Meet vLLM: An Open-Source Machine Learning Library for Fast LLM Inference and Serving
Large language models (LLMs) have an ever-greater impact on how daily lives and careers are changing because they make possible new applications like programming assistants and universal chatbots. However, the operation of these applications comes at a substantial cost due to the significant hardware accelerator requirements, such as GPUs. Recent studies show that handling an LLM request can be expensive, up to ten times higher than a traditional keyword search. So, there is a growing need to boost the throughput of LLM serving systems to minimize the per-request expenses.
Performing high throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time and the existing systems.
However, existing systems need help because the key-value cache (KV cache) memory for each request is huge and can grow and shrink dynamically. It needs to be managed carefully, or when managed inefficiently, fragmentation and redundant duplication can greatly save this RAM, reducing the batch size.
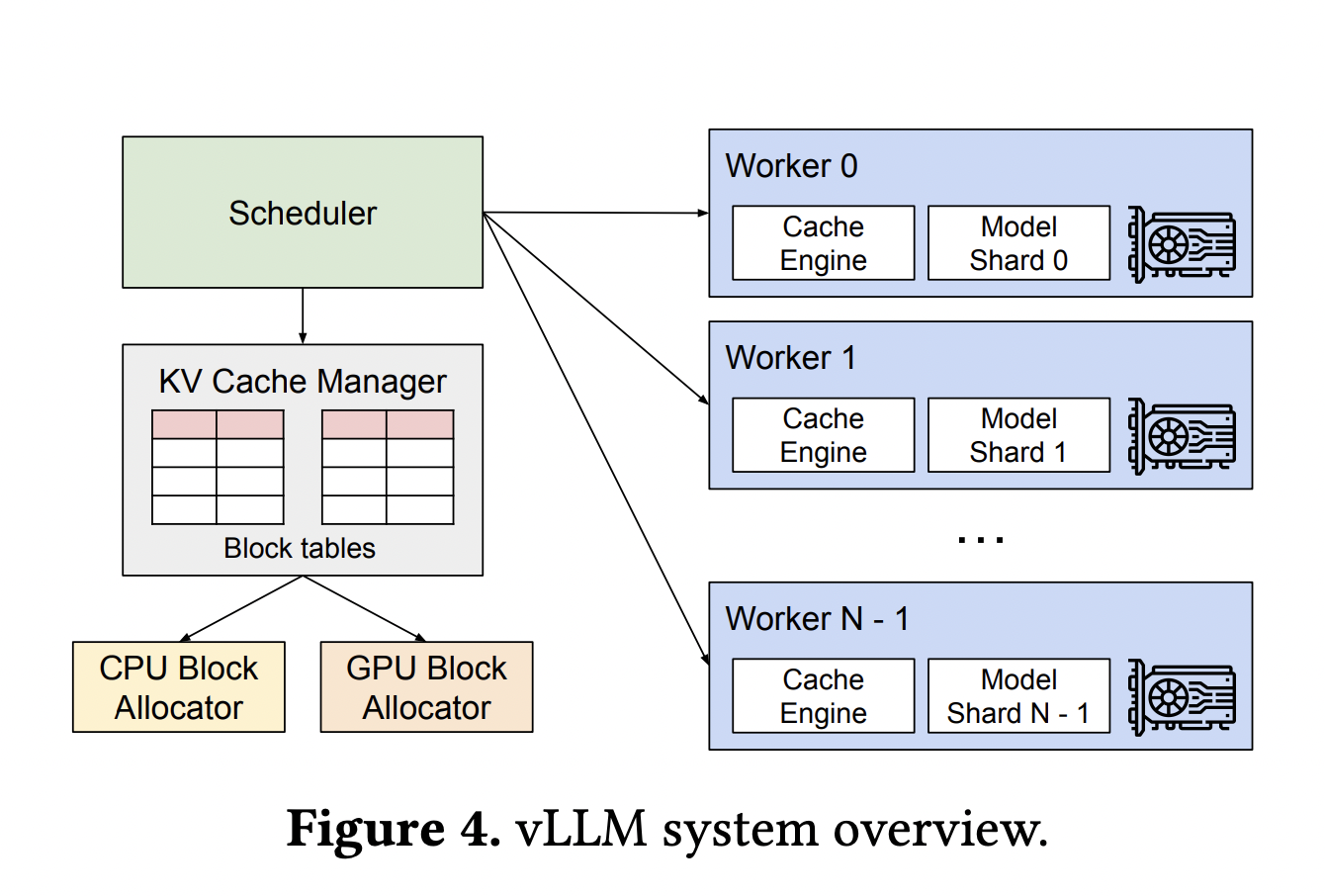
The researchers have suggested PagedAttention, an attention algorithm inspired by the traditional virtual memory and paging techniques in operating systems, as a solution to this problem. To further reduce memory utilization, the researchers have also deployed vLLM. This LLM serving system provides almost zero waste in KV cache memory and flexible sharing of KV cache within and between requests.
vLLM utilizes PagedAttention to manage attention keys and values. By delivering up to 24 times more throughput than HuggingFace Transformers without requiring any changes to the model architecture, vLLM equipped with PagedAttention redefines the current state of the art in LLM serving.
Unlike conventional attention algorithms, they permit continuous key and value storage in non-contiguous memory space. PagedAttention divides each sequence’s KV cache into blocks, each with the keys and values for a predetermined amount of tokens. These blocks are efficiently identified by the PagedAttention kernel during the attention computation. As the blocks do not necessarily need to be contiguous, the keys and values can be managed flexibly.
Memory leakage happens only in the ultimate block of a sequence within PagedAttention. In practical usage, this leads to effective memory utilization, with just a minimal 4% inefficiency. This enhancement in memory efficiency enables greater GPU utilization.
Also, PagedAttention has another key advantage of efficient memory sharing. PageAttention’s memory-sharing function considerably decreases the additional memory required for sampling techniques like parallel sampling and beam search. It can result in a speed gain of up to 2.2 times while reducing their memory utilization by up to 55%. This enhancement makes these sample techniques useful and effective for Large Language Model (LLM) services.
The researchers studied the accuracy of this system. They found that with the same amount of delay as cutting-edge systems like FasterTransformer and Orca, vLLM increases the throughput of well-known LLMs by 2-4. Larger models, more intricate decoding algorithms, and longer sequences result in a more noticeable improvement.
Check out the Paper, Github, and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.