Meet XTREME-UP: A Benchmark for Evaluating Multilingual Models with Scarce Data Evaluation, Focusing on Under-Represented Languages
The fields of Artificial Intelligence and Machine Learning are solely dependent upon data. Everyone is deluged with data from different sources like social media, healthcare, finance, etc., and this data is of great use to applications involving Natural Language Processing. But even with so much data, readily usable data is scarce for training an NLP model for a particular task. Finding high-quality data with usefulness and good-quality filters is a difficult task. Specifically talking about developing NLP models for different languages, the lack of data for most languages comes as a limitation that hinders progress in NLP for under-represented languages (ULs).
The emerging tasks like news summarization, sentiment analysis, question answering, or the development of a virtual assistant all heavily rely on data availability in high-resource languages. These tasks are dependent upon technologies like language identification, automatic speech recognition (ASR), or optical character recognition (OCR), which are mostly unavailable for under-represented languages, to overcome which it is important to build datasets and evaluate models on tasks that would be beneficial for UL speakers.
Recently, a team of researchers from GoogleAI has proposed a benchmark called XTREME-UP (Under-Represented and User-Centric with Paucal Data) that evaluates multilingual models on user-centric tasks in a few-shot learning setting. It primarily focuses on activities that technology users often perform in their day-to-day lives, such as information access and input/output activities that enable other technologies. The three main features that distinguish XTREME-UP are – its use of scarce data, its user-centric design, and its focus on under-represented languages.
With XTREME-UP, the researchers have introduced a standardized multilingual in-language fine-tuning setting in place of the conventional cross-lingual zero-shot option. This method considers the amount of data that can be generated or annotated in an 8-hour period for a particular language, thus aiming to give the ULs a more useful evaluation setup.
XTREME-UP assesses the performance of language models across 88 under-represented languages in 9 significant user-centric technologies, some of which include Automatic Speech Recognition (ASR), Optical Character Recognition (OCR), Machine Translation (MT), and information access tasks that have general utility. The researchers have developed new datasets specifically for operations like OCR, autocomplete, semantic parsing, and transliteration in order to evaluate the capabilities of the language models. They have also improved and polished the currently existing datasets for other tasks in the same benchmark.
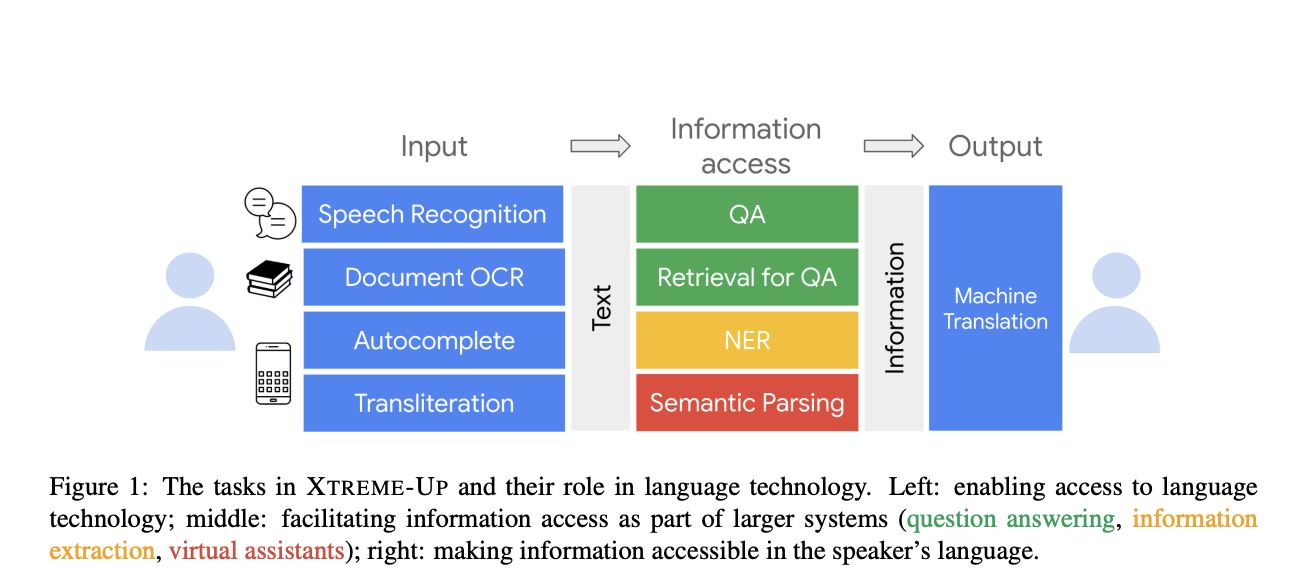
XTREME-UP has one of its key abilities to assess various modeling situations, including both text-only and multi-modal scenarios with visual, audio, and text inputs. It also offers methods for supervised parameter adjustment and in-context learning, allowing for a thorough assessment of various modeling approaches. The tasks in XTREME-UP involve enabling access to language technology, enabling information access as part of a larger system such as question answering, information extraction, and virtual assistants, followed by making information accessible in the speaker’s language.
Consequently, XTREME-UP is a great benchmark that addresses the data scarcity challenge in highly multilingual NLP systems. It is a standardized evaluation framework for under-represented language and seems really useful for future NLP research and developments.
Check out the Paper and Github. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.