly enhanced daily tasks, from generating images and videos to identifying elements within them. Past computer vision models focused on object detection and classification, while large language models like OpenAI GPT-4 have bridged the gap between natural language and visual representations. Despite advancements, converting text into vivid visual contexts remains challenging for AI. Although GPT-4 and models like SORA have set impressive benchmarks, the evolving landscape of multimodal computer vision offers vast potential for innovation and refinement in generating 3D visual components from 2D images.
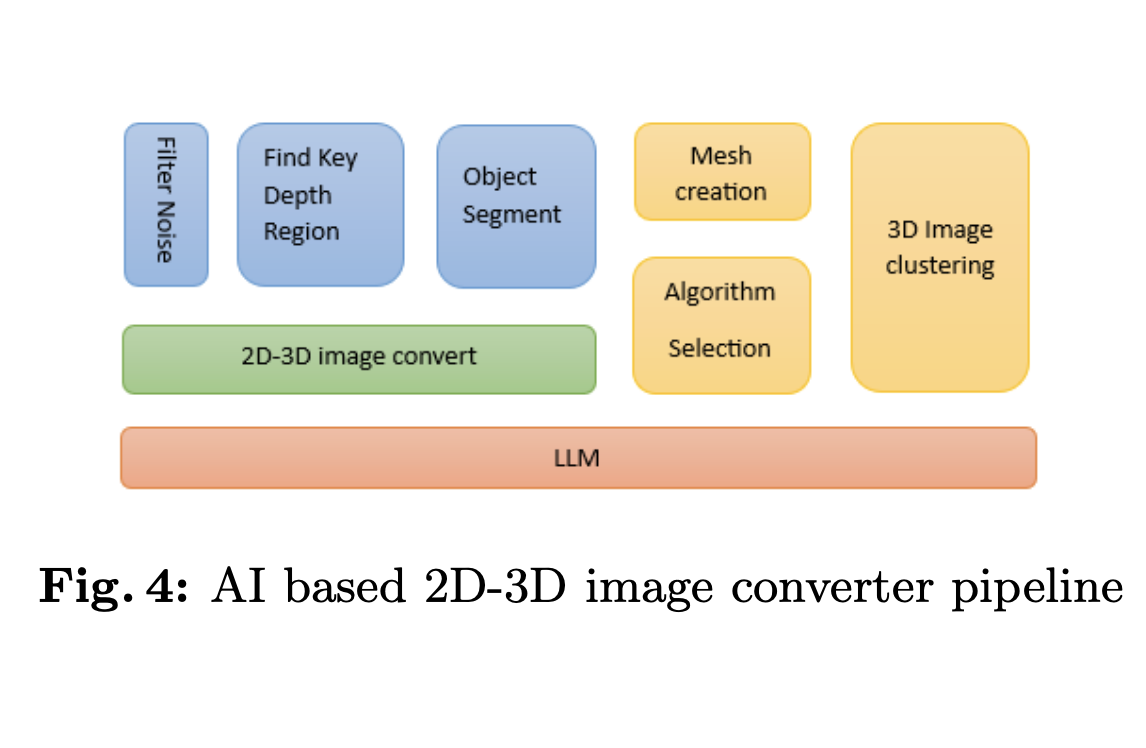
Researchers from Stanford University, Seeking AI, University of California, Los Angeles, Harvard University, Peking University, and the University of Washington, Seattle, have created VisionGPT-3D, a comprehensive framework to consolidate cutting-edge vision models. VisionGPT-3D leverages a range of state-of-the-art vision models like SAM, YOLO, and DINO, seamlessly integrating their strengths to automate model selection and optimize results for diverse multimodal inputs. It focuses on tasks like reconstructing 3D images from 2D representations, employing multi-view stereo, structure from motion, depth from stereo, and photometric stereo. The implementation involves depth map extraction, point cloud creation, mesh generation, and video synthesis.
The study outlines several crucial steps to generate a comprehensive VisionGPT-3D framework. Initially, the process begins with generating depth maps, which provide essential distance information for objects within a scene through disparity analysis or neural network estimation methods like MiDas. The subsequent creation of a point cloud from the depth map involves intricate steps such as identifying key depth regions, object boundaries, noise filtering, and surface normal computation, all aimed at accurately representing the scene’s geometry in a 3D space. Object segmentation within the depth map is emphasized, employing various algorithms such as thresholding, watershed segmentation, and mean-shift clustering to efficiently delineate objects within the scene and enable selective manipulation and collision avoidance.

Following the point cloud generation, the methodology progresses to mesh creation, where algorithms like Delaunay triangulation and surface reconstruction techniques are employed to form a surface representation from the point cloud. The choice of algorithms is guided by analyzing the scene’s characteristics, ensuring adaptability to varying curvatures and preservation of sharp features. Validation of the generated mesh is paramount, utilizing methods like surface deviation analysis and volume conservation to ensure accuracy and fidelity to the underlying geometry. Lastly, the process concludes with generating videos from static frames, incorporating object placement, collision detection, and movement based on real-time analysis and physical laws. Validation of the generated videos ensures color accuracy, frame rate consistency, and overall fidelity to the intended visual representation, which is crucial for effective communication and user satisfaction.

The VisionGPT-3D framework integrates various state-of-the-art vision models and algorithms to facilitate the development of vision-oriented AI. The framework automates the selection of SOTA vision models and identifies suitable 3D mesh creation algorithms based on 2D depth map analysis. It generates optimal results using diverse multimodal inputs such as text prompts. The researchers mention an AI-based approach to select object segmentation algorithms based on image characteristics, improving segmentation efficiency and correctness. The correctness of mesh generation algorithms is validated using 3D visualization tools and the VisionGPT-3D model.
In conclusion, the unified VisionGPT-3D framework integrates AI models and traditional vision processing methods to optimize mesh creation and depth map analysis algorithms, catering to users’ specific requirements. The framework trains models to select the most suitable algorithms at each stage of 3D reconstruction from 2D images. However, limitations arise in non-GPU environments due to unavailability or low performance of certain libraries. To address this, researchers aim to enhance efficiency and prediction precision by optimizing algorithms based on a self-designed, low-cost generalized chipset, thereby reducing training costs and improving overall performance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
Want to get in front of 1.5 Million AI enthusiasts? Work with us here
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.