Meet xVal: A Continuous Way to Encode Numbers in Language Models for Scientific Applications that Uses Just a Single Token to Represent any Number
In the realm of Large Language Models, one perplexing problem stands out. While these models can master many language-based tasks, they often stumble when performing numerical calculations involving large numbers. Specifically, multiplying two four-digit numbers results in a success rate of just over 90%, leaving room for improvement.
This issue stems from the inherent differences between numbers and other forms of language. Unlike letters or words, numbers encompass a continuous spectrum of values, subject to intricate and strict rules. This challenge has raised questions about the intersection of language models and numerical data and has inspired the quest for a solution.
The existing solutions to this problem are few and far from perfect. LLMs, which excel in language-related tasks, struggle to adapt to numbers’ continuous and infinitely variable nature. Most approaches involve tokenization, where numbers are broken into multiple tokens, increasing model complexity and memory requirements.
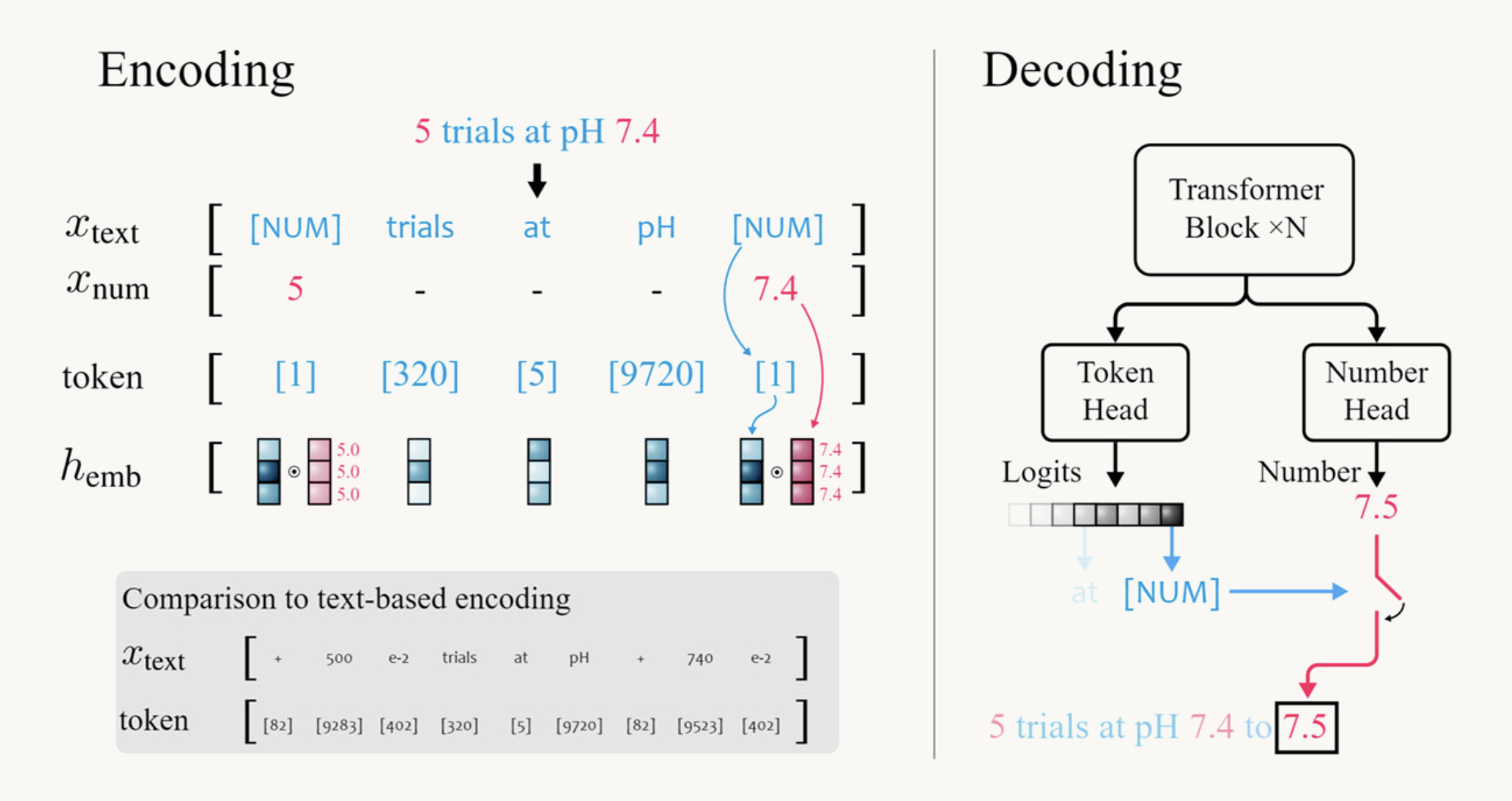
Polymathic AI researchers introduce a potential game-changer: the xVal encoding strategy. This innovative approach offers a fresh perspective on encoding numbers in LLMs for scientific applications. xVal employs a singular token labeled as [NUM] to represent any number.
The xVal strategy achieves this by treating numbers differently in the language model. Instead of relying on multiple tokens, each number is pre-processed and stored in a separate vector. The text replaces the number with the [NUM] token. During decoding, a dedicated token head in the transformer architecture is employed to predict the value associated with the [NUM] token, using Mean Squared Error (MSE) loss as the guiding metric.
In a series of experiments, xVal’s capabilities were rigorously tested and compared with four other numerical encoding strategies. The results were intriguing. xVal outshone other methods on multi-operand tasks and performed comparably in complex calculations, such as multiplying large multi-digit integers.
When applied to temperature readings from the ERA5 global climate dataset, xVal’s inherent continuity bias allowed it to excel, achieving the best performance in minimal training time.
Planetary Simulations revealed xVal’s exceptional interpolation abilities in simulations of planets orbiting a central mass, surpassing all other encoding schemes when making predictions for out-of-distribution data.
In conclusion, xVal’s innovative approach to encoding numbers in language models holds the potential to revolutionize the future. Addressing the challenge of representing numbers in LLMs with a more efficient and accurate method opens the door to innovative applications in the scientific realm. This groundbreaking solution may pave the way for the development of foundation models that connect multiple domains of science, ultimately reshaping the landscape of scientific inquiry in the years to come.
Check out the Reference Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.