Meet Wanda: A Simple and Effective Pruning Approach for Large Language Models
The popularity and usage of Large Language Models (LLMs) are constantly booming. With the enormous success in the field of Generative Artificial Intelligence, these models are leading to some massive economic and societal transformations. One of the best examples of the trending LLMs is the chatbot developed by OpenAI, called ChatGPT, which imitates humans and has had millions of users since its release. Built on Natural Language Processing and Natural Language Understanding, it answers questions, generates unique and creative content, summarizes lengthy texts, completes codes and emails, and so on.
LLMs with a huge number of parameters demand a lot of computational power, to reduce which efforts have been made by using methods like model quantization and network pruning. While model quantization is a process that reduces the bit-level representation of parameters in LLMs, network pruning, on the other hand, seeks to reduce the size of neural networks by removing particular weights, thereby putting them to zero. The lack of focus on pruning LLMs is mainly due to the hefty computational resources required for retraining, training from scratch, or iterative processes in current approaches.
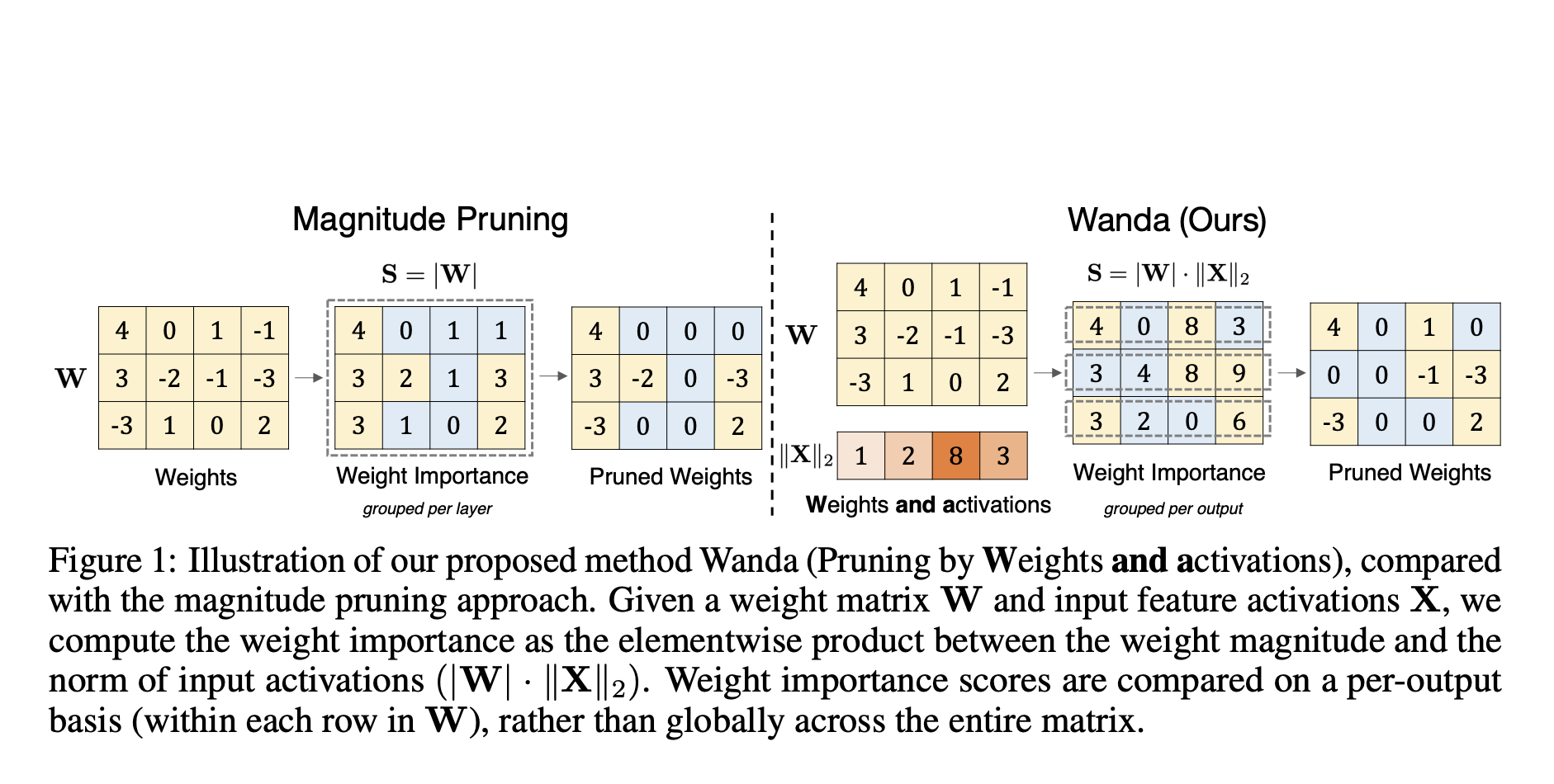
To overcome the limitations, researchers from Carnegie Mellon University, FAIR, Meta AI, and Bosch Center for AI have proposed a pruning method called Wanda (pruning by Weights AND Activations). Inspired by the research that LLMs display emergent large-magnitude features, Wanda induces sparsity in pretrained LLMs without the need for retraining or weight updates. The smallest magnitude weights in Wanda are pruned based on how they multiply with the appropriate input activations, and weights are assessed independently for each model output because this pruning is done on an output-by-output basis.
Wanda works well without needing to be retrained or get its weights updated, and the reduced LLM has been applied to inference immediately. The study found that a tiny fraction of LLMs’ hidden state features has unusually large magnitudes, which is a peculiar characteristic of these models. Building on this finding, the team discovered that adding input activations to the conventional weight magnitude pruning metric makes assessing weight importance surprisingly accurate.
The most successful open-sourced LLM family, LLaMA, has been used by the team to empirically evaluate Wanda. The results demonstrated that Wanda could successfully identify efficient sparse networks directly from pretrained LLMs without the need for retraining or weight updates. It outperformed magnitude pruning by a significant margin while requiring lower computational cost and also matched or surpassed the performance of SparseGPT, a recently proposed LLM pruning method that works accurately on massive GPT-family models.
In conclusion, Wanda seems like a promising approach for addressing the challenges of pruning LLMs and offers a baseline for future research in this area by encouraging further exploration into understanding sparsity in LLMs. By improving the efficiency and accessibility of LLMs through pruning techniques, advancement in the field of Natural Language Processing can be continued, and these powerful models can become more practical and widely applicable.
Check out the Paper and Github Link. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.